


| –§–æ—Ä—É–º –Ý–∞–¥–∏–æ–ö–æ—Ç https://radiokot.ru/forum/ |
|
| –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 https://radiokot.ru/forum/viewtopic.php?f=59&t=94614 |
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 1 –∏–∑ 1 |
| –ê–≤—Ç–æ—Ä: | uk8amk [ –ß—Ç —Å–µ–Ω 19, 2013 13:18:48 ] | ||
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 | ||
–û–ø–∏—Å–∞–Ω–∏–µ –º–æ–∏—Ö —ç–∫—Å–ø–µ—Ä–∏–º–µ–Ω—Ç–æ–≤ –ø–æ —Å–æ–∑–¥–∞–Ω–∏—é –ø—Ä–æ—Å—Ç–æ–≥–æ —Ñ–æ–Ω–µ–º–Ω–æ–≥–æ —Å–∏–Ω—Ç–µ–∑–∞—Ç–æ—Ä–∞ —Ä–µ—á–∏ –Ω–∞ –º–∏–∫—Ä–æ–∫–æ–Ω—Ç—Ä–æ–ª–ª–µ—Ä–µ. –ë—ã–ª–æ –∂–µ–ª–∞–Ω–∏–µ –æ—Ñ–æ—Ä–º–∏—Ç—å –≤ –≤–∏–¥–µ —Å—Ç–∞—Ç—å–∏ –Ω–∞ —Å–∞–π—Ç, –Ω–æ —Ç–∞–∫ –∏ –Ω–µ –æ—Å–∏–ª–∏–ª –ö–æ—Ç–æ-—Ä–µ–¥–∞–∫—Ç–æ—Ä. –ü–æ—ç—Ç–æ–º—É –∫–ª–∞–¥—É –∑–¥–µ—Å—å –≤ PDF. –ù–∞–¥–µ—é—Å—å, —á—Ç–æ –∫–æ–º—É-—Ç–æ –æ–∫–∞–∂–µ—Ç—Å—è –ø–æ–ª–µ–∑–Ω—ã–º. –°—Ö–µ–º—ã, –ø–ª–∞—Ç—ã, –∏—Å—Ö–æ–¥–Ω–∏–∫–∏ —Å –ø—Ä–æ—à–∏–≤–∫–∞–º–∏ –ª–µ–∂–∞—Ç –Ω–∞ –Ø–Ω–¥–µ–∫—Å –î–∏—Å–∫–µ: http://yadi.sk/d/H-2kJlg39XgwW
|
|||
| –ê–≤—Ç–æ—Ä: | oleg110592 [ –ß—Ç —Å–µ–Ω 19, 2013 17:24:55 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
—Å–ø–∞—Å–∏–±–æ - –æ—á–µ–Ω—å –∏–Ω—Ç–µ—Ä–µ—Å–Ω–æ |
|
| –ê–≤—Ç–æ—Ä: | uk8amk [ –ü—Ç —Å–µ–Ω 20, 2013 08:19:43 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–¢–∞–º —Å—Ä–µ–¥–∏ —Ñ–∞–π–ª–æ–≤ –µ—Å—Ç—å –æ–±—Ä–∞–∑–µ—Ü –∑–∞–ø–∏—Å–∏ –≤ MP3. –•–æ—Ç–µ–ª–æ—Å—å –±—ã —É–∑–Ω–∞—Ç—å –≤–∞—à–∏ –º–Ω–µ–Ω–∏—è, –Ω–∞—Å–∫–æ–ª—å–∫–æ –ø–æ–Ω—è—Ç–Ω–æ –æ–Ω–æ —Ä–∞–∑–≥–æ–≤–∞—Ä–∏–≤–∞–µ—Ç. –°–∞–º —è —É–∂–µ –ø—Ä–∏—Å–ª—É—à–∞–ª—Å—è –∏ –Ω–µ –º–æ–≥—É –¥–∞—Ç—å –æ–±—ä–µ–∫—Ç–∏–≤–Ω—É—é –æ—Ü–µ–Ω–∫—É —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞. |
|
| –ê–≤—Ç–æ—Ä: | uk8amk [ –ü—Ç —Å–µ–Ω 20, 2013 09:03:10 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–ö—Å—Ç–∞—Ç–∏ —ç—Ç–æ –Ω–µ –µ–¥–∏–Ω—Å—Ç–≤–µ–Ω–Ω–æ –≤–æ–∑–º–æ–∂–Ω—ã–π –≤–∞—Ä–∏–∞–Ω—Ç —Å–∏–Ω—Ç–µ–∑–∞—Ç–æ—Ä–∞. –ù–µ–¥–∞–≤–Ω–æ –º–Ω–µ –ø–æ–ø–∞–¥–∞–ª–∏—Å—å –ø—Ä–æ—Å—Ç—ã–µ TTS –Ω–∞ AVR 8-–±–∏—Ç –º–∏–∫—Ä–æ–∫–æ–Ω—Ç—Ä–æ–ª–ª–µ—Ä–∞—Ö: - Atmega8 http://bascom.at.ua/publ/sintezator_rec ... a/1-1-0-79 - Atmega32 http://roboforum.ru/forum2/topic5106.html |
