|
–§–æ—Ä—É–º –Ý–∞–¥–∏–æ–ö–æ—Ç • –ü—Ä–æ—Å–º–æ—Ç—Ä —Ç–µ–º—ã - –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è?
–°–æ–æ–±—â–µ–Ω–∏—è –±–µ–∑ –æ—Ç–≤–µ—Ç–æ–≤ | –ê–∫—Ç–∏–≤–Ω—ã–µ —Ç–µ–º—ã
 
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 15 –∏–∑ 15
|
[ –°–æ–æ–±—â–µ–Ω–∏–π: 291 ] |
... , , , , |
| –ê–≤—Ç–æ—Ä |
–°–æ–æ–±—â–µ–Ω–∏–µ |
Dimon456

|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è?  –î–æ–±–∞–≤–ª–µ–Ω–æ: –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å —è–Ω–≤ 03, 2021 23:12:24 |
|
–ö–∞—Ä–º–∞: 20
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 145
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Å –¥–µ–∫ 25, 2016 08:34:54
–°–æ–æ–±—â–µ–Ω–∏–π: 1849
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–°—Ä–∞–≤–Ω–∏–≤–∞–π –°–ø–æ–π–ª–µ—Ä 
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
 |
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
VladislavS
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å —è–Ω–≤ 03, 2021 23:21:05 |
|
| –°–æ–±—É—Ç—ã–ª—å–Ω–∏–∫ –ö–æ—Ç–∞ |
 |
–ö–∞—Ä–º–∞: 18
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 430
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –º–∞–π 01, 2018 19:44:47
–°–æ–æ–±—â–µ–Ω–∏–π: 2539
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
iddqd
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç —è–Ω–≤ 08, 2021 01:18:30 |
|
| –ù–∞—à–µ–ª —Ç—Ä–∞–Ω–∑–∏—Å—Ç–æ—Ä. –ü–æ–Ω—é—Ö–∞–ª. |
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Å —Å–µ–Ω 06, 2020 16:06:10
–°–æ–æ–±—â–µ–Ω–∏–π: 156
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ü–æ–∏–≥—Ä–∞–ª—Å—è —è —Å –∏–¥–µ–µ–π iddqd, –µ—Å—Ç—å 2 –≤–∞—Ä–∏–∞–Ω—Ç–∞:
1 –≤–∞—Ä–∏–∞–Ω—Ç, –∫–æ–≥–¥–∞ –ø–∏–Ω—ã —Ä–∞—Å–ø–æ–ª–∞–≥–∞—é—Ç—Å—è –Ω–∞ –æ–¥–Ω–æ–º –ø–æ—Ä—Ç—É, –Ω–µ –≤–∞–∂–Ω–æ –≤ –∫–∞–∫–æ–π –ø–æ—Å–ª–µ–¥–æ–≤–∞—Ç–µ–ª—å–Ω–æ—Å—Ç–∏.
–û–ó–£ –Ω–∞ –æ–¥–∏–Ω –ø–∏–Ω 4 –±–∞–π—Ç–∞, –Ω–∞ 8 –ø–∏–Ω–æ–≤ 32 –±–∞–π—Ç–∞. –¢–µ—Ö–Ω–∏—á–µ—Å–∫–∏ –Ω–∞ 1 –ø–∏–Ω - 1 –±–∏—Ç –Ω–∞ –ø–æ—Ä—Ü–∏—é, –µ—Å–ª–∏ -> ODR –∏–ª–∏ 2 –±–∏—Ç–∞, –µ—Å–ª–∏ -> BSRR. –í –¥–æ–ø—É—â–µ–Ω–∏–∏ port-wide –¥–æ—Å—Ç—É–ø–∞. Port-wide –¥–æ—Å—Ç—É–ø –∏–º–µ–µ—Ç —Å–º—ã—Å–ª –Ω–∞–ø—Ä–∏–º–µ—Ä –µ—Å–ª–∏ —Ç–∞–º LCD —Å 8-bit bus —Ä–∞–∑–≤–µ—Å–∏–ª–∏ –∏–ª–∏ –Ω–∞–ø—Ä–∏–º–µ—Ä –±–æ–ª—å—à–∞—è –≥—Ä—É–ø–ø–∞ —Å–≤–µ—Ç–æ–¥–∏–æ–¥–æ–≤, etc. –í –ø—Ä–∏–Ω—Ü–∏–ø–µ —Å BSRR —ç—Ç–æ –±–∏—Ç–æ–≤–∞—è –º–∞—Å–∫–∞ + latch, —Ç–∞–∫ —á—Ç–æ –º–æ–∂–Ω–æ –∏ –º–µ–Ω—å—à–µ –ø–∏–Ω–æ–≤ –∑–∞ —Ä–∞–∑ –≤–æ—Ä–æ—á–∞—Ç—å, —Å —É—Ö—É—á—à–µ–Ω–∏–µ–º –ö–ü–î —ç—Ç–æ–π –æ–ø–µ—Ä–∞—Ü–∏–∏. –¶–∏—Ç–∞—Ç–∞: –ï—Å–ª–∏ —Ö—Ä–∞–Ω–∏—Ç—å –∫–∞—Ä—Ç–∏–Ω–∫—É 256*256 —Ç–æ—á–µ–∫, –¥–∞ –≤ –¥–æ–±–∞–≤–æ–∫ –≤ —Ü–≤–µ—Ç–Ω–æ–º –∏–∑–æ–±—Ä–∞–∂–µ–Ω–∏–∏, –ø–∞—Ä–∞–ª–ª–µ–ª—å–Ω—ã–π –ø–æ—Ä—Ç 8 –ø–∏–Ω–æ–≤, 256*256*3*32 = 6.291.456 –±–∞–π—Ç.? –õ—é–±—É—é –∏–¥–µ—é –º–æ–∂–Ω–æ –¥–æ–≤–µ—Å—Ç–∏ –¥–æ –º–∞—Ä–∞–∑–º–∞. –°–ª–∞—Ç—å –º–æ–∂–Ω–æ –æ—Ç–¥–µ–ª—å–Ω—ã–µ —Ä–µ–≥–∏–æ–Ω—ã –∫–∞—Ä—Ç–∏–Ω–∫–∏/–Ω–µ–±–æ–ª—å—à–∏–µ –∏–∫–æ–Ω–∫–∏/–∏–Ω–∏—Ü–∏–∞–ª–∏–∑–∞—Ü–∏—é –¥–∏—Å–ø–ª–µ—è/etc –∏ —Ä–∞–∑–º–µ—Ä –º–æ–∂–µ—Ç –±—ã—Ç—å –≤–º–µ–Ω—è–µ–º—ã–º. –ö—Å—Ç–∞—Ç–∏ –∏ —Ä—è–¥ –¥—Ä—É–≥–∏—Ö –∫–æ–º–º—É–Ω–∏–∫–∞—Ü–∏–π –Ω–µ–¥—É—Ä–Ω–æ —Å–º–æ—Ç—Ä–∏—Ç—Å—è –≤ –≤–∏–¥–µ make packet -> queue send, –∞ –ø–æ–∫–∞ –æ–Ω–æ —Ç–∞–º send –º–æ–∂–Ω–æ —á–µ–º-—Ç–æ –µ—â–µ –∑–∞–Ω—è—Ç—å—Å—è. –ò –µ—Å–ª–∏ —Ç–∞–º –≤—Å—è–∫–æ–µ —Å–∂–∞—Ç–∏–µ, –Ω—É —Ç–æ–≥–¥–∞ –ø–æ—Å–ª–µ decompress –∏ "prepare buffer" –∏–∑ –≤–æ–Ω —Ç–æ–≥–æ –∫—É—Å–∫–∞ –Ω–∞–≤–µ—Ä–Ω–æ–µ –æ–∫? –ê –∫–∞–∫–∏–µ –µ—â–µ –≤–∞—Ä–∏–∞–Ω—Ç—ã? –ï—Å–ª–∏ –∫–æ–Ω—Ç—Ä–æ–ª–ª–µ—Ä —à–∏–Ω—ã –µ—Å—Ç—å —Ç–æ –≤—Å–µ –ø—Ä–æ—Å—Ç–æ, –Ω–æ –æ–Ω —Ç–æ–ª—å–∫–æ –≤ –æ—á–µ–Ω—å —Ä–∞–∑–ª–∞–ø–∏—Å—Ç—ã—Ö –∫–∞–º–Ω—è—Ö, –æ–Ω–∏ –¥–æ—Ä–æ–≥–∏–µ –∏ —Ä–æ—É—Ç–∏—Ç—å –ø–µ—á–∞—Ç–∫—É –∑–∞–º–∞–Ω–∞–µ—à—å—Å—è, –≤ –æ–±—â–µ–º —ç—Ç–æ —Å—Ä–∞–∑—É –ø–æ–≤—ã—à–∞–µ—Ç –ø–ª–∞–Ω–∫—É. –ê –±–µ–∑ –Ω–µ–≥–æ –≤–æ–æ–±—â–µ –∫–∞–∫–∏–µ –≤–∞—Ä–∏–∞–Ω—Ç—ã? –°–æ—Ñ—Ç–æ–º –Ω–æ–≥–æ–¥—Ä—ã–≥–∞—Ç—å? –¢–∞–∫ —ç—Ç–æ –≤–æ–æ–±—â–µ –±–ª–æ–∫–∏—Ä—É—é—â–∞—è –æ–ø–µ—Ä–∞—Ü–∏—è, –Ω–∞ –µ–µ –≤—Ä–µ–º—è –ø—Ä–æ—Ü –Ω–µ–¥–µ–µ—Å–ø–æ—Å–æ–±–µ–Ω —Ç–æ–ª–∫–æ–º (–º–∏–Ω—É—Å IRQ). –ê, –Ω—É –µ—â–µ RTOS –º–æ–∂–Ω–æ, –Ω–æ —è –Ω–µ –∑–Ω–∞—é –∫–∞–∫ —Ç–∞–º —Å —Ç–∞–π–º–∏–Ω–≥–∞–º–∏ —à–∏–Ω—ã –±—É–¥–µ—Ç, –≤ —Ç–∞–∫–∏–µ –¥–µ–±—Ä–∏ —è –ª–µ–∑—Ç—å –Ω–µ —Å–æ–±–∏—Ä–∞—é—Å—å. –ú–Ω–µ –æ—Ç MK –Ω—É–∂–µ–Ω –Ω–∏–∂–Ω–∏–π —É—Ä–æ–≤–µ–Ω—å –∏ –ø—Ä–µ–¥—Å–∫–∞–∑—É–µ–º–æ—Å—Ç—å, –∞ –Ω–µ –≤—ã—Å–æ–∫–∏–µ –∞–±—Å—Ç—Ä–∞–∫—Ü–∏–∏. –¶–∏—Ç–∞—Ç–∞: –ù—É –∫–∞–∫ —Ç–∞–∫ –º–æ–∂–Ω–æ –±–µ–∑ –∫–æ–¥–∞ –æ–±–æ–π—Ç–∏—Å—å? –í–µ–¥—å –µ—â–µ —Å–∂–∞—Ç—å –∫–∞—Ä—Ç–∏–Ω–∫—É –º–æ–∂–Ω–æ, –±–µ–∑ –∫–æ–¥–∞ –Ω–∏ –∫–∞–∫. –ï—Å—Ç—å –≤–∞—Ä–∏–∞–Ω—Ç—ã –∫–æ–≥–¥–∞ –º–æ–∂–Ω–æ —Å–æ–≤—Å–µ–º –±–µ–∑ –∫–æ–¥–∞. –¢–∏–ø–∞ quasi-hardware PWM, –∫–æ–≥–¥–∞ —Ü–µ–ª—ã–π –ø–æ—Ä—Ç –≤–æ—Ä–æ—á–∞–µ—Ç—Å—è –∑–∞–∫–æ–ª—å—Ü–æ–≤–∞–Ω—ã–º DMA –±–µ–∑ –≤–º–µ—à–∞—Ç–µ–ª—å—Å—Ç–≤–∞ —Å–æ—Ñ—Ç–∞ –≤–æ–æ–±—â–µ. –≠—Ç–æ –±—É–¥–µ—Ç —Ä–∞–±–æ—Ç–∞—Ç—å –¥–∞–∂–µ –µ—Å–ª–∏ –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–Ω–æ–µ —è–¥—Ä–æ –≤—Å—Ç—Ä—è–Ω–µ—Ç. –ü—Ä–∞–≤–¥–∞ –æ–Ω–æ —Ç–æ–≥–¥–∞ –Ω–µ —Å–º–æ–∂–µ—Ç –ø–∞—Ä–∞–º–µ—Ç—Ä—ã –ø–æ–¥–∫—Ä—É—á–∏–≤–∞—Ç—å, –Ω–æ –µ—Å–ª–∏ —ç—Ç–æ –Ω–µ —Ç—Ä–µ–±–æ–≤–∞–ª–æ—Å—å, —Ç–æ —Ç–∞–º —Ü–µ–ª–∏–∫–æ–º –∂–µ–ª–µ–∑–∫–∏ –±–µ–∑ —É—á–∞—Å—Ç–∏—è –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–∞ —Å–º–æ–≥—É—Ç –≤—Å–µ —Å–¥–µ–ª–∞—Ç—å. –¶–∏—Ç–∞—Ç–∞: –ó–Ω–∞—á–∏—Ç –¥–º–∞ –±—É–¥–µ–º –∑–∞–ø—É—Å–∫–∞—Ç—å —Ç–æ–ª—å–∫–æ –Ω–∞ –æ–¥–∏–Ω –ø–∏–Ω, –∞ –≤ –ø—Ä–µ—Ä—ã–≤–∞–Ω–∏–∏ –≤—ã–∫–ª—é—á–∞—Ç—å –∫–∞–Ω–∞–ª, 1 –ø–∏–Ω –Ω–µ —ç—Ñ—Ñ–µ–∫—Ç–∏–≤–Ω–æ –ø–æ –ö–ü–î –æ–ø–µ—Ä–∞—Ü–∏–∏. –û–Ω–æ –º–æ–∂–µ—Ç –í–ï–°–¨ –ü–û–Ý–¢ –∑–∞ —Ç—Ä–∞–Ω–∑–∞–∫—Ü–∏—é –∫–∞–Ω—Ç–æ–≤–∞—Ç—å. –ù–æ –¥–∞, —ç—Ç–æ –ø–æ—Ç—Ä–µ–±—É–µ—Ç –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω—ã—Ö –∫–æ–º–ø—Ä–æ–º–∏—Å—Å–æ–≤. –û–ø—Ç–∏–º–∞–ª—å–Ω–µ–µ –≤—Å–µ–≥–æ –≤—ã–¥–µ–ª–∏—Ç—å –≤–µ—Å—å –ø–æ—Ä—Ç –ø–æ–¥ —Ç–∞–∫–æ–µ —Ä–∞–∑–≤–ª–µ—á–µ–Ω–∏–µ. –ê –ø–æ—á–µ–º—É –±—ã —Ö–∞—Ä–¥–≤–∞—Ä—É –Ω–µ —Å–¥–µ–ª–∞—Ç—å —Ö–∞—Ä–¥–≤–∞—Ä—É –∏ —Å–æ—Ñ—Ç—É —É–¥–æ–±–Ω–æ –∏ –±—ã—Å—Ç—Ä–æ?. –ò –¥–∞, data -> ODR –±—É–¥–µ—Ç —Å –ö–ü–î –≤–ø–ª–æ—Ç—å –¥–æ 100%. –í BSRR —Ç–æ–ª—å–∫–æ –¥–æ 50%, –±–∏—Ç–æ–≤ –≤ 2 —Ä–∞–∑–∞ –±–æ–ª—å—à–µ. –ó–∞—Ç–æ –µ—Å—Ç—å latch, –º–æ–∂–Ω–æ —Ç–æ–ª—å–∫–æ –Ω–µ–∫–æ—Ç–æ—Ä—ã–µ –±–∏—Ç—ã –≤–æ—Ä–æ—á–∞—Ç—å. –≠—Ç–æ –¥–∞–∂–µ –º–æ–∂–µ—Ç —Å–æ—Å—É—â–µ—Å—Ç–≤–æ–≤–∞—Ç—å —Å –Ω–µ–∫–æ—Ç–æ—Ä–æ–π –ø–µ—Ä–∏—Ñ–µ—Ä–∏–µ–π - AFIO –≤ –æ–±—â–µ–º —Å–ª—É—á–∞–µ –Ω–µ –æ—á–µ–Ω—å –∏–Ω—Ç–µ—Ä–µ—Å—É–µ—Ç —á—Ç–æ —Ç–∞–º GPIO –ø—ã—Ç–∞–ª—Å—è –≤–æ–æ–±—â–µ –∏–∑–æ–±—Ä–∞–∑–∏—Ç—å. –ê –∫–∞–∫–æ–µ –¥–µ–ª–æ –∫–∞–∫–æ–º—É-–Ω–∏–±—É–¥—å uart input'—É –¥–æ –µ–≥–æ –±–∏—Ç–∞ –≤ ODR? –¶–∏—Ç–∞—Ç–∞: –ê —Ç–µ–ø–µ—Ä—å –≤–æ–ø—Ä–æ—Å –≤ –ø—Ä–∞–∫—Ç–∏—á–µ—Å–∫–æ–º –ø—Ä–∏–º–µ–Ω–µ–Ω–∏–∏, –¥–ª—è —á–µ–≥–æ –∏ –∑–∞ —á–µ–º? –ò –≥–¥–µ —Ç—É—Ç –≤—ã–∏–≥—Ä—ã—à –≤ —Å–∫–æ—Ä–æ—Å—Ç–∏? –í—ã –∫–∞–∂–µ—Ç—Å—è –Ω–µ –ø–æ–Ω—è–ª–∏. –°—É—Ç—å –∏–¥–µ–∏: –≤ RAM –∏–ª–∏ Flash –∑–∞–≤–æ–¥–∏—Ç—Å—è –±—É—Ñ–µ—Ä. –û–Ω –æ–ø–∏—Å—ã–≤–∞–µ—Ç sequencing –≥—Ä—É–ø–ø—ã –ø–∏–Ω–æ–≤. –¢–∏–ø–∞ —ç–≤–æ–ª—é—Ü–∏–∏ —Å–æ—Å—Ç–æ—è–Ω–∏—è –ø–æ—Ä—Ç–∞ –≤–æ –≤—Ä–µ–º–µ–Ω–∏. –ò –∫–æ–Ω–µ—á–Ω–æ –∂–µ —Ç—Ä–∞–Ω—Å—Ñ–µ—Ä–æ–≤ –ø—Ä–∏ —ç—Ç–æ–º –¥–æ–ª–∂–Ω–æ –±—ã—Ç—å —É–∂ —Ç–æ—á–Ω–æ –Ω–µ 1. –ò–Ω–∞—á–µ –Ω–∞—Ö—Ä–µ–Ω–∞ –± —Ç–∞–∫–æ–µ —Å—á–∞—Å—Ç—å–µ —Å —Å–µ—Ç–∞–ø–æ–º DMA. –ò –¥–∞, –ø–æ—Å–∫–æ–ª—å–∫—É DMA –æ—Ç–ø—É—Å–∫–∞–µ—Ç —à–∏–Ω—É —á—Ç–æ–±—ã –ø—Ä–æ—Ü—É —á—Ç–æ-—Ç–æ –¥–∞—Ç—å, –æ–Ω —Ä–µ–∫–æ—Ä–¥ —Å–∫–æ—Ä–æ—Å—Ç–∏ –º–æ–∂–µ—Ç –∏ –Ω–µ –ø–æ—Å—Ç–∞–≤–∏—Ç. –ù–æ –µ—Å—Ç—å –æ–¥–Ω–∞ killer feature. –ú—ã –º–æ–∂–µ–º "–∑–∞—Ä—è–¥–∏—Ç—å –æ—Ç–ø—Ä–∞–≤–∫—É –ø–∞–∫–µ—Ç–∞" –∏–ª–∏ –¥–∞–∂–µ "–∑–∞–∫–æ–ª—å—Ü–µ–≤–∞—Ç—å –æ—Ç–ø—Ä–∞–≤–∫—É –±—É—Ñ–µ—Ä–∞" - –∏ –∑–∞–Ω—è—Ç—å—Å—è —Å–≤–æ–∏–º–∏ –¥–µ–ª–∞–º–∏! DMA –∞—Å–∏–Ω—Ö—Ä–æ–Ω–µ–Ω –æ—Ç–Ω–æ—Å–∏—Ç–µ–ª—å–Ω–æ –∫–æ–¥–∞ –ø—Ä–æ—Ü–∞. –¢–∞–∫ —á—Ç–æ –æ—Å–Ω–æ–≤–Ω–æ–π –ø—Ä–æ—Ñ–∏—Ç - –≤ –∞—Å–∏–Ω—Ö—Ä–æ–Ω—â–∏–Ω–µ —ç—Ç–æ–≥–æ –æ—Ç–Ω–æ—Å–∏—Ç–µ–ª—å–Ω–æ –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–∞ –∏ –ø–æ–¥–ø–µ—Ä—Ç–æ—Å—Ç–∏ –∂–µ–ª–µ–∑–æ–º. –ê –æ—Ç—Å—É—Ç—Å—Ç–≤–∏–µ —Ç—Ä–∞—Ñ–∏–∫–∞ –∫–æ–¥–∞ –ø–æ —à–∏–Ω–∞–º –¥–ª—è —ç—Ç–æ–π –∞–∫—Ç–∏–≤–Ω–æ—Å—Ç–∏ - –ø—Ä–∏—è—Ç–Ω—ã–π –ø–æ–±–æ—á–Ω—ã–π —ç—Ñ—Ñ–µ–∫—Ç, DMA –Ω–µ –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä, –µ–º—É –¥–ª—è –≤–æ—Ä–æ—á–∞–Ω–∏—è –ø–æ—Ä—Ü–∏–∏ –¥–∞–Ω–Ω—ã—Ö –Ω–µ –Ω–∞–¥–æ –∏–Ω—Å—Ç—Ä—É–∫—Ü–∏–∏ –ø–æ —à–∏–Ω–µ –≥–æ–Ω—è—Ç—å. –ï—Å–ª–∏ —Ö–æ—á–µ—Ç—Å—è –∏–º–µ–Ω–Ω–æ 1 –±–∏—Ç, –∏–º–µ–Ω–Ω–æ DMA, –Ω—É, –Ω–µ –∑–Ω–∞—é, SPI –∫–∞–∫–æ–π –ø–æ—é–∑–∞–π—Ç–µ, —á—Ç–æ–ª–∏. –û–Ω –≤–∏–¥–∏—Ç–µ –ª–∏ –¥–µ—Å–µ—Ä–µ–∞–ª–∏–∑—É–µ—Ç —Ç–æ —á—Ç–æ –≤ –Ω–µ–≥–æ –≤–≥—Ä—É–∑–∏–ª–∏, —Ç–∞–∫ –ö–ü–î –æ–ø–µ—Ä–∞—Ü–∏–∏ —Å–∏–ª—å–Ω–æ –∏–Ω—Ç–µ—Ä–µ—Å–Ω–µ–µ, –∞ –ø–æ—Å–ª–∞—Ç—å –æ–ø—è—Ç—å –∂–µ –º–æ–∂–Ω–æ "—Ü–µ–ª—ã–π –ø–∞–∫–µ—Ç" –∏ –¥–∞–∂–µ, –≤–µ—Ä–æ—è—Ç–Ω–æ, –∑–∞–∫–æ–ª—å—Ü–µ–≤–∞—Ç—å, –µ—Å–ª–∏ —ç—Ç–æ –∑–∞ –∫–∞–∫–∏–º-—Ç–æ —á–µ—Ä—Ç–æ–º –Ω–∞–¥–æ. –î–ª—è —Ç–æ–≥–æ —á—Ç–æ–±—ã –≥—Ä–∞—Ñ–∏–∫—É –≤ –∂–∫ –∏–Ω–¥–∏–∫–∞—Ç–æ—Ä –ø–∏—Å–∞—Ç—å - –Ω—É–∂–Ω–æ –¥–º–∞ –≤–º–µ—Å—Ç–µ —Å —Ç–∞–π–º–µ—Ä–æ–º –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å. –ò –≤–∞—Å —Å –Ω–æ–≤—ã–º –≥–æ–¥–æ–º. –Ø –ø–æ–ø—Ä–æ–±–æ–≤–∞–ª –∏ —Å mem2mem. –í–æ–æ–±—â–µ –Ω–∞ —Å–≤–µ—Ç–æ–¥–∏–æ–¥–∞—Ö –∫–æ—Ç–æ—Ä—ã–º —è —Å–¥–µ–ª–∞–ª —Ç–∞–∫ –ø–æ–¥–æ–±–∏–µ PWM —ç—Ç–æ –ø—Ä–æ–∫–∞—Ç–∏–ª–æ. –ù–æ –≤—ã–ø–∞–¥—É—Ç –ª–∏ –∏–∑ –ø–æ—Ä—Ç–∞ —Ç—Ä–∞–Ω—Å—Ñ–µ—Ä—ã –∏ –ø—Ä–æ–∫–∞—Ç—è—Ç –ª–∏ —É–∂ –∫–∞–∫–∏–µ –ø–æ–ª—É—á–∞—Ç—Å—è —Ç–∞–π–º–∏–Ω–≥–∏ (–¥–∏—Å–ø–ª–µ—é —ç—Ç–æ –≤–∞–∂–Ω–æ) –µ—Å–ª–∏ —Ä–∞—Å–ø–∏—Å–∞—Ç—å "bus seqencing" –∏ –≤–µ—Å—å –µ–≥–æ –ø—É–ª—å–Ω—É—Ç—å –∫–∞–∫ mem2mem - –≤–æ–ø—Ä–æ—Å –æ—Ç–∫—Ä—ã—Ç—ã–π. –ñ–µ–ª–∞—é—â–∏–µ –º–æ–≥—É—Ç –ø–æ–∑—ã—Ä–∏—Ç—å –µ—Å–ª–∏ —É –Ω–∏—Ö —Å–∫–æ—Ä–æ—Å—Ç–Ω–æ–π –º–Ω–æ–≥–æ–∫–∞–Ω–∞–ª—å–Ω—ã–π –ª–æ–≥–∏—á–µ—Å–∫–∏–π –∞–Ω–∞–ª–∏–∑–∞—Ç–æ—Ä –µ—Å—Ç—å. PWM –≤ –º–∏–∫—Ä–æ–∫–æ–Ω—Ç—Ä–æ–ª–ª–µ—Ä–µ —ç—Ç–æ –∑–Ω–∞—á–∏—Ç–µ–ª—å–Ω–æ –±–æ–ª—å—à–µ, —á–µ–º "–Ω–æ–≥–æ–¥—Ä—ã–≥–∞–Ω—å–µ" —Å –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–æ–π —á–∞—Å—Ç–æ—Ç–æ–π, –∏ –∫–∞–∫ —Ç–æ–ª—å–∫–æ –Ω–∞—á–Ω—ë—Ç—Å—è –ø–æ–ø—ã—Ç–∫–∞ —Ä–µ–∞–ª–∏–∑–æ–≤–∞—Ç—å –µ–≥–æ –ø–æ–ª–Ω–æ—Ü–µ–Ω–Ω—É—é —Ä–∞–±–æ—Ç—É, –∏ –≥–ª—è–Ω–µ—Ç—Å—è –Ω–∞ –±–ª–æ–∫-—Å—Ö–µ–º—É, —Ç–æ –Ω–∞ DMA –æ—Å—Ç–∞–Ω–µ—Ç—Å—è –º–∏–Ω–∏–º—É–º —Ñ—É–Ω–∫—Ü–∏–æ–Ω–∞–ª–∞. –¢–∞–∫ —Ä–µ–∞–ª–∏–∑—É–µ—Ç—Å—è —Ç–æ–ª—å–∫–æ –æ—á–µ–Ω—å –±–∞–∑–æ–≤—ã–π –≤–∞—Ä–∏–∞–Ω—Ç PWM, —Å —Ä—è–¥–æ–º –æ–≥—Ä–∞–Ω–∏—á–µ–Ω–∏–π. –°–∫–∞–∂–∏—Ç–µ, –∞ –≤–∞–º –Ω–∏–∫–æ–≥–¥–∞ –Ω–µ —Ö–æ—Ç–µ–ª–æ—Å—å PWM'–Ω—É—Ç—å —Å—Ä–∞–∑—É –ú–ù–û–ì–û —Å–≤–µ—Ç–æ–¥–∏–æ–¥–æ–≤, –Ω–∞–ø—Ä–∏–º–µ—Ä? –ú–æ–∂–Ω–æ –∏ –Ω–µ PWM'–Ω—É—Ç—å, –∞ "sequence". –ü—Ä–∏ —Ç–æ–º –≤–æ—Ç —Ç–∞–∫ - —á–∏—Å–ª–æ –≤—ã—Ö–æ–¥–æ–≤ "PWM" —Ç–∞–∫–∏ –¥–æ 16 –Ω–∞ –ø–æ—Ä—Ç - –∏ —Ç–∞–∫–∏ –≤ –æ—Ç–ª–∏—á–∏–µ –æ—Ç —Å–æ–≤—Å–µ–º —Å–æ—Ñ—Ç–≤–∞—Ä–Ω—ã—Ö —ç—Ä–∑–∞—Ü–µ–≤ —Ö–æ—Ä–æ—à–æ –ø–æ–¥–ø–µ—Ä—Ç–æ –∂–µ–ª–µ–∑–æ–º, –≤–ø–ª–æ—Ç—å –¥–æ —Ç–æ–≥–æ —á—Ç–æ –±—É–¥–µ—Ç –¥–æ–ª–±–∏—Ç—å —É–∫–∞–∑–∞–Ω–Ω—ã–º (–ø—Ä–∏ —Ñ–æ—Ä–º–∏—Ä–æ–≤–∞–Ω–∏–∏ –±—É—Ñ–µ—Ä–∞) duty/–ø–æ—Å–ª–µ–¥–æ–≤–∞—Ç–µ–ª—å–Ω–æ—Å—Ç—å—é –¥–∞–∂–µ –ø—Ä–∏ –∫–æ–Ω—á–∏–Ω–µ (–∏–ª–∏ –∑–∞–Ω—è—Ç–æ—Å—Ç–∏) –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä–Ω–æ–≥–æ —è–¥—Ä–∞. –î–∞ –µ—â–µ —à–∏–Ω—É –ø–æ—Ç–æ–∫–æ–º –∫–æ–º–∞–Ω–¥ –Ω–µ –≥—Ä—É–∑–∏—Ç, –≤ –æ—Ç–ª–∏—á–∏–µ –æ—Ç —Å–æ—Ñ—Ç—ç—Ä–∑–∞—Ü–µ–≤. –ê —Ä–∞—Å—Å—É–∂–¥–µ–Ω–∏—è –æ —Ö–∞—Ä–¥–≤–∞—Ä–Ω—ã—Ö PWM - —ç—Ç–æ –ø—Ä–µ–∫—Ä–∞—Å–Ω–æ, –Ω–æ –≤–æ—Ç –∑–∞—Ö–æ—á–µ—Ç—Å—è –ø–∞—Ä—É –¥–µ—Å—è—Ç–∫–æ–≤ –∫–∞–Ω–∞–ª–æ–≤ "—Ö–æ—Ç—å –∫–∞–∫–æ–≥–æ-—Ç–æ PWM", –¥–ª—è –Ω–∞–ø—Ä–∏–º–µ—Ä –≥—Ä—É–ø–ø—ã —Å–≤–µ—Ç–æ–¥–∏–æ–¥–æ–≤ - –∏ —Ç–æ–≥–¥–∞ —á–µ–≥–æ? –•–∞—Ä–¥–≤–∞—Ä–Ω—ã—Ö –∫–∞–Ω–∞–ª–æ–≤ –æ–≥—Ä–∞–Ω–∏—á–µ–Ω–Ω–æ–µ –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ, –∏ –≤–æ—Ç –¥–ª—è –Ω–∏—Ö –º–æ–∂–Ω–æ –∏ –∏–Ω—Ç–µ—Ä–µ—Å–Ω–µ–µ –∏ —Ç—Ä–µ–±–æ–≤–∞—Ç–µ–ª—å–Ω–µ–µ –ø—Ä–∏–º–µ–Ω–µ–Ω–∏—è –Ω–∞–π—Ç–∏. PWM –¥–æ –∫—É—á–∏ –ø—Ä–∏–¥—É–º–∞–ª—Å—è. –ù–µ—Å–∫–æ–ª—å–∫–æ –∏–Ω—Ç–µ—Ä–µ—Å–Ω–µ–µ ... —Å–∫–∞–∂–µ–º —Ç–∞–∫, "—à—Ç—É–∫–∞–º —Å —Ä–∞–∑–≤–µ—Ä—Ç–∫–æ–π". –ö–æ–≥–¥–∞ –∫—É—á–∞ —Å–≤–µ—Ç–æ–¥–∏–æ–¥–æ–≤ –Ω–∞ —ç–Ω–Ω–æ–º –ø–æ—Ä—Ç—É –∏–º–µ–µ—Ç –Ω–µ–∫–∏–π —Å–º—ã—Å–ª. –í–æ—Ç —Ç–∞–º —Ç–∞–π–º–µ—Ä ... –º–æ–∂–µ—Ç –æ—á–µ–Ω—å –∫—Ä—É—Ç–æ –≤–ø–∏—Å–∞—Ç—å—Å—è. –¢–∞–∫–æ–π —Å–µ–±–µ –∞–ø–ø–∞—Ä–∞—Ç–Ω—ã–π blitter/display controller, –µ—Å–ª–∏ –º–æ–∂–Ω–æ —Ç–∞–∫ —Å–∫–∞–∑–∞—Ç—å –ø—Ä–æ —Ç–∞–∫—É—é —à—Ç—É–∫—É.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
AVI-crak
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç —è–Ω–≤ 08, 2021 15:04:41 |
|
| –ü—Ä–æ—Ä–µ–∑–∞–ª–∏—Å—å –∑—É–±—ã |
 |
–ö–∞—Ä–º–∞: 2
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 14
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°–± —è–Ω–≤ 09, 2016 15:51:17
–°–æ–æ–±—â–µ–Ω–∏–π: 202
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ù–æ –≤—ã–ø–∞–¥—É—Ç –ª–∏ –∏–∑ –ø–æ—Ä—Ç–∞ —Ç—Ä–∞–Ω—Å—Ñ–µ—Ä—ã –∏ –ø—Ä–æ–∫–∞—Ç—è—Ç –ª–∏ —É–∂ –∫–∞–∫–∏–µ –ø–æ–ª—É—á–∞—Ç—Å—è —Ç–∞–π–º–∏–Ω–≥–∏ (–¥–∏—Å–ø–ª–µ—é —ç—Ç–æ –≤–∞–∂–Ω–æ) –û–¥–∏–Ω –∫–∞–Ω–∞–ª —Ç–∞–π–º–µ—Ä–∞ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –∫–∞–∫ –∏–º–∏—Ç–∞—Ü–∏—é –Ω–æ–≥–∏ WR, –≤—Ç–æ—Ä—ã–º –∫–∞–Ω–∞–ª–æ–º –ø–∏–Ω–∞—Ç—å –¥–º–∞. –ò –¥–∞, –¥–º–∞ —É–∂–µ –∑–∞–≥—Ä—É–∑–∏–ª–æ –¥–∞–Ω–Ω—ã–µ –¥–ª—è –¥–∞–ª—å–Ω–µ–π—à–µ–π —Ä–∞–±–æ—Ç—ã, –µ—Å–ª–∏ —Ö–æ—á–µ—Ç—Å—è - –º–æ–∂–Ω–æ –≥—Ä—É–∑–∏—Ç—å —Ü–µ–ª—É—é –ø–∞—á–∫—É –¥–∞–Ω–Ω—ã—Ö. –ü–æ—Ç–µ—Ä–∏ –¥–∞–Ω–Ω—ã—Ö –º–æ–≥—É—Ç –≤–æ–∑–Ω–∏–∫–Ω—É—Ç—å —Ç–æ–ª—å–∫–æ –≤ –æ–¥–Ω–æ–º —Å–ª—É—á–∞–µ: –¥—Ä—É–≥–æ–π –¥–º–∞ —Å –±–æ–ª–µ–µ –≤—ã—Å–æ–∫–∏–º –ø—Ä–∏–æ—Ä–∏—Ç–µ—Ç–æ–º —Ñ–∏–≥–∞—á–µ—Ç –≤ —Ä–µ–∂–∏–º–µ –Ω–æ–Ω—Å—Ç–æ–ø.
_________________
sRtoS
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
bob1
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç —Å–µ–Ω 12, 2025 06:39:42 |
|
| –ú—É—á–∏—Ç–µ–ª—å –º–∏–∫—Ä–æ—Å—Ö–µ–º |
–ö–∞—Ä–º–∞: 24
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 144
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –∏—é–Ω 08, 2011 20:25:20
–°–æ–æ–±—â–µ–Ω–∏–π: 450
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
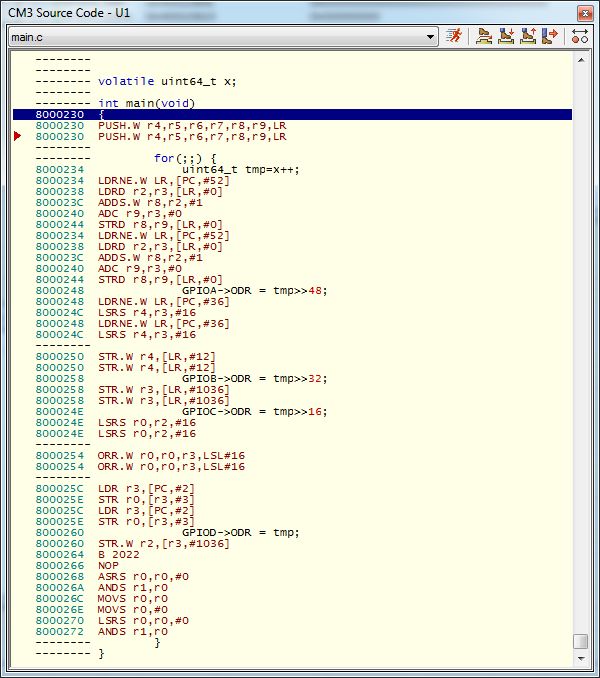
–ü—Ä–æ–¥–æ–ª–∂–µ–Ω–∏–µ –æ—Ç —Å—é–¥–∞ viewtopic.php?f=59&t=67578&start=8840–ü–æ –ø–æ–≤–æ–¥—É —Ç–∞–∫—Ç–æ–≤ –≤–æ–∑–Ω–∏–∫ –≤–æ–ø—Ä–æ—Å. –ö–æ–º–∞–Ω–¥–∞ LDR R0,[R1, #+0]; –ª–µ–∂–∏—Ç —É–∂–µ –≤ –∫–æ–Ω–≤–µ–π–µ—Ä–µ. –î–æ –Ω–µ–µ –∏ –ø–æ—Å–ª–µ –∫–æ–º–∞–Ω–¥ —á—Ç–µ–Ω–∏—è –∏ –∑–∞–ø–∏—Å–∏ –Ω–µ—Ç. –ó–∞ —Å–∫–æ–ª—å–∫–æ —Ç–∞–∫—Ç–æ–≤ –¥–æ–ª–∂–Ω–∞ –æ–±—Ä–∞–±–æ—Ç–∞—Ç—å—Å—è? –ó–∞ 2 –∏–ª–∏ 3? –ø—Ä–æ—Ü–µ—Å—Å–æ—Ä STM32G431. –ü–æ—á–µ–º—É 2/3? –í–æ–ø—Ä–æ—Å –∏ –≤–æ–∑–Ω–∏–∫, —á—Ç–æ –º–µ–Ω—å—à–µ 3 –Ω–µ –º–æ–≥—É –ø–æ–ª—É—á–∏—Ç—å, –∞ –≤ —Ç–µ–æ—Ä–∏–∏ –¥–æ–ª–∂–Ω–æ –±—ã—Ç—å 2. –Ý–∞–∑ –Ω–µ —Å –∫–µ–º —Å–ø–∞—Ä–∏–≤–∞—Ç—å—Å—è, —Ç–æ –≤ –≤–∞—à–µ–º —Å–ª—É—á–∞–µ –Ω–∞ CM4 –¥–æ–ª–∂–Ω–æ –±—ã—Ç—å 2 —Ç–∞–∫—Ç–∞. –ù–∏–∂–µ —Ç–µ—Å—Ç–æ–≤–∞—è –ø—Ä–æ–≥–∞ –¥–ª—è —Ç–µ—Å—Ç–∞. –õ–µ–∂–∏—Ç –≤ –°–°M, —Ö–æ—Ç—è –∏–∑ —Ñ–ª–µ—à—å —Ç–∞–∫–∂–µ —Ä–∞–±–æ—Ç–∞–µ—Ç. –ß–∞—Å—Ç–æ—Ç–∞ 16–ú–ì—Ü. –ò–∑–º–µ–Ω—è—è n –≤—ã—á–∏—Å–ª—è–µ–º —Ä–∞–∑–Ω–∏—Ü—É —Å—á–µ—Ç–∞ —Ç–∞–π–º–µ—Ä–∞ 4. –ü–æ–ª—É—á–∞–µ–º —Ç–∞–∫—Ç—ã –∑–∞ —Ü–∏–∫–ª. –í –º–µ–Ω—å—à–µ–º —Å–ª—É—á–∞–µ 21=7+2+3*4. 7 —ç—Ç–æ 1 —Ç–∞–∫—Ç–æ–≤—ã–µ –∫–æ–º–∞–Ω–¥—ã, 2 —Ç–∞–∫—Ç–∞ –ø–µ—Ä–µ—Ö–æ–¥, 4- –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ LDR. 3 –≤—ã—Ö–æ–¥–∏—Ç —Ç–∞–∫—Ç—ã –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–º–∞–Ω–¥—ã LDR. –°–ø–æ–π–ª–µ—Ä–ö–æ–¥: /*
#define reg (uint32_t) TIM4->CNT
#define reg1 (uint32_t) TIM4->CNT
#define reg2 (uint32_t) TIM4->CNT
#define reg3 (uint32_t) TIM4->CNT
*/
#define reg (uint32_t) GPIOA->IDR
#define reg1 (uint32_t) GPIOA->IDR
#define reg2 (uint32_t) GPIOA->IDR
#define reg3 (uint32_t) GPIOA->IDR
/*
#define reg bx[0]
#define reg1 bx[1]
#define reg2 bx[2]
#define reg3 bx[3]
*/
__root uint32_t bx[]={1,2,3,4};
__root uint32_t res;
void test (void)@".ccmram"{
LL_APB1_GRP1_EnableClock(LL_APB1_GRP1_PERIPH_TIM4);
LL_DBGMCU_APB1_GRP1_FreezePeriph(LL_DBGMCU_APB1_GRP1_TIM4_STOP);
LL_TIM_InitTypeDef TIM_InitStruct = {0};
TIM_InitStruct.Autoreload = 0xFFFFFFFFU;
LL_TIM_Init(TIM4, &TIM_InitStruct);
uint32_t n=6;
