Re: Ассемблер для STM32. Сложно ли, стоит ли пытаться?
Добавлено: Вс янв 03, 2021 23:21:05
Я же всё показал. Сравнивай сам.
Здесь можно немножко помяукать :)
https://radiokot.ru/forum/
Любую идею можно довести до маразма. Слать можно отдельные регионы картинки/небольшие иконки/инициализацию дисплея/etc и размер может быть вменяемым. Кстати и ряд других коммуникаций недурно смотрится в виде make packet -> queue send, а пока оно там send можно чем-то еще заняться. И если там всякое сжатие, ну тогда после decompress и "prepare buffer" из вон того куска наверное ок? А какие еще варианты? Если контроллер шины есть то все просто, но он только в очень разлапистых камнях, они дорогие и роутить печатку заманаешься, в общем это сразу повышает планку. А без него вообще какие варианты? Софтом ногодрыгать? Так это вообще блокирующая операция, на ее время проц недееспособен толком (минус IRQ). А, ну еще RTOS можно, но я не знаю как там с таймингами шины будет, в такие дебри я лезть не собираюсь. Мне от MK нужен нижний уровень и предсказуемость, а не высокие абстракции.Если хранить картинку 256*256 точек, да в добавок в цветном изображении, параллельный порт 8 пинов, 256*256*3*32 = 6.291.456 байт.?
Есть варианты когда можно совсем без кода. Типа quasi-hardware PWM, когда целый порт ворочается закольцованым DMA без вмешательства софта вообще. Это будет работать даже если процессорное ядро встрянет. Правда оно тогда не сможет параметры подкручивать, но если это не требовалось, то там целиком железки без участия процессора смогут все сделать.Ну как так можно без кода обойтись? Ведь еще сжать картинку можно, без кода ни как.
1 пин не эффективно по КПД операции. Оно может ВЕСЬ ПОРТ за транзакцию кантовать. Но да, это потребует определенных компромиссов. Оптимальнее всего выделить весь порт под такое развлечение. А почему бы хардвару не сделать хардвару и софту удобно и быстро?. И да, data -> ODR будет с КПД вплоть до 100%. В BSRR только до 50%, битов в 2 раза больше. Зато есть latch, можно только некоторые биты ворочать. Это даже может сосуществовать с некоторой периферией - AFIO в общем случае не очень интересует что там GPIO пытался вообще изобразить. А какое дело какому-нибудь uart input'у до его бита в ODR?Значит дма будем запускать только на один пин, а в прерывании выключать канал,
Вы кажется не поняли. Суть идеи: в RAM или Flash заводится буфер. Он описывает sequencing группы пинов. Типа эволюции состояния порта во времени. И конечно же трансферов при этом должно быть уж точно не 1. Иначе нахрена б такое счастье с сетапом DMA. И да, поскольку DMA отпускает шину чтобы процу что-то дать, он рекорд скорости может и не поставит. Но есть одна killer feature. Мы можем "зарядить отправку пакета" или даже "закольцевать отправку буфера" - и заняться своими делами! DMA асинхронен относительно кода проца. Так что основной профит - в асинхронщине этого относительно процессора и подпертости железом. А отсутствие трафика кода по шинам для этой активности - приятный побочный эффект, DMA не процессор, ему для ворочания порции данных не надо инструкции по шине гонять. Если хочется именно 1 бит, именно DMA, ну, не знаю, SPI какой поюзайте, чтоли. Он видите ли десереализует то что в него вгрузили, так КПД операции сильно интереснее, а послать опять же можно "целый пакет" и даже, вероятно, закольцевать, если это за каким-то чертом надо.А теперь вопрос в практическом применении, для чего и за чем? И где тут выигрыш в скорости?
Код: Выделить всё
/*
#define reg (uint32_t) TIM4->CNT
#define reg1 (uint32_t) TIM4->CNT
#define reg2 (uint32_t) TIM4->CNT
#define reg3 (uint32_t) TIM4->CNT
*/
#define reg (uint32_t) GPIOA->IDR
#define reg1 (uint32_t) GPIOA->IDR
#define reg2 (uint32_t) GPIOA->IDR
#define reg3 (uint32_t) GPIOA->IDR
/*
#define reg bx[0]
#define reg1 bx[1]
#define reg2 bx[2]
#define reg3 bx[3]
*/
__root uint32_t bx[]={1,2,3,4};
__root uint32_t res;
void test (void)@".ccmram"{
LL_APB1_GRP