|
| –ê–≤—Ç–æ—Ä: | urry [ –ü—Ç —Å–µ–Ω 20, 2013 10:00:04 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–∏–º—Ö–æ, —Ö–æ—Ç–µ–ª–æ—Å—å –±—ã –ø–æ–ª—É—á—à–µ. –ö—Å—Ç–∞—Ç–∏, –∞ –ø–æ—á–µ–º—É –í—ã –Ω–µ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–ª–∏ –≤ –∫–∞—á–µ—Å—Ç–≤–µ –≤–Ω–µ—à–Ω–µ–π –ø–∞–º—è—Ç–∏ –º–º—Å —Å–¥ –∫–∞—Ä—Ç–æ—á–∫—É ? –¢–æ–≥–¥–∞ —Ä–∞–∑–º–µ—Ä –±–∏–±–ª–∏–æ—Ç–µ–∫–∏ —Ñ–æ–Ω–µ–º –º–æ–∂–Ω–æ –±—ã–ª–æ –±—ã —Ä–∞—Å—à–∏—Ä–∏—Ç—å. –ö—Ä–∞—Å–∏–≤–æ, –∫–æ–Ω–µ—á–Ω–æ, –Ω–æ –ø—Ä–∞–∫—Ç–∏—á–µ—Å–∫–æ–µ –ø—Ä–∏–º–µ–Ω–µ–Ω–∏–µ –≤—Ä—è–¥ –ª–∏ –Ω–∞–π–¥–µ—Ç - –≥–æ–≤–æ—Ä–∏–ª–∫–∞ —Å –≥–æ—Ç–æ–≤—ã–º–∏ —Ñ—Ä–∞–∑–∞–º–∏ —É–∂–µ –µ—Å—Ç—å... –ù—É –∏–º—Ö–æ. |
|
| –ê–≤—Ç–æ—Ä: | oleg110592 [ –ü—Ç —Å–µ–Ω 20, 2013 10:22:36 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
uk8amk –ø–∏—Å–∞–ª(–∞): –•–æ—Ç–µ–ª–æ—Å—å –±—ã —É–∑–Ω–∞—Ç—å –≤–∞—à–∏ –º–Ω–µ–Ω–∏—è, –Ω–∞—Å–∫–æ–ª—å–∫–æ –ø–æ–Ω—è—Ç–Ω–æ –æ–Ω–æ —Ä–∞–∑–≥–æ–≤–∞—Ä–∏–≤–∞–µ—Ç... –ø–∞—Ä—É —Å–ª–æ–≤ –Ω–µ —Å–æ–≤—Å–µ–º —Ä–∞–∑–±–æ—Ä—á–∏–≤–æ, –∞ —Ç–∞–∫ –≤–ø–æ–ª–Ω–µ, –∏–º—Ö–æ –±—ã –ø—Ä–∏—è—Ç–Ω–µ–µ –±—ã–ª –±—ã –∂–µ–Ω—Å–∫–∏–π –≥–æ–ª–æ—Å (–∏–Ω–æ–≥–¥–∞ –∫–æ–≥–¥–∞ –≥–ª–∞–∑–∞ —É—Å—Ç–∞—é—Ç —Å–ª—É—à–∞—é –∫–Ω–∏–∂–∫–∏ –Ω–∞ –ø–ª–∞–Ω—à–µ—Ç–µ - —Å–∏–Ω—Ç–µ–∑–∏—Ä–æ–≤–∞–Ω–Ω—ã–π –≥–æ–ª–æ—Å –ê–ª–µ–Ω–∞ –≤–ø–æ–ª–Ω–µ –Ω–µ–ø–ª–æ—Ö). –ù–∞—Å—á–µ—Ç –∫–∞—Ä—Ç–æ—á–∫–∏ - –Ω–∞–≤–µ—Ä–Ω–æ–µ –º–æ–∂–Ω–æ –±—ã–ª–æ –±—ã —Ä–∞–∑–º–µ—Å—Ç–∏—Ç—å –≤—Å–µ –Ω—É–∂–Ω—ã–µ –∂–∏–≤—ã–µ —Ñ—Ä–∞–∑—ã –Ω–∞ –Ω–µ–π, –µ—Å–ª–∏ –∫–æ–Ω–µ—á–Ω–æ –Ω–µ —á–∏—Ç–∞–ª–∫–∞ —Ç–µ–∫—Å—Ç–∞. |
|
| –ê–≤—Ç–æ—Ä: | uk8amk [ –ü—Ç —Å–µ–Ω 20, 2013 12:40:39 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–î–∞, –≤—ã –ø—Ä–∞–≤—ã –Ω–∞—Å—á—ë—Ç –ø—Ä–∏–º–µ–Ω–µ–Ω–∏—è. –î–ª—è –º–µ–Ω—è —ç—Ç–∞ —Ç–µ–º–∞ —Å–µ–π—á–∞—Å –ø—Ä–µ–¥—Å—Ç–∞–≤–ª—è–µ—Ç —á–∏—Å—Ç–æ —Å–ø–æ—Ä—Ç–∏–≤–Ω—ã–π –∏–Ω—Ç–µ—Ä–µ—Å. –ü—Ä–æ MMC - —ç—Ç–æ –æ—Ç–¥–µ–ª—å–Ω—ã–π —Ä–∞–∑–≥–æ–≤–æ—Ä. –ú–æ–∂–µ—Ç —è –Ω–µ —É–º–µ—é –∏—Ö –≥–æ—Ç–æ–≤–∏—Ç—å, –Ω–æ –±—ã–ª–æ –Ω–µ—Å–∫–æ–ª—å–∫–æ —Å–ª—É—á–∞–µ–≤ –ø–æ–ª–Ω–æ–≥–æ –∑–∞–≤–∏—Å–∞–Ω–∏—è –∫–∞—Ä—Ç–æ—á–µ–∫(–¥–æ —Ä–µ–∑–µ—Ç–∞ –ø–∏—Ç–∞–Ω–∏—è). –ò–∑ —á–µ–≥–æ —è –¥–µ–ª–∞—é –≤—ã–≤–æ–¥ –æ –∏—Ö –Ω–µ–≤—ã—Å–æ–∫–æ–π –Ω–∞–¥—ë–∂–Ω–æ—Å—Ç–∏ –≤ —Ä–µ–∂–∏–º–µ SPI. –î–ª—è —É–≤–µ–ª–∏—á–µ–Ω–∏—è –±–∞–∑—ã –¥—É–º–∞—é –∑–∞—é–∑–∞—Ç—å M25P128 –Ω–∞ 16 –º–µ–≥–∞–±–∞–π—Ç –∏–ª–∏ NAND flash –æ—Ç Samsung-a –∫–∞–∫ –Ω–µ–¥–æ—Ä–æ–≥–æ–π –≤–∞—Ä–∏–∞–Ω—Ç. –ù–æ NAND –º–Ω–µ –Ω–µ –æ—á–µ–Ω—å –Ω—Ä–∞–≤–∏—Ç—Å—è —Ç.–∫. —É –Ω–µ–≥–æ –ø–∞—Ä–∞–ª–ª–µ–ª—å–Ω–∞—è —à–∏–Ω–∞. –ê –¥–ª—è –±—ã—Å—Ç—Ä–æ–≥–æ –ø—Ä–æ–∑—Ä–∞—á–Ω–æ–≥–æ –æ–±–º–µ–Ω–∞ –Ω—É–∂–µ–Ω FSMC, —á—Ç–æ –µ—Å—Ç—å –≤ –∫–∞–º–Ω—è—Ö –æ—Ç LQFP100 –∏ –≤—ã—à–µ. –ü–æ –≥–æ–ª–æ—Å–∞–º. –ê–ª—ë–Ω–∞ –≤—Ä–æ–¥–µ –∫–æ–º–º–µ—Ä—á–µ—Å–∫–∞—è. –ù–∞—à—ë–ª –∏ —Å–∫–∞—á–∞–ª —Ç–æ–ª—å–∫–æ –û–ª—å–≥—É. –ù–æ –æ–Ω–∞ –±–µ–∑ –Ω–∞—Ä–µ–∑–∫–∏ –ø–æ –∞–ª–ª–æ—Ñ–æ–Ω–∞–º. –ê –≤—Ä—É—á–Ω—É—é –ø—Ä–æ—Å—Ç–∞–≤–ª—è—Ç—å –º–∞—Ä–∫–µ—Ä—ã - –ø–∞—Ä—É –º–µ—Å—è—Ü–µ–≤ —Ä–∞–±–æ—Ç—ã. –ò–º–µ–µ—Ç—Å—è –º—É–∂—Å–∫–æ–π –≥–æ–ª–æ—Å —Å —Ä–∞–∑–º–µ—Ç–∫–æ–π –æ—Ç TTS Festival(–∏–º—è –¥–∏–∫—Ç–æ—Ä–∞ –Ω–µ –∑–Ω–∞—é). –ù–æ —Ç–∞–º —Ç–æ–∂–µ —Å–≤–æ–∏ –∑–∞–º–æ—Ä–æ—á–∫–∏. –î–∏–∫—Ç–æ—Ä –≤—Å—ë —Ä–∞–≤–Ω–æ —á–∏—Ç–∞–µ—Ç —Å –∏–Ω—Ç–æ–Ω–∞—Ü–∏–µ–π. –£ –º–µ–Ω—è –∂–µ —Å–∏—Å—Ç–µ–º–∞, –∫–∞–∫ —Å–µ–π—á–∞—Å –µ—Å—Ç—å, –Ω–µ —É—á–∏—Ç—ã–≤–∞–µ—Ç –ø—Ä–æ—Å–æ–¥–∏—á–µ—Å–∫–∏–µ —Ö–∞—Ä–∞–∫—Ç–µ—Ä–∏—Å—Ç–∏–∫–∏. –í–æ–±—â–µ–º –µ—Å—Ç—å –Ω–∞–¥ —á–µ–º –≥–æ–ª–æ–≤—É –ø–æ–ª–æ–º–∞—Ç—å. |
|
| –ê–≤—Ç–æ—Ä: | balmer [ –ü—Ç —Å–µ–Ω 20, 2013 14:46:16 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
uk8amk –ø–∏—Å–∞–ª(–∞): –°–∞–º —è —É–∂–µ –ø—Ä–∏—Å–ª—É—à–∞–ª—Å—è –∏ –Ω–µ –º–æ–≥—É –¥–∞—Ç—å –æ–±—ä–µ–∫—Ç–∏–≤–Ω—É—é –æ—Ü–µ–Ω–∫—É —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞. –õ–∏—á–Ω–æ –º–Ω–µ –Ω–µ –Ω—Ä–∞–≤—è—Ç—Å—è —â–µ–ª—á–∫–∏ –º–µ–∂–¥—É —Å–ª–æ–≥–∞–º–∏. –ù–æ –∫ —Å–æ–∂–∞–ª–µ–Ω–∏—é –Ω–µ –∑–Ω–∞—é - —ç—Ç–æ –∏—Å—Ö–æ–¥–Ω–æ–µ —Å–≤–æ–π—Å—Ç–≤–æ –∑–≤—É–∫–æ–≤ –∏–∑ –∫–æ—Ç–æ—Ä—ã—Ö —Å–∏–Ω—Ç–µ–∑–∏—Ä—É–µ—Ç—Å—è –∏–ª–∏ –º–∏–∫—à–µ—Ä–µ –ø–æ–ª—É—á–∞–µ—Ç—Å—è? |
|