uint32_t w,w1;
TIM4->CR1=1;
//----------
do{
w=reg;
w1=w1+w;
w= reg1;
w1=w1+w;
w= reg2;
w1=w1+w;
w= reg3;
w1=w1+w;
}
while (n--!=0) ;
//----------
res=w1;
TIM4->CR1=0;
}; –ù–∏–∂–µ –ª–∏—Å—Ç–∏–Ω–≥ —Ü–∏–∫–ª–∞. –î–ª—è –ø—Ä–∞–≤–∏–ª—å–Ω–æ–≥–æ –ø–æ–ª—É—á–µ–Ω–∏—è –Ω—É–∂–Ω–æ –ø–æ–∏–≥—Ä–∞—Ç—å—Å—è –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–µ–π –¥–ª—è —Ä–∞–∑–Ω—ã—Ö reg. –°–ø–æ–π–ª–µ—Ä–ö–æ–¥: // 1102 //----------
// 1103 do{
// 1104 w=reg;
??test_1:
LDR R0,[R3, #+0]
// 1105 w1=w1+w;
ADDS R2,R0,R2
// 1106 w= reg1;
LDR R0,[R3, #+0]
// 1107 w1=w1+w;
ADDS R2,R0,R2
// 1108 w= reg2;
LDR R0,[R3, #+0]
// 1109 w1=w1+w;
ADDS R2,R0,R2
// 1110 w= reg3;
LDR R0,[R3, #+0]
// 1111 w1=w1+w;
ADDS R2,R0,R2
// 1112 }
// 1113 while (n--!=0) ;
MOV R0,R1
SUBS R1,R0,#+1
CMP R0,#+0
BNE.N ??test_1
// 1114 //----------
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
jcxz
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç —Å–µ–Ω 12, 2025 12:53:30 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
–ö–∞—Ä–º–∞: -7
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 181
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 15, 2017 10:51:13
–°–æ–æ–±—â–µ–Ω–∏–π: 1569
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ö–æ–º–∞–Ω–¥–∞ LDR R0,[R1, #+0]; –ª–µ–∂–∏—Ç —É–∂–µ –≤ –∫–æ–Ω–≤–µ–π–µ—Ä–µ. –ü–æ—á–µ–º—É —Ç–∞–∫–æ–π –≤—ã–≤–æ–¥? –ö–∞–∫–æ–≤–∞ —à–∏—Ä–∏–Ω–∞ —à–∏–Ω—ã CPU, —á–∏—Ç–∞—é—â–µ–π –ø–æ—Ç–æ–∫ –∫–æ–º–∞–Ω–¥ –∏–∑ –¥–∞–Ω–Ω–æ–π –ø–∞–º—è—Ç–∏? –ï—Å—Ç—å –ª–∏ –¥—Ä—É–≥–∏–µ bus-masters, —Ä–∞–±–æ—Ç–∞—é—â–∏–µ –≤ —ç—Ç–æ –≤—Ä–µ–º—è? –ù–∏–∂–µ —Ç–µ—Å—Ç–æ–≤–∞—è –ø—Ä–æ–≥–∞ –¥–ª—è —Ç–µ—Å—Ç–∞. –õ–µ–∂–∏—Ç –≤ –°–°M, —Ö–æ—Ç—è –∏–∑ —Ñ–ª–µ—à—å —Ç–∞–∫–∂–µ —Ä–∞–±–æ—Ç–∞–µ—Ç. –ß–∞—Å—Ç–æ—Ç–∞ 16–ú–ì—Ü.
–ò–∑–º–µ–Ω—è—è n –≤—ã—á–∏—Å–ª—è–µ–º —Ä–∞–∑–Ω–∏—Ü—É —Å—á–µ—Ç–∞ —Ç–∞–π–º–µ—Ä–∞ 4. –ü–æ–ª—É—á–∞–µ–º —Ç–∞–∫—Ç—ã –∑–∞ —Ü–∏–∫–ª. –í –º–µ–Ω—å—à–µ–º —Å–ª—É—á–∞–µ 21=7+2+3*4. 7 —ç—Ç–æ 1 —Ç–∞–∫—Ç–æ–≤—ã–µ –∫–æ–º–∞–Ω–¥—ã, 2 —Ç–∞–∫—Ç–∞ –ø–µ—Ä–µ—Ö–æ–¥, 4- –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ LDR. 3 –≤—ã—Ö–æ–¥–∏—Ç —Ç–∞–∫—Ç—ã –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–º–∞–Ω–¥—ã LDR. –ê –∫—É–¥–∞ —É–∫–∞–∑—ã–≤–∞–µ—Ç R3? –û—Ç–∫—É–¥–∞ –∏–¥—ë—Ç —á—Ç–µ–Ω–∏–µ? –ò –∫–∞–∫ –∏–º–µ–Ω–Ω–æ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ –∑–∞–º–µ—Ä –≤—Ä–µ–º–µ–Ω–∏ –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è —Ü–∏–∫–ª–∞? –ò–º—Ö–æ: —Ç–µ—Å—Ç–æ–≤—ã–π –∫–æ–¥ - –Ω–µ–∫–æ—Ä—Ä–µ–∫—Ç–Ω—ã–π. –î–ª–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è LDR —Å–ª–µ–¥—É–µ—Ç –∏–∑–º–µ—Ä—è—Ç—å –Ω–µ —Ç–∞–∫. –¢–∞–∫–∂–µ –Ω–µ–æ–±—Ö–æ–¥–∏–º–æ –ø—Ä–æ—è—Å–Ω–∏—Ç—å —Ü–µ–ª–µ–≤–æ–π –∞–¥—Ä–µ—Å R3. –í–∞–Ω–≥—É—é, —á—Ç–æ R3 —É–∫–∞–∑—ã–≤–∞–µ—Ç –≤ —Ç–æ—Ç –∂–µ —Ä–µ–≥–∏–æ–Ω –ø–∞–º—è—Ç–∏, –≥–¥–µ –Ω–∞—Ö–æ–¥–∏—Ç—Å—è –∫–æ–¥. –û—Ç—Å—é–¥–∞ –∏ –ª–∏—à–Ω–∏–π —Ç–∞–∫—Ç.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
bob1
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç —Å–µ–Ω 12, 2025 14:25:33 |
|
| –ú—É—á–∏—Ç–µ–ª—å –º–∏–∫—Ä–æ—Å—Ö–µ–º |
–ö–∞—Ä–º–∞: 24
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 144
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –∏—é–Ω 08, 2011 20:25:20
–°–æ–æ–±—â–µ–Ω–∏–π: 450
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ü–æ—á–µ–º—É —Ç–∞–∫–æ–π –≤—ã–≤–æ–¥? –≠—Ç–æ –Ω–µ –≤—ã–≤–æ–¥, –∞ —É–±—Ä–∞—Ç—å –≤–æ–ø—Ä–æ—Å—ã –ø—Ä–æ –≤—Ä–µ–º—è –∑–∞–≥—Ä—É–∑–∫–∏ –∫–æ–º–∞–Ω–¥—ã –≤ –∫–æ–Ω–≤–µ–π–µ—Ä. –ü—Ä–æ –∫–µ—à, —É—Å–∫–æ—Ä–∏—Ç–µ–ª—å... –ö–∞–∫–æ–≤–∞ —à–∏—Ä–∏–Ω–∞ —à–∏–Ω—ã CPU, —á–∏—Ç–∞—é—â–µ–π –ø–æ—Ç–æ–∫ –∫–æ–º–∞–Ω–¥ –∏–∑ –¥–∞–Ω–Ω–æ–π –ø–∞–º—è—Ç–∏? 64. –ï—Å—Ç—å –ª–∏ –¥—Ä—É–≥–∏–µ bus-masters, —Ä–∞–±–æ—Ç–∞—é—â–∏–µ –≤ —ç—Ç–æ –≤—Ä–µ–º—è? –ù–µ—Ç. –¢–µ—Å—Ç–æ–≤–∞—è —Ñ—É–Ω–∫—Ü–∏—è –ø—Ä–∞–∫—Ç–∏—á–µ—Å–∫–∏ –≤ –Ω–∞—á–∞–ª–µ main. –ö–æ–¥: int main(void){
SCB->VTOR = CCMSRAM_BASE;
LL_APB2_GRP1_EnableClock(LL_APB2_GRP1_PERIPH_SYSCFG);
LL_APB1_GRP1_EnableClock(LL_APB1_GRP1_PERIPH_PWR);
LL_RCC_ForceBackupDomainReset();
LL_RCC_ReleaseBackupDomainReset();
LL_PWR_EnableBkUpAccess();
LL_PWR_DisableDeadBatteryPD();
test();
–ê –∫—É–¥–∞ —É–∫–∞–∑—ã–≤–∞–µ—Ç R3? –û—Ç–∫—É–¥–∞ –∏–¥—ë—Ç —á—Ç–µ–Ω–∏–µ? –í —Ç–µ—Å—Ç–æ–≤–æ–π —Ñ—É–Ω–∫—Ü–∏–∏ —ç–∫—Å–ø–µ—Ä–∏–º–µ–Ω—Ç–∏—Ä–æ–≤–∞–ª —á—Ç–µ–Ω–∏–µ —Å TIM4->CNT , GPIOA->IDR –∏ SRAM. –ù–∞–≤–µ—Ä—Ö—É –∫–æ–¥–∞ –≤—ã–±–∏—Ä–∞–µ—Ç—Å—è –≤ #define reg*. –ò –∫–∞–∫ –∏–º–µ–Ω–Ω–æ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ –∑–∞–º–µ—Ä –≤—Ä–µ–º–µ–Ω–∏ –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è —Ü–∏–∫–ª–∞? –ò–∑–º–µ–Ω—è—è n. –ö –ø—Ä–∏–º–µ—Ä—É –≤—ã–±–∏—Ä–∞—é n=6. –¢–∞–π–º–µ—Ä 4 —Å—á–∏—Ç–∞–µ—Ç –≤—Ä–µ–º—è –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–¥–∞. –£–≤–µ–ª–∏—á–∏–≤–∞—é n=7. –û–ø—è—Ç—å —Ç–∞–π–º–µ—Ä —Å—á–∏—Ç–∞–µ—Ç. –Ý–∞–∑–Ω–∏—Ü–∞ —Å—á–µ—Ç–æ–≤ –∏ –¥–∞–µ—Ç –≤—Ä–µ–º—è –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è —Ü–∏–∫–ª–∞. –£–≤–µ–ª–∏—á–∏–≤–∞—è n –Ω–∞ 1, —Ç–æ —Å—á–µ—Ç T–∞–π–º–µ—Ä–∞ 4 —Ä–∞—Å—Ç–µ—Ç –Ω–∞ –æ–¥–Ω—É –∏ —Ç—É–∂–µ –≤–µ–ª–∏—á–∏–Ω—É. –î–ª–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è LDR —Å–ª–µ–¥—É–µ—Ç –∏–∑–º–µ—Ä—è—Ç—å –Ω–µ —Ç–∞–∫. –ì–æ—Ç–æ–≤ –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å –∏ –≤–∞—à –∫–æ–¥. –í–∞–Ω–≥—É—é, —á—Ç–æ R3 —É–∫–∞–∑—ã–≤–∞–µ—Ç –≤ —Ç–æ—Ç –∂–µ —Ä–µ–≥–∏–æ–Ω –ø–∞–º—è—Ç–∏, –≥–¥–µ –Ω–∞—Ö–æ–¥–∏—Ç—Å—è –∫–æ–¥. –í –ø—Ä–∏–º–µ—Ä–µ –∫–æ–¥ –≤ –°–°–ú. –ö–æ–¥ –±—ã–ª –∏ –≤–æ —Ñ–ª–µ—à–∏ (–ø—Ä–∏ enable ICEN bit ). –Ý–µ–∑—É–ª—å—Ç–∞—Ç –æ–¥–∏–Ω–∞–∫–æ–≤—ã–π. –ß—Ç–µ–Ω–∏–µ –∫–æ–¥–∞ –∏ –ø–∞–º—è—Ç–∏ (–∫—É–¥–∞ —É–∫–∞–∑—ã–≤–∞–µ—Ç R3) –∏–¥–µ—Ç –ø–æ —Ä–∞–∑–Ω—ã–º —à–∏–Ω–∞–º.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
jcxz
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –ü—Ç —Å–µ–Ω 12, 2025 20:20:10 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
–ö–∞—Ä–º–∞: -7
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 181
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 15, 2017 10:51:13
–°–æ–æ–±—â–µ–Ω–∏–π: 1569
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
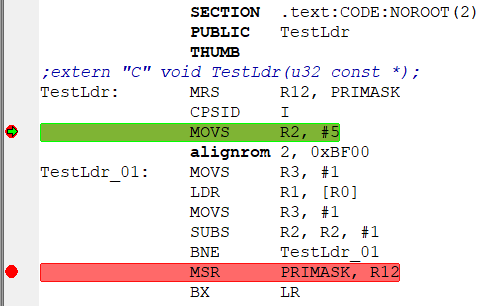
–ö–∞–∫–æ–≤–∞ —à–∏—Ä–∏–Ω–∞ —à–∏–Ω—ã CPU, —á–∏—Ç–∞—é—â–µ–π –ø–æ—Ç–æ–∫ –∫–æ–º–∞–Ω–¥ –∏–∑ –¥–∞–Ω–Ω–æ–π –ø–∞–º—è—Ç–∏? 64. –í –º–æ—ë–º —Ç–µ–∫—É—â–µ–º XMC4500 - —Å—Ç–æ–ª—å–∫–æ –∂–µ. –¢–æ—á–Ω–µ–µ - —ç—Ç–æ —à–∏—Ä–∏–Ω–∞ —à–∏–Ω—ã, —á–∏—Ç–∞—é—â–µ–π –∏–∑ –∫–µ—à–∞ –≤ –±—É—Ñ–µ—Ä –ø—Ä–µ–¥–≤—ã–±–æ—Ä–∫–∏. –®–∏—Ä–∏–Ω–∞ —à–∏–Ω –∫ –ø–∞–º—è—Ç–∏ - —Ä–∞–∑–Ω–∞—è, –≤ –∑–∞–≤–∏—Å–∏–º–æ—Å—Ç–∏ –æ—Ç —Ç–∏–ø–∞ –ø–∞–º—è—Ç–∏. Up to 256 –±–∏—Ç. –ò–∑–º–µ–Ω—è—è n. –ö –ø—Ä–∏–º–µ—Ä—É –≤—ã–±–∏—Ä–∞—é n=6. –¢–∞–π–º–µ—Ä 4 —Å—á–∏—Ç–∞–µ—Ç –≤—Ä–µ–º—è –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–¥–∞. –£–≤–µ–ª–∏—á–∏–≤–∞—é n=7. –û–ø—è—Ç—å —Ç–∞–π–º–µ—Ä —Å—á–∏—Ç–∞–µ—Ç. –Ý–∞–∑–Ω–∏—Ü–∞ —Å—á–µ—Ç–æ–≤ –∏ –¥–∞–µ—Ç –≤—Ä–µ–º—è –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è —Ü–∏–∫–ª–∞. –£–≤–µ–ª–∏—á–∏–≤–∞—è n –Ω–∞ 1, —Ç–æ —Å—á–µ—Ç T–∞–π–º–µ—Ä–∞ 4 —Ä–∞—Å—Ç–µ—Ç –Ω–∞ –æ–¥–Ω—É –∏ —Ç—É–∂–µ –≤–µ–ª–∏—á–∏–Ω—É. –ù–µ–∫–æ—Ä—Ä–µ–∫—Ç–Ω—ã–π –º–µ—Ç–æ–¥. –ù–µ —É—á–∏—Ç—ã–≤–∞–µ—Ç –≤–æ–∑–º–æ–∂–Ω–æ–≥–æ –≤—Ä–µ–º–µ–Ω–∏ –ø–µ—Ä–µ–∑–∞–≥—Ä—É–∑–∫–∏ –±—É—Ñ–µ—Ä–∞ –ø—Ä–µ–¥–≤—ã–±–æ—Ä–∫–∏ –ø—Ä–∏ –ø–µ—Ä–µ—Ö–æ–¥–µ. –¢–∞–∫–∂–µ –Ω–µ —É—á–∏—Ç—ã–≤–∞–µ—Ç—Å—è –Ω–µ–≤—ã—Ä–æ–≤–Ω–µ–Ω–Ω–æ—Å—Ç—å —Ü–µ–ª–µ–≤–æ–≥–æ –∞–¥—Ä–µ—Å–∞ –ø–µ—Ä–µ—Ö–æ–¥–∞. –ò –Ω–µ –≤–∏–∂—É –∑–∞–ø—Ä–µ—Ç–∞ –ø—Ä–µ—Ä—ã–≤–∞–Ω–∏–π –Ω–∞ –≤—Ä–µ–º—è —Ç–µ—Å—Ç–∞. –ì–æ—Ç–æ–≤ –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å –∏ –≤–∞—à –∫–æ–¥. –ö–æ–¥ (IAR): –ö–æ–¥: SECTION .text:CODE:NOROOT(2)
PUBLIC TestLdr
THUMB
;extern "C" void TestLdr(u32 const *);
TestLdr: MRS R12, PRIMASK
CPSID I
MOVS R2, #5
alignrom 2, 0xBF00
TestLdr_01: MOVS R3, #1
LDR R1, [R0]
MOVS R3, #1
SUBS R2, R2, #1
BNE TestLdr_01
MSR PRIMASK, R12
BX LR –í—ã–∑–æ–≤ –∏–∑ —Å–∏++: –ö–æ–¥: extern "C" void TestLdr(u32 const *);
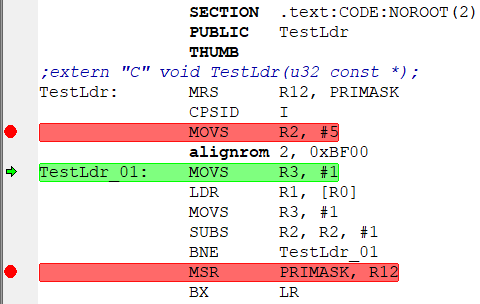
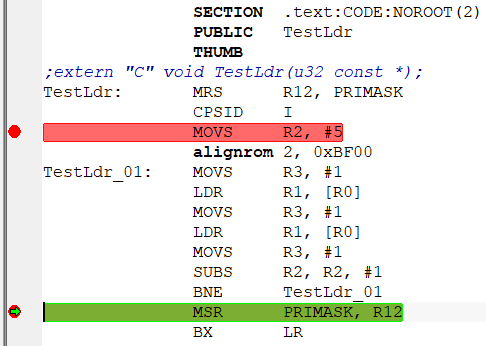