| –ê–≤—Ç–æ—Ä: | oleg110592 [ –ü—Ç —Å–µ–Ω 20, 2013 15:01:53 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–ê–ª–µ–Ω–∞ —Ç—É—Ç –≤—Ä–æ–¥–µ –µ—Å—Ç—å http://rsload.net/soft/document/8298-balabolka.html –ø—Ä–∏–º–µ–Ω–∏—Ç—å –º–æ–∂–Ω–æ - –¥–∞–≤–Ω–æ –º–µ–Ω—è –æ–¥–∏–Ω –∑–∞–∫–∞–∑—á–∏–∫ –º–æ—Ä–¥—É–µ—Ç —Å–¥–µ–ª–∞—Ç—å –±—ã—Ç–æ–≤–æ–π —Ç–µ—Ä–º–æ–º–µ—Ç—Ä + –≤–ª–∞–∂–Ω–æ—Å—Ç—å —Å –≥–æ–ª–æ—Å–æ–º (—Ç–æ–ª—å–∫–æ –¥–µ–Ω–µ–≥ –≤–∫–ª–∞–¥—ã–≤–∞—Ç—å –Ω–µ —Ö–æ—á–µ—Ç), –¥–∞ –µ—â–µ –º–æ–∂–Ω–æ –Ω–∞–ø—Ä–∏–¥—É–º—ã–≤–∞—Ç—å - –Ω–∞–ø—Ä–∏–º–µ—Ä –≤—ã–∫–ª—é—á–∞—Ç–µ–ª—å —Å–≤–µ—Ç–∞ —Å –≥–æ–ª–æ—Å–æ–º –∏ —Ç.–¥., –ª–∏—à—å –±—ã –≤–Ω—è—Ç–Ω–æ –±—ã–ª–æ. –∑.—ã. –≤—Ä–æ–¥–µ –ø–æ —Ç–µ–º–µ —è–ø–æ–Ω—Å–∫–∏–π –≤–æ–∫–∞–ª–æ–∏–¥ –ø–æ —Ä—É—Å—Å–∫–∏: http://www.youtube.com/watch?v=XhQUJgRGRdQ |
|
| –ê–≤—Ç–æ—Ä: | uk8amk [ –°–± —Å–µ–Ω 21, 2013 10:04:12 ] | ||
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 | ||
–°–ø–∞—Å–∏–±–æ –∑–∞ –æ—Ç–∑—ã–≤—ã. –î–∞, –∑–∞–±—ã–ª —Å–∫–∞–∑–∞—Ç—å. –ó–∞–ø–∏—Å—å –æ—Ä–∞–∑—Ü–∞ MP3 —Å –¥–µ—à—ë–≤–æ–≥–æ –º–∏–∫—Ä–æ—Ñ–æ–Ω–∞, –ø–æ—ç—Ç–æ–º—É –∑–≤—É–∫ –±–æ–ª–µ–µ –∂–µ—Å—Ç–∫–∏–π. –ù–æ –Ω–∞–≤–µ—Ä–Ω–æ–µ –≤—ã —É–∂–µ –∏ —Ç–∞–∫ –¥–æ–≥–∞–¥–∞–ª–∏—Å—å. –ò–∑–ª–æ–º —Ç–æ–Ω–∞ –≤ —Å–ª–æ–≤–∞—Ö –ø—Ä–æ—Ö–æ–¥–∏—Ç –ø–æ –≥—Ä–∞–Ω–∏—Ü–∞–º –∑–≤—É–∫–æ–≤ –∏–∑ —Ñ–æ–Ω–µ–º–Ω–æ–π –±–∞–∑—ã(—Ç–∞–º —ç–ª–µ–º–µ–Ω—Ç—ã —Ä–∞–∑–ª–∏—á–Ω–æ–π –¥–ª–∏–Ω—ã - –∞–ª–ª–æ—Ñ–æ–Ω—ã, –¥–∏—Ñ–æ–Ω—ã –∏ —Ç—Ä–∏—Ñ–æ–Ω—ã). –Ø –ø—Ä–æ—á–∏—Ç–∞–ª –≤ –æ–¥–Ω–æ–π —Å–æ–≤–µ—Ç—Å–∫–æ–π –∫–Ω–∏–∂–∫–µ, —á—Ç–æ –¥–ª—è –±–æ–ª–µ–µ –∏–ª–∏ –º–µ–Ω–µ–µ —Å–Ω–æ—Å–Ω–æ–≥–æ —Å–∏–Ω—Ç–µ–∑–∞ —Ä—É—Å—Å–∫–æ–≥–æ —è–∑—ã–∫–∞ –Ω–µ–æ–±—Ö–æ–¥–∏–º–æ –∏–º–µ—Ç—å –∫–∞–∫ –º–∏–Ω–∏–º—É–º 10000 —Ä–∞–∑–Ω—ã—Ö –∞–ª–ª–æ—Ñ–æ–Ω–æ–≤. –î–µ–ª–æ –≤ —Ç–æ–º, —á—Ç–æ –≤ –Ω–µ–ø—Ä–µ—Ä—ã–≤–Ω–æ–π —Ä–µ—á–∏ –∑–≤—É–∫–∏ –ø–µ—Ä–µ—Ç–µ–∫–∞—é—Ç –ø–ª–∞–≤–Ω–æ –æ–¥–∏–Ω –≤ –¥—Ä—É–≥–æ–π. –ò –µ—Å–ª–∏ –±–∞–∑–∞ –Ω–µ–¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ –±–æ–ª—å—à–∞—è, —Ç–æ –Ω–µ –ø–æ–ª—É—á–∏—Ç—Å—è —Å–æ—Å—Ç—ã–∫–æ–≤–∞—Ç—å –∑–≤—É–∫–∏ –±–µ–∑ —Ä–∞–∑—Ä—ã–≤–∞ —Ñ–æ—Ä–º–∞–Ω—Ç. –°–µ–π—á–∞—Å —É –º–µ–Ω—è 680 —ç–ª–µ–º–µ–Ω—Ç–æ–≤ –∏ —Ç–∞–∫–∏–µ —Ä–∞–∑—Ä—ã–≤—ã –Ω–µ–∏–∑–±–µ–∂–Ω—ã. –í–æ—Ç –∫–∞–∫ —Ä–∞–∑ —Ö–æ—Ä–æ—à–æ –≤–∏–¥–Ω–æ –Ω–∞ —Å–æ–Ω–æ–≥—Ä–∞–º–º–µ. 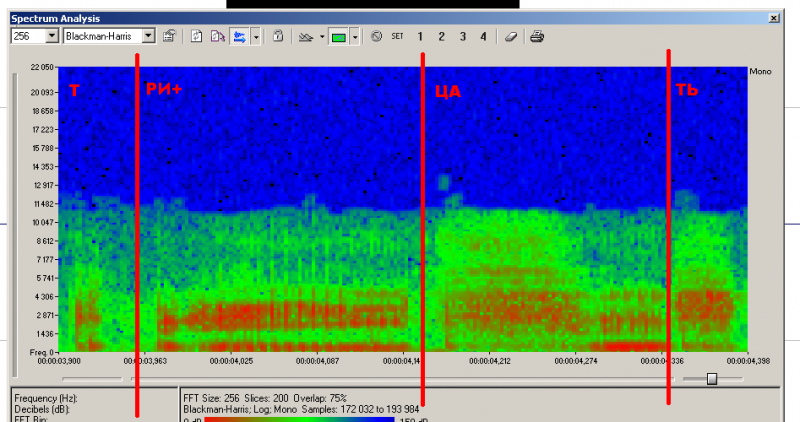 –í–æ "–≤–∑—Ä–æ—Å–ª—ã—Ö" —Å–∏—Å—Ç–µ–º–∞—Ö —Å–∏–Ω—Ç–µ–∑–∞ –∏—Å–ø–æ–ª—å–∑—É—é—Ç—Å—è –∞–ª–≥–æ—Ä–∏—Ç–º—ã –¥–ª—è —Å–≥–ª–∞–∂–∏–≤–∞–Ω–∏—è —Ä–∞–∑—Ä—ã–≤–æ–≤. –£ –º–µ–Ω—è –∂–µ —Å–µ–π—á–∞—Å –≤–æ–ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç—Å—è –∫–∞–∫ –µ—Å—Ç—å, –±–µ–∑ –∫–∞–∫–æ–π-–ª–∏–±–æ –¥–æ–ø–æ–ª–Ω–∏—Ç–µ–ª—å–Ω–æ–π –æ–±—Ä–∞–±–æ—Ç–∫–∏. –ù—É –∏ —Å —É—á—ë—Ç–æ–º –Ω–µ–±–æ–ª—å—à–∏—Ö –≤—ã—á–∏—Å–ª–∏—Ç–µ–ª—å–Ω—ã—Ö –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç–µ–π —è –º–æ–≥—É –º–∞–∫—Å–∏–º—É–º –æ—Å–∏–ª–∏—Ç—å –ø–ª–∞–≤–Ω—É—é —Å–∫–ª–µ–π–∫—É –∑–≤—É–∫–æ–≤ –≤–Ω–∞—Ö–ª—ë—Å—Ç(—Å –ø–ª–∞–≤–Ω—ã–º –Ω–∞–µ–∑–¥–æ–º-–≤—ã–µ–∑–¥–æ–º). –ù–∞–¥–æ –±—É–¥–µ—Ç –∫–∞–∫-–Ω–∏–±—É–¥—å –ø–æ–ø—Ä–æ–±–æ–≤–∞—Ç—å —ç—Ç–æ—Ç –≤–∞—Ä–∏–∞–Ω—Ç. –ü—Ä–æ –ø—Ä–æ—Å—Ç—ã–µ –¥–µ–≤–∞–π—Å—ã –≤—Ä–æ–¥–µ —Ç–µ—Ä–º–æ–º–µ—Ç—Ä–∞. –í –ø–ª–∞–Ω–µ –∫–∞—á–µ—Å—Ç–≤–∞ –¥–µ–π—Å—Ç–≤–∏—Ç–µ–ª—å–Ω–æ –±—É–¥–µ—Ç –ª—É—á—à–µ –∑–∞–ø–∏—Å–∞—Ç—å –¥–µ—Å—è—Ç–æ–∫ –æ—Ç–¥–µ–ª—å–Ω—ã—Ö —Å–ª–æ–≤, –∑–∞—Ç–µ–º –∏–∑ –Ω–∏—Ö –∫–æ–º–ø–∏–ª–∏—Ä–æ–≤–∞—Ç—å —Ñ—Ä–∞–∑—ã. –ö–∞–∫ –Ω–∞–ø—Ä–∏–º–µ—Ä —ç—Ç–æ —Å–¥–µ–ª–∞–Ω–æ –∑–¥–µ—Å—å http://radiokot.ru/circuit/digital/home/118/ –ê –µ—Å–ª–∏ –ø—Ä–∏–º–µ–Ω–∏—Ç—å —Å–∂–∞—Ç–∏–µ –∑–≤—É–∫–∞ –∏ –∫–æ–Ω—Ç—Ä–æ–ª–ª–µ—Ä —Å –¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ –±–æ–ª—å—à–∏–º –æ–±—ä—ë–º–æ–º –ø–∞–º—è—Ç–∏(256 –∏ –±–æ–ª–µ–µ –ö–ë), —Ç–æ –≤–ø–æ–ª–Ω–µ –º–æ–∂–µ—Ç –ø–æ–ª—É—á–∏—Ç—å—Å—è –æ–¥–Ω–æ—á–∏–ø–æ–≤–æ–µ —Ä–µ—à–µ–Ω–∏–µ. –ê –ø—Ä–æ –∑–∞–∫–∞–∑—á–∏–∫–æ–≤ - –ø—Ä–∞–≤–¥–∞. –ü–æ—à—ë–ª —Å–µ–π—á–∞—Å –Ω–∞—Ä–æ–¥ –ª–∏–±–æ –±–µ–¥–Ω—ã–π, –ª–∏–±–æ –∂–∞–¥–Ω—ã–π. –ß–µ–º –ª–µ—á–∏—Ç—å —Ç–∞–∫–æ–µ - –Ω–µ –∑–Ω–∞—é:) –í—á–µ—Ä–∞ –ø–æ–ø–∞–ª—Å—è –µ—â–µ –æ–¥–∏–Ω –∏–Ω—Ç–µ—Ä–µ—Å–Ω—ã–π –≤–∞—Ä–∏–∞–Ω—Ç –ø—Ä–æ—Å—Ç–µ–Ω—å–∫–æ–≥–æ —Å–∏–Ω—Ç–µ–∑–∞—Ç–æ—Ä–∞ –Ω–∞ PIC16F628 –∏–∑ –∂—É—Ä–Ω–∞–ª–∞ Everyday Practical Electronics. –°—Ç–∞—Ç—å—è –≤–æ –≤–ª–æ–∂–µ–Ω–∏–∏.