TestLdr((u32 const *)0x20000000); –¢–∞–π–º–µ—Ä—ã –¥–ª—è –∏–∑–º–µ—Ä–µ–Ω–∏—è —Ç–æ–∂–µ –Ω–µ –Ω—É–∂–Ω—ã - IAR (—É –≤–∞—Å –∂–µ –≤—Ä–æ–¥–µ IAR?) —Å–∞–º —É–º–µ–µ—Ç –∏–∑–º–µ—Ä—è—Ç—å –ø–æ –æ—Ç–ª–∞–¥–æ—á–Ω–æ–º—É —Ç–∞–π–º–µ—Ä—É DWT.CYCCNT. –°—Ç–∞–≤–∏–º –±—Ä—è–∫–∏ –∫–∞–∫ –Ω–∞ –∫–∞—Ä—Ç–∏–Ω–∫–µ –Ω–∏–∂–µ: 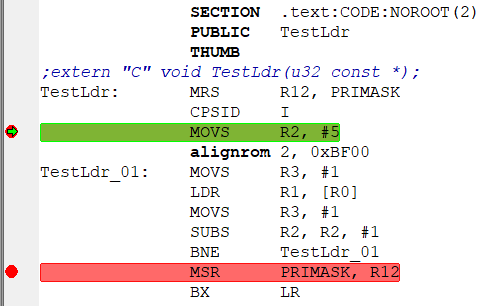 –ø–æ—Ç–æ–º –¥–µ–ª–∞–µ–º –æ–¥–∏–Ω —à–∞–≥ "step into" —á—Ç–æ–±—ã —Å–æ—Å–∫–æ—á–∏—Ç—å —Å –±—Ä—è–∫–∞ (—Ç–∞–∫ –∫–∞–∫ –Ω–∞ –Ω–µ–∫–æ—Ç–æ—Ä—ã—Ö –ú–ö –≤ –Ω–µ–∫–æ—Ç–æ—Ä—ã—Ö –ø–∞–º—è—Ç—è—Ö —ç—Ç–æ –¥–æ–±–∞–≤–ª—è–µ—Ç –ª–∏—à–Ω–∏–µ —Ç–∞–∫—Ç—ã (–ø—Ä–∏ soft-–±—Ä—è–∫–∞—Ö)): 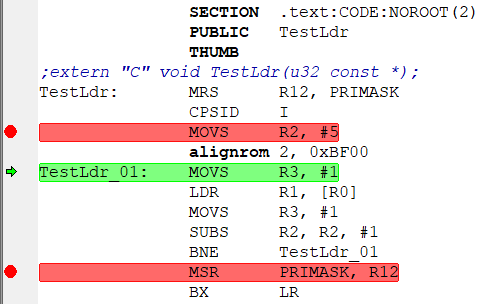 –ø–æ—Ç–æ–º –∂–º—ë–º "go". –û—Å—Ç–∞–Ω–∞–≤–ª–∏–≤–∞–µ—Ç—Å—è –Ω–∞ 2-–º –±—Ä—è–∫–µ, —Å–º–æ—Ç—Ä–∏–º –ø–æ–ª–µ "CCSTEP":  –î–µ–ª–∞–µ–º —Ä–µ—Å—Ç–∞—Ä—Ç –ú–ö, –ø–æ—Å–ª–µ "step into" –≤–≤–æ–¥–∏–º –≤ R2 –≤—Ä—É—á–Ω—É—é 4, "go", —Ä–µ–∑—É–ª—å—Ç–∞—Ç:  –ö–∞–∫ –≤–∏–¥–Ω–æ - —É –º–µ–Ω—è —Ä–∞–∑–Ω–∏—Ü–∞ —Å–æ—Å—Ç–∞–≤–∏–ª–∞ 34-27=7 —Ç–∞–∫—Ç–æ–≤. –°–ª–µ–¥–æ–≤–∞—Ç–µ–ª—å–Ω–æ - –¥–ª–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å LDR = 2 —Ç–∞–∫—Ç–∞. –ö–∞–∫ –∏ –æ–∂–∏–¥–∞–ª–æ—Å—å. –ò –Ω–µ—Ç –≤–ª–∏—è–Ω–∏—è –≤—Ä–µ–º–µ–Ω–∏ –ø–µ—Ä–µ–∑–∞–≥—Ä—É–∑–∫–∏ –±—É—Ñ–µ—Ä–∞ –ø—Ä–µ–¥–≤—ã–±–æ—Ä–∫–∏ –ø—Ä–∏ –ø–µ—Ä–µ—Ö–æ–¥–µ –ø–æ BNE. –ú–æ–∂–Ω–æ –µ—â—ë —É–ª—É—á—à–∏—Ç—å —Ç–µ—Å—Ç. –ò—Å–∫–ª—é—á–∏–≤ –≤–æ–∑–º–æ–∂–Ω–æ–µ –≤–ª–∏—è–Ω–∏–µ –ø–µ—Ä–µ–∑–∞–≥—Ä—É–∑–∫–∏ –±—É—Ñ–µ—Ä–∞ –ø—Ä–µ–¥–≤—ã–±–æ—Ä–∫–∏. –ü–æ—Å–ª–µ –ø–µ—Ä–≤–æ–π –ø–∞—Ä—ã LDR/MOVS –¥–æ–±–∞–≤–ª—è–µ–º 2-—é —Ç–∞–∫—É—é –∂–µ –ø–∞—Ä—É: 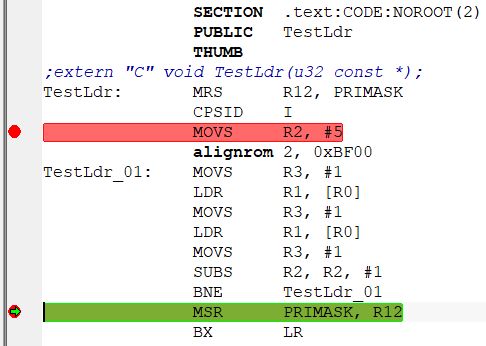 –î–µ–ª–∞–µ–º —Ç–µ—Å—Ç (—Å —Ç–µ–º –∂–µ —á–∏—Å–ª–æ–º –ø—Ä–æ—Ö–æ–¥–æ–≤). –£ –º–µ–Ω—è –ø–æ–ª—É—á–∏–ª–æ—Å—å == 49 —Ç–∞–∫—Ç–æ–≤:  –°—á–∏—Ç–∞–µ–º (49-34)/5¬Ý=¬Ý3 —Ç–∞–∫—Ç–∞ –¥–æ–±–∞–≤–∏–ª–æ—Å—å. –¢–æ–∂–µ - –∫–∞–∫ –∏ –æ–∂–∏–¥–∞–ª–æ—Å—å. –í –º–æ–∏—Ö —Ç–µ—Å—Ç–∞—Ö 0x20000000 - –∞–¥—Ä–µ—Å –Ω–∞—á–∞–ª–∞ –æ–¥–Ω–æ–≥–æ –∏–∑ —Ä–µ–≥–∏–æ–Ω–æ–≤ –û–ó–£. –ö–æ–¥ –≤—ã–ø–æ–ª–Ω—è–µ—Ç—Å—è –∏–∑ –¥—Ä—É–≥–æ–≥–æ —Ä–µ–≥–∏–æ–Ω–∞ –û–ó–£ (0x10000000). –î–æ–±–∞–≤–ª–µ–Ω–æ after 7 minutes 19 seconds:PS: –ö–æ–¥: // 1113 while (n--!=0) ;
MOV R0,R1
SUBS R1,R0,#+1
CMP R0,#+0
BNE.N ??test_1 –ï—Å–ª–∏ —Ü–µ–ª—å - –ø–∏—Å–∞—Ç—å –æ–ø—Ç–∏–º–∞–ª—å–Ω–æ, —Ç–æ —ç—Ç–æ –ø–ª–æ—Ö–∞—è –æ—Ä–≥–∞–Ω–∏–∑–∞—Ü–∏—è —Ü–∏–∫–ª–∞. –ò—Å–ø–æ–ª—å–∑—É—è –ø–æ—Å—Ç—Ñ–∏–∫—Å–Ω—É—é –æ–ø–µ—Ä–∞—Ü–∏—é –¥–µ–∫—Ä–µ–º–µ–Ω—Ç–∞, –≤—ã –Ω–µ –¥–∞—ë—Ç–µ –∫–æ–º–ø–∏–ª—è—Ç–æ—Ä—É –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å —Ñ–ª–∞–≥–∏ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞ –∫–æ–º–∞–Ω–¥—ã SUBS, –∑–∞—Å—Ç–∞–≤–ª—è—è –µ–≥–æ –¥–æ–±–∞–≤–ª—è—Ç—å –Ω–µ–Ω—É–∂–Ω—É—é CMP. –õ—É—á—à–µ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –ø—Ä–µ—Ñ–∏–∫—Å–Ω—ã–π –¥–µ–∫—Ä–µ–º–µ–Ω—Ç: –ö–æ–¥: int n = N; do { ... } while (--n); –∏–ª–∏ –ö–æ–¥: int n = N - 1; do { ... } while (--n >= 0); –≤ —ç—Ç–∏—Ö —Å–ª—É—á–∞—è—Ö –±—É–¥–µ—Ç –æ–¥–Ω–∞ –∫–æ–º–∞–Ω–¥–∞ SUBS –∑–∞ –∫–æ—Ç–æ—Ä–æ–π —Å—Ä–∞–∑—É BNE. –•–æ—Ç—è –¥–ª—è —Ü–µ–ª–µ–π –∏–∑–º–µ—Ä–µ–Ω–∏—è –≤—Ä–µ–º–µ–Ω–∏ –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è –∫–æ–º–∞–Ω–¥—ã —Ç—É—Ç –∫–æ–Ω–µ—á–Ω–æ –≤—Å—ë —Ä–∞–≤–Ω–æ.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
bob1
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å —Å–µ–Ω 14, 2025 08:29:20 |
|
| –ú—É—á–∏—Ç–µ–ª—å –º–∏–∫—Ä–æ—Å—Ö–µ–º |
–ö–∞—Ä–º–∞: 24
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 144
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –∏—é–Ω 08, 2011 20:25:20
–°–æ–æ–±—â–µ–Ω–∏–π: 450
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
|
–Ý–∞–∑–æ–±—Ä–∞–ª—Å—è —á–∞—Å—Ç–∏—á–Ω–æ. –í—ã–≤–æ–¥: –∫–µ—à –∏–Ω—Å—Ç—Ä—É–∫—Ü–∏–π –≤–∫–ª—é—á–µ–Ω, –∏–Ω—Å—Ç—Ä—É–∫—Ü–∏–∏ –¥–æ–ª–∂–Ω—ã –∑–∞–≥—Ä—É–∂–∞—Ç—å—Å—è –ø–æ I-bus, –¥–∞–Ω–Ω—ã–µ –ø–æ D-bus. –ó–∞–≥—Ä—É–∑–∫–∞ –ø–æ S-bus –¥–æ–±–∞–≤–ª—è–µ—Ç 1 —Ç–∞–∫—Ç –≤ –ª—É—á—à–µ–º —Å–ª—É—á–∞–µ –∏ –ø–æ–ª—É—á–∞–µ—Ç—Å—è, —á—Ç–æ —Å –ø–µ—Ä–∏—Ñ–µ—Ä–∏–∏ –¥–∞–Ω–Ω—ã–µ —Å—á–∏—Ç—ã–≤–∞—é—Ç—Å—è –∑–∞ 3 —Ç–∞–∫—Ç–∞.
–∑.—ã. –í–æ–ø—Ä–æ—Å—ã –ø–æ —Ä–∞—Å–ø–æ–ª–æ–∂–µ–Ω–∏—é –∫–æ–¥–∞ (—Ü–∏–∫–ª–∞) –µ—â–µ –æ—Å—Ç–∞–ª–∏—Å—å. –ü–æ—Ç–æ–º –µ—â–µ –ø–æ—ç–∫—Å–ø–µ—Ä–∏–º–µ–Ω—Ç–∏—Ä—É—é.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
–Ý–µ–∫–ª–∞–º–∞
|
|
|
|
|
|
|
|
|
|
jcxz
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å —Å–µ–Ω 14, 2025 15:13:27 |
|
| –ì–æ–≤–æ—Ä—è—â–∏–π —Å —Ç–µ–∫—Å—Ç–æ–ª–∏—Ç–æ–º |
–ö–∞—Ä–º–∞: -7
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 181
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –í—Ç –∞–≤–≥ 15, 2017 10:51:13
–°–æ–æ–±—â–µ–Ω–∏–π: 1569
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
—Å –ø–µ—Ä–∏—Ñ–µ—Ä–∏–∏ –¥–∞–Ω–Ω—ã–µ —Å—á–∏—Ç—ã–≤–∞—é—Ç—Å—è –∑–∞ 3 —Ç–∞–∫—Ç–∞. –Ý–∞–Ω–µ–µ –≤—ã –ø–∏—Å–∞–ª–∏, —á—Ç–æ —á–∏—Ç–∞–µ—Ç–µ –∏–∑ –ø–∞–º—è—Ç–∏: –ß—Ç–µ–Ω–∏–µ –∫–æ–¥–∞ –∏ –ø–∞–º—è—Ç–∏ (–∫—É–¥–∞ —É–∫–∞–∑—ã–≤–∞–µ—Ç R3) –ü–æ—á–µ–º—É —Å—Ä–∞–∑—É –∏ —Å–ø—Ä–∞—à–∏–≤–∞–ª –≤–∞—Å "–æ—Ç–∫—É–¥–∞ —á–∏—Ç–∞–µ—Ç–µ?" –ü—Ä–∏ —á—Ç–µ–Ω–∏–∏ –∏–∑ –ø–µ—Ä–∏—Ñ–µ—Ä–∏–∏ –µ—Å—Ç—å –º–Ω–æ–≥–æ –≤–ª–∏—è—é—â–∏—Ö –Ω–∞ —á—Ç–µ–Ω–∏–µ —Ñ–∞–∫—Ç–æ—Ä–æ–≤: –∫–∞–∫–∞—è –∏–º–µ–Ω–Ω–æ –ø–µ—Ä–∏—Ñ–µ—Ä–∏—è? –Ω–∞ –∫–∞–∫–æ–π —à–∏–Ω–µ (AHB, APB1, APB2 - –¥–ª—è STM32)? –∫–∞–∫–æ–≤–∞ —á–∞—Å—Ç–æ—Ç–∞ —à–∏–Ω—ã? –î–∞–∂–µ —É —Ä–∞–∑–Ω–æ–π –ø–µ—Ä–∏—Ñ–µ—Ä–∏–∏, –Ω–∞—Ö–æ–¥—è—â–µ–π—Å—è –Ω–∞ –æ–¥–Ω–æ–π —à–∏–Ω–µ, –¥–ª–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å —á—Ç–µ–Ω–∏—è –º–æ–∂–µ—Ç –±—ã—Ç—å —Ä–∞–∑–Ω–æ–π. –ö —Å–∫–æ—Ä–æ—Å—Ç–∏ –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è LDR —ç—Ç–æ –Ω–µ –∏–º–µ–µ—Ç –æ—Ç–Ω–æ—à–µ–Ω–∏—è. –ü–µ—Ä–∏—Ñ–µ—Ä–∏—è –º–æ–∂–µ—Ç –¥–æ–ª–≥–æ –Ω–µ —Å—Ç–∞–≤–∏—Ç—å ready-—Å–∏–≥–Ω–∞–ª, –∑–∞–º–æ—Ä–∞–∂–∏–≤–∞—è CPU. PS: –ò–Ω–æ–≥–¥–∞ (–Ω–∞ –Ω–µ–∫–æ—Ç–æ—Ä—ã—Ö –ú–ö) –ø–æ–º–æ–≥–∞–µ—Ç —Ä–∞–±–æ—Ç–∞ —á–µ—Ä–µ–∑ bit-band –æ–±–ª–∞—Å—Ç—å (–µ—Å–ª–∏ –æ–Ω–∞ –µ—Å—Ç—å –≤ –ú–ö). –ù–∞ –º–æ–∏—Ö STM32 (STM32F4xx, STM32F1xx) —Ä–∞–±–æ—Ç–∞ —Å GPIO-–ø–æ—Ç–∞–º–∏ —á–µ—Ä–µ–∑ bit-band - –∑–∞–º–µ—Ç–Ω–æ –±—ã—Å—Ç—Ä–µ–µ, —á–µ–º —á–µ—Ä–µ–∑ –∏—Ö —Ä–µ–≥–∏—Å—Ç—Ä—ã. –ï—Å–ª–∏ –ø–æ–¥—Ö–æ–¥–∏—Ç - –º–æ–∂–Ω–æ –ø–æ–ø—Ä–æ–±–æ–≤–∞—Ç—å –ø–µ—Ä–µ–ø–∏—Å–∞—Ç—å —Ä–∞–±–æ—Ç—É –Ω–∞ bit-band –∏ –ø—Ä–æ–≤–µ—Ä–∏—Ç—å.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
bob1
|
–ó–∞–≥–æ–ª–æ–≤–æ–∫ —Å–æ–æ–±—â–µ–Ω–∏—è: Re: –ê—Å—Å–µ–º–±–ª–µ—Ä –¥–ª—è STM32. –°–ª–æ–∂–Ω–æ –ª–∏, —Å—Ç–æ–∏—Ç –ª–∏ –ø—ã—Ç–∞—Ç—å—Å—è? –î–æ–±–∞–≤–ª–µ–Ω–æ: –í—Å —Å–µ–Ω 14, 2025 18:47:33 |
|
| –ú—É—á–∏—Ç–µ–ª—å –º–∏–∫—Ä–æ—Å—Ö–µ–º |
–ö–∞—Ä–º–∞: 24
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π: 144
–ó–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω: –°—Ä –∏—é–Ω 08, 2011 20:25:20
–°–æ–æ–±—â–µ–Ω–∏–π: 450
–Ý–µ–π—Ç–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏—è: 0
|
–ü–æ—á–µ–º—É —Å—Ä–∞–∑—É –∏ —Å–ø—Ä–∞—à–∏–≤–∞–ª –≤–∞—Å "–æ—Ç–∫—É–¥–∞ —á–∏—Ç–∞–µ—Ç–µ?" –ú–µ–Ω—è –∏–Ω—Ç–µ—Ä–µ—Å–æ–≤–∞–ª–∞ –Ω–µ –∫–æ–Ω–∫—Ä–µ—Ç–Ω–∞—è –∑–∞–¥–∞—á–∞, –∞ –æ–±—â–∏–π —Å–ª—É—á–∞–π. –ü—Ä–æ–±–æ–≤–∞–ª –∏ –∫–æ–¥ –≤ —Å—Å–º –∏ —á–∏—Ç–∞–ª ram —Å –∞–¥—Ä–µ—Å–∞ 0x20000000. –≠—Ç–æ –±—ã–ª–æ –≤ –¥–µ–∫–∞–±—Ä–µ. –ö–æ–¥ —Ç–æ–≥–¥–∞ —Å–¥–µ–ª–∞–ª "3 —Ç–∞–∫—Ç–∞—Ö". –ü—Ä–æ—Å—Ç–æ –ø—Ä–∏—à–ª–æ—Å—å –±–æ–ª—å—à–µ —Å—Ç—ã–∫–æ–≤–∞—Ç—å –¥—Ä—É–≥ –¥—Ä—É–≥—É –∫–æ–º–∞–Ω–¥ —á—Ç–µ–Ω–∏—è –∏ –∑–∞–ø–∏—Å–∏. –¢–æ–≥–¥–∞ –∏ –≤–æ–∑–Ω–∏–∫ –≤–æ–ø—Ä–æ—Å –ø—Ä–æ —á—Ç–µ–Ω–∏–µ –ø–æ 2-–º —Ç–∞–∫—Ç–∞–º. –°–µ–π—á–∞—Å —Å–æ–∑—Ä–µ–ª –∑–∞–¥–∞—Ç—å –µ–≥–æ  –∫–∞–∫–∞—è –∏–º–µ–Ω–Ω–æ –ø–µ—Ä–∏—Ñ–µ—Ä–∏—è? ADC-—Ä–µ–∑—É–ª—å—Ç–∞—Ç. AHB2, –¥–µ–ª–∏—Ç–µ–ª—è –Ω–µ—Ç. –ß–∞—Å—Ç–æ—Ç–∞ 32–ú–ì—Ü —Ç–∞–∫–∞—è –∂–µ –∫–∞–∫ —É —è–¥—Ä–∞ SYSCLK. ADC —Ç–∞–∫—Ç–∏—Ä—É–µ—Ç—Å—è –±–µ–∑ –¥–µ–ª–µ–Ω–∏—è. bit-band –í–æ–∑—å–º—É –Ω–∞ –∑–∞–º–µ—Ç–∫—É. –ù—É–∂–Ω–æ –±—ã–ª–æ —á—Ç–µ–Ω–∏–µ –≤—Å–µ–≥–æ —Å–ª–æ–≤–∞. –º–æ–∂–Ω–æ –ø–æ–ø—Ä–æ–±–æ–≤–∞—Ç—å –ø–µ—Ä–µ–ø–∏—Å–∞—Ç—å —Ä–∞–±–æ—Ç—É –Ω–∞ –∏ –ø—Ä–æ–≤–µ—Ä–∏—Ç—å. –°–µ–π—á–∞—Å –∑–∞–≤–∞–ª. –ö —Å–∫–æ—Ä–æ—Å—Ç–∏ –≤—ã–ø–æ–ª–Ω–µ–Ω–∏—è LDR —ç—Ç–æ –Ω–µ –∏–º–µ–µ—Ç –æ—Ç–Ω–æ—à–µ–Ω–∏—è –ï—Å–ª–∏ —Ç–∞–∫, —Ç–æ –µ—â–µ –ø–æ–ø—Ä–æ–±—É—é –ø–æ–∏–≥—Ä–∞—Ç—å—Å—è, –Ω–æ –ø–æ–∑–∂–µ..... –∑.—ã. –°–ø–∞—Å–∏–±–æ –∑–∞ –∏–¥–µ–∏. –Ý–µ–∑—É–ª—å—Ç–∞—Ç "2 —Ç–∞–∫—Ç–∞" –ø–æ–ª—É—á–∏–ª.
|
|
| –í–µ—Ä–Ω—É—Ç—å—Å—è –Ω–∞–≤–µ—Ä—Ö |
|
|
|
|
–°—Ç—Ä–∞–Ω–∏—Ü–∞ 15 –∏–∑ 15
|
[ –°–æ–æ–±—â–µ–Ω–∏–π: 291 ] |
... , , , , |
–ö—Ç–æ —Å–µ–π—á–∞—Å –Ω–∞ —Ñ–æ—Ä—É–º–µ |
–°–µ–π—á–∞—Å —ç—Ç–æ—Ç —Ñ–æ—Ä—É–º –ø—Ä–æ—Å–º–∞—Ç—Ä–∏–≤–∞—é—Ç: –Ω–µ—Ç –∑–∞—Ä–µ–≥–∏—Å—Ç—Ä–∏—Ä–æ–≤–∞–Ω–Ω—ã—Ö –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π –∏ –≥–æ—Å—Ç–∏: 9 |
|
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –Ω–∞—á–∏–Ω–∞—Ç—å —Ç–µ–º—ã
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –æ—Ç–≤–µ—á–∞—Ç—å –Ω–∞ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ —É–¥–∞–ª—è—Ç—å —Å–≤–æ–∏ —Å–æ–æ–±—â–µ–Ω–∏—è
–í—ã –Ω–µ –º–æ–∂–µ—Ç–µ –¥–æ–±–∞–≤–ª—è—Ç—å –≤–ª–æ–∂–µ–Ω–∏—è
|
|
|