|
|||
| –ê–≤—Ç–æ—Ä: | uk8amk [ –°—Ä –æ–∫—Ç 02, 2013 19:54:22 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–ó–∞–≤—ë–ª —Ä–µ—á–µ–≤–æ–π –¥–µ–∫–æ–¥–µ—Ä SPEEX –Ω–∞ –æ—Ç–ª–∞–¥–æ—á–Ω–æ–π –ø–ª–∞—Ç–µ STM32 VLDiscovery. –û–Ω –æ—Ç–Ω–æ—Å–∏—Ç—Å—è –∫ –∫–∞—Ç–µ–≥–æ—Ä–∏–∏ CELP –∏ –æ–±–µ—Å–ø–µ—á–∏–≤–∞–µ—Ç —Ö–æ—Ä–æ—à–∏–π –∫–æ—ç—Ñ—Ñ–∏—Ü–∏–µ–Ω—Ç —Å–∂–∞—Ç–∏—è (—Å–∫–æ—Ä–æ—Å—Ç—å –ø–æ—Ç–æ–∫–∞ 1-2 –∫–∏–ª–æ–±–∞–π—Ç–∞ –≤ —Å–µ–∫). –ó–∞ –æ—Å–Ω–æ–≤—É –±—ã–ª–∏ –≤–∑—è—Ç—ã –º–∞—Ç–µ—Ä–∏–∞–ª—ã: 1.–°—Ç–∞—Ç—å—è —Å Easyelectronics http://we.easyelectronics.ru/STM32/vosp ... speex.html 2.AN2812 Vocoder demonstration using a Speex audio codec on STM32F101xx and STM32F103xx microcontrollers -- –ø–æ—Ä—Ç —É–∑–∫–æ–ø–æ–ª–æ—Å–Ω–æ–≥–æ –≤–∞—Ä–∏–∞–Ω—Ç–∞(8–ö–ì—Ü) –Ω–∞ STM32. 3.AN0055 - Application Note. Speex Codec. –ü–æ—Ä—Ç –∫–æ–¥–µ–∫–∞ –ø–æ–¥ –∫–æ–Ω—Ç—Ä–æ–ª–ª–µ—Ä—ã EFM32 –æ—Ç Energy micro. –ö —Å–æ–∂–∞–ª–µ–Ω–∏—é –∏—Å—Ö–æ–¥–Ω–∏–∫–∏ –∫–æ–º–ø–ª–µ–∫—Ç—É—é—Ç—Å—è —Ç–æ–ª—å–∫–æ —Å–∫–æ–º–ø–∏–ª–∏—Ä–æ–≤–∞–Ω–Ω–æ–π –ª–∏–±–æ–π –∏ —Ç–æ–ª–∫—É –æ—Ç –Ω–∏—Ö –Ω–æ–ª—å —Ü–µ–ª—ã—Ö —Ö—Ä–µ–Ω –¥–µ—Å—è—Ç—ã—Ö. –ó–∞—Ç–æ –µ—Å—Ç—å —É—Ç–∏–ª–∏—Ç–∞ speexenc, –∫–æ–Ω–≤–µ—Ä—Ç–∏—Ä—É—é—â–∞—è –∑–≤—É–∫–æ–≤—ã–µ WAV-—á–∏–∫–∏ –≤ h-—Ñ–∞–π–ª—ã. –ö–æ—Ç–æ—Ä—ã–µ –ø–æ—Ç–æ–º –ª–µ–≥–∫–æ —Ü–µ–ø–ª—è—é—Ç—Å—è –∫–æ–º–ø–∏–ª—è—Ç–æ—Ä–æ–º. 4. www.speex.org - –¥–æ–º–∞—à–Ω—è—è —Å—Ç—Ä–∞–Ω–∏—Ü–∞ –∫–æ–¥–µ–∫–∞ —Å –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏–µ–π. –ò—Å—Ö–æ–¥–Ω–∏–∫–∏ –±—ã–ª–∏ –¥–æ–ø–∏–ª–µ–Ω—ã –¥–ª—è –ø–æ–¥–¥–µ—Ä–∂–∫–∏ —É–∑–∫–æ–ø–æ–ª–æ—Å–Ω–æ–≥–æ(NarrowBand 8–ö–ì—Ü) –∏ —à–∏—Ä–æ–∫–æ–ø–æ–ª–æ—Å–Ω–æ–≥–æ(WideBand 16KHz) —Ä–µ–∂–∏–º–æ–≤. –û–ø—Ç–∏–º–∏–∑–∏—Ä–æ–≤–∞–Ω—ã –ø–æ —Å–∫–æ—Ä–æ—Å—Ç–∏ –∑–∞–≥—Ä—É–∑–∫–∏ –±—É—Ñ–µ—Ä–æ–≤ —á–µ—Ä–µ–∑ DMA. –ü–æ Flash –ø–∞–º—è—Ç–∏ –¥–µ–∫–æ–¥–µ—Ä –∑–∞–Ω–∏–º–∞–µ—Ç –æ–∫–æ–ª–æ 30–ö–ë, RAM - –æ–∫–æ–ª–æ 5–ö–ë(–Ω–∞–¥–æ –Ω–∞—Å—Ç—Ä–æ–∏—Ç—å —Ç–∞–∫—É—é –±–æ–ª—å—à—É—é –∫—É—á—É —Ç.–∫. –∏–¥—ë—Ç –¥–∏–Ω–∞–º–∏—á–µ—Å–∫–æ–µ –≤—ã–¥–µ–ª–µ–Ω–∏–µ –ø–∞–º—è—Ç–∏). –î–ª—è —Ä–∞–±–æ—Ç—ã —Å—É–¥—è –ø–æ –æ–ø–∏—Å–∞–Ω–∏—è–º —Ç—Ä–µ–±—É–µ—Ç –º–∏–Ω–∏–º—É–º 8–ú–ì—Ü(–Ω–∏–∑–∫–∞—è —Ç–∞–∫—Ç–æ–≤–∞—è –º–Ω–æ–π –Ω–µ –ø—Ä–æ–≤–µ—Ä—è–ª–∞—Å—å). –û–≥—Ä–∞–Ω–∏—á–µ–Ω–∏—è –∏–ª–∏ –Ω–µ–¥–æ—Å—Ç–∞—Ç–∫–∏: -—Ç–æ–ª—å–∫–æ –¥–µ–∫–æ–¥–µ—Ä(–¥–ª—è —É–º–µ–Ω—å—à–µ–Ω–∏—è —Ä–∞–∑–º–µ—Ä–∞ –∫–æ–¥–µ—Ä –≤—ã—Ä–µ–∑–∞–Ω); -–≤ —É–∑–∫–æ–ø–æ–ª–æ—Å–Ω–æ–º —Ä–µ–∂–∏–º–µ –º–∏–Ω–∏–º–∞–ª—å–Ω–∞—è —Å–∫–æ—Ä–æ—Å—Ç—å –ø–æ—Ç–æ–∫–∞ 8 –∫–∏–ª–æ–±–∏—Ç(Quality=4); -—Ç–æ–ª—å–∫–æ –ø–æ—Å—Ç–æ—è–Ω–Ω—ã–π –±–∏—Ç—Ä–µ–π—Ç(CBR); -–∞—Ä–∏—Ñ–º–µ—Ç–∏–∫–∞ —Å —Ñ–∏–∫—Å–∏—Ä–æ–≤–∞–Ω–Ω–æ–π —Ç–æ—á–∫–æ–π. –ò –∫–∞–∫ —è –ø–æ–Ω—è–ª –ø—Ä–æ—Ü–µ–¥—É—Ä–∞ —É–º–Ω–æ–∂–µ–Ω–∏—è —Å–∏–≥–Ω–∞–ª–æ–≤ –≤–Ω–æ—Å–∏—Ç –Ω–µ–∫–æ—Ç–æ—Ä—É—é –æ—à–∏–±–∫—É. –≠—Ç–æ –ø—Ä–æ—è–≤–ª—è–µ—Ç—Å—è –≤ –Ω–µ–±–æ–ª—å—à–æ–º –∑–≤–æ–Ω–µ –≥–æ–ª–æ—Å–∞. –í —à–∏—Ä–æ–∫–æ–ø–æ–ª–æ—Å–Ω–æ–º —Ä–µ–∂–∏–º–µ –∑–≤–æ–Ω –ø–æ—á—Ç–∏ –Ω–µ –∑–∞–º–µ—Ç–µ–Ω.–í –ª—é–±–æ–º —Å–ª—É—á–∞–µ –ø—Ä–æ—Å—Ç–æ–π –§–ù–ß –Ω–∞ –≤—ã—Ö–æ–¥–µ –¶–ê–ü –ø–æ–º–æ–∂–µ—Ç —É–ª—É—á—à–∏—Ç—å –∑–≤—É–∫. –ü—Ä–∏–º–µ–Ω–µ–Ω–∏–µ. –ü–ª–∞–Ω–∏—Ä—É–µ—Ç—Å—è –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –≤ –º–æ—ë–º —Å–∏–Ω—Ç–µ–∑–∞—Ç–æ—Ä–µ. –¢–∞–∫–∂–µ –º–æ–∂–µ—Ç –±—ã—Ç—å –∏–Ω—Ç–µ—Ä–µ—Å–µ–Ω –≤ –ø—Ä–æ—Å—Ç—ã—Ö –∫–æ–Ω—Å—Ç—Ä—É–∫—Ü–∏—è—Ö –≤—Ä–æ–¥–µ –≥–æ–≤–æ—Ä—è—â–∏—Ö —á–∞—Å–æ–≤ –∫–∞–∫ –æ–¥–Ω–æ—á–∏–ø–æ–≤–æ–µ —Ä–µ—à–µ–Ω–∏–µ. –ò—Å—Ö–æ–¥–Ω–∏–∫–∏. –ü—Ä–æ–µ–∫—Ç –ø–æ–¥ KEIL MDK470. –í —Ñ–∞–π–ª–µ 'main.h' –≤—ã–±—Ä–∞—Ç—å —á–∞—Å—Ç–æ—Ç—É –¥–∏—Å–∫—Ä–µ—Ç–∏–∑–∞—Ü–∏–∏(8/16K) –∏ —Ä–∞–∑–º–µ—Ä –∫–æ–¥–∏—Ä–æ–≤–∞–Ω–Ω–æ–≥–æ –∫–∞–¥—Ä–∞ ENCODED_FRAME_SIZE, —Å–æ–æ—Ç–≤–µ—Ç—Å–≤—É—é—â–∏–µ –ø–∞—Ä–∞–º–µ—Ç—Ä–∞–º –≤—ã–±—Ä–∞–Ω–Ω–æ–≥–æ –∑–≤—É–∫–∞. –í —Ñ–∞–π–ª–µ 'main.c' —Ñ—É–Ω–∫—Ü–∏—è play_message() –≤–æ—Å–ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç –∑–≤—É–∫. –í –ø—Ä–æ–µ–∫—Ç –≤–∫–ª—é—á–µ–Ω—ã –≤–∞—Ä–∏–∞–Ω—Ç—ã –æ–¥–Ω–æ–≥–æ —Å–æ–æ–±—â–µ–Ω–∏—è —Å —Ä–∞–∑–Ω—ã–º —É—Ä–æ–≤–Ω–µ–º —Å–∂–∞—Ç–∏—è. –ó–≤—É–∫ —Å–Ω–∏–º–∞–µ—Ç—Å—è —Å –≤—ã—Ö–æ–¥–∞ –¶–ê–ü PA4. –ß–µ—Ä–µ–∑ –∫–æ–Ω–¥—ë—Ä –º–æ–∂–Ω–æ –ø–æ–¥–∫–ª—é—á–∏—Ç—å –≤—ã—Å–æ–∫–æ–æ–º–Ω—ã–π –¥–∏–Ω–∞–º–∏–∫ –∏–ª–∏ –Ω–∞—É—à–Ω–∏–∫–∏. –ï—Å—Ç—å –∏–¥–µ–π–∫–∞ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –æ–±–∞ –≤—ã—Ö–æ–¥–∞ –¶–ê–ü –≤ –ø—Ä–æ—Ç–∏–≤–æ—Ñ–∞–∑–Ω–æ–º —Ä–µ–∂–∏–º–µ –¥–ª—è —É–≤–µ–ª–∏—á–µ–Ω–∏—è –º–æ—â–Ω–æ—Å—Ç–∏, —ç—Ç–æ —á—Ç–æ–±—ã –æ—Ç–∫–∞–∑–∞—Ç—å—Å—è –æ—Ç –£–ù–ß. –ü—Ä–æ–µ–∫—Ç –¥–æ—Å—Ç—É–ø–µ–Ω –ø–æ —Å—Å—ã–ª–∫–µ: http://yadi.sk/d/Js5nb6jLAHd3x |
|
| –ê–≤—Ç–æ—Ä: | fedyasolder [ –í—Ç –Ω–æ—è 01, 2016 11:56:08 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–Ø –±—ã —Å–¥–µ–ª–∞–ª –Ω–µ —Ç–∞–∫. –ù–∞–≥–æ–≤–æ—Ä–∏–ª –≤—Å–µ –Ω–µ–æ–±—Ö–æ–¥–∏–º—ã–µ —Ñ—Ä–∞–∑—ã, –∞ –ø–æ—Ç–æ–º –ø–æ—Ä–µ–∑–∞–ª –ø–æ —Å–µ—Ä–µ–¥–∏–Ω–∞–º –≥–ª–∞—Å–Ω—ã—Ö. –¢–∞–∫–∏–º –æ–±—Ä–∞–∑–æ–º –ø—Ä–æ–±–ª–µ–º–∞ –ø–µ—Ä–µ—Ö–æ–¥–æ–≤ —Ä–µ—à–∞–µ—Ç—Å—è. –ù–æ –∑–∞–¥–∞—á–∞ —É –º–µ–Ω—è –æ–±—Ä–∞—Ç–Ω–∞—è, –∫–∞–∫ –∑–∞—Å—Ç–∞–≤–∏—Ç—å –º–µ–ª–∫–æ—Å—Ö–µ–º—É –ø—Ä–∏–Ω–∏–º–∞—Ç—å –º–æ—é –∫–æ–º–∞–Ω–¥—É (–Ω–µ–¥–µ–ª—é –±–æ—à–∫—É –ª–æ–º–∞—é). |
|
| –ê–≤—Ç–æ—Ä: | oleg110592 [ –í—Ç –Ω–æ—è 01, 2016 13:33:51 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–¶–∏—Ç–∞—Ç–∞: –∫–∞–∫ –∑–∞—Å—Ç–∞–≤–∏—Ç—å –º–µ–ª–∫–æ—Å—Ö–µ–º—É –ø—Ä–∏–Ω–∏–º–∞—Ç—å –º–æ—é –∫–æ–º–∞–Ω–¥—É —Å—Ç–∞—Ä–µ–Ω—å–∫–∞—è —Ç–µ–º–∞. –¢–∞–∫ –Ω–µ –ø–æ–π–¥–µ—Ç? https://geektimes.ru/post/257382/ |
|
| –ê–≤—Ç–æ—Ä: | fedyasolder [ –í—Ç –Ω–æ—è 01, 2016 13:38:57 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–≠—Ç–æ –¥–ª—è —Ü–µ–Ω—Ç—Ä–∞–ª–∏–∑–æ–≤–∞–Ω–Ω–æ–≥–æ —Ä–∞—Å–ø–æ–∑–Ω–∞–≤–∞–Ω–∏—è, –¥–æ—Ä–æ–≥–æ. –•–æ—á—É –Ω–∞ ATmega8 |
|
| –ê–≤—Ç–æ—Ä: | uk8amk [ –í—Ç –Ω–æ—è 01, 2016 14:22:53 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–î–ª—è –ø–æ–∫—Ä—ã—Ç–∏—è –±–æ–ª—å—à–µ–π —á–∞—Å—Ç–∏ —Ä—É—Å—Å–∫–æ–≥–æ —Å–ª–æ–≤–∞—Ä—è –Ω–µ–æ–±—Ö–æ–¥–∏–º–æ 4300 —Å–µ–≥–º–µ–Ω—Ç–æ–≤. –≠—Ç–æ –ø–æ –º–æ–∏–º –ø–æ–¥—Å—á—ë—Ç–∞–º –¥–∏—Ñ–æ–Ω–æ–≤. –ï—Å–ª–∏ —Ä–µ–∑–∞—Ç—å —Ç–æ–ª—å–∫–æ –ø–æ –≥–ª–∞—Å–Ω—ã–º, —Ç–æ –∫–æ–ª-–≤–æ –≤–æ–∑—Ä–∞—Å—Ç–∞–µ—Ç –º–∏–Ω–∏–º—É–º –≤ –Ω–µ—Å–∫–æ–ª—å–∫–æ —Ä–∞–∑. –í —ç—Ç–æ–º –ø–ª–∞–Ω–µ –ø–∞—Ä–∞–º–µ—Ç—Ä–∏—á–µ—Å–∫–∏–π —Å–∏–Ω—Ç–µ–∑ —Å —É–ø—Ä–∞–≤–ª—è–µ–º—ã–º–∏ –≥–µ–Ω–µ—Ä–∞—Ç–æ—Ä–∞–º–∏ —Ç—Ä–µ–±—É–µ—Ç –Ω–∞–º–Ω–æ–≥–æ –º–µ–Ω—å—à–µ –ø–∞–º—è—Ç–∏, –Ω–æ –±–æ–ª—å—à–µ –º–∞—Ç–µ–º–∞—Ç–∏–∫–∏. –î–ª—è —Ä–∞—Å–ø–æ–∑–Ω–∞–≤–∞–Ω–∏—è –∫–æ–º–∞–Ω–¥ –µ—Å—Ç—å –ø—Ä–æ—Å—Ç–æ–µ –∏ –Ω–µ –æ—á–µ–Ω—å —Ö–æ—Ä–æ—à–µ–µ —Ä–µ—à–µ–Ω–∏–µ –¥–ª—è –∞—Ç–º–µ–≥–∏ http://www.polesite.ru/?p=2001 |
|
| –ê–≤—Ç–æ—Ä: | fedyasolder [ –í—Ç –Ω–æ—è 01, 2016 14:25:36 ] |
| –ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: | Re: –°–∏–Ω—Ç–µ–∑ —Ä–µ—á–∏ –Ω–∞ STM32F100 |
–ù–µ –æ–±—è–∑–∞—Ç–µ–ª—å–Ω–æ –≤–µ—Å—å —Å–ª–æ–≤–∞—Ä—å –∏–º–µ—Ç—å –¥–ª—è —á–∞—Å—Ç–Ω–æ–≥–æ —Å–ª—É—á–∞—è. –ü–∞—Ä–∞–º–µ—Ç—Ä–∏—á–µ—Å–∫–æ–µ —Ç–æ–∂–µ —Ö–æ—Ä–æ—à–æ, –≤–∏–¥–µ–ª –ø—Ä–∏–º–µ—Ä—ã. |
|
| –°—Ç—Ä–∞–Ω–∏—Ü–∞ 1 –∏–∑ 1 | –ß–∞—Å–æ–≤–æ–π –ø–æ—è—Å: UTC + 3 —á–∞—Å–∞ |
| Powered by phpBB © 2000, 2002, 2005, 2007 phpBB Group http://www.phpbb.com/ |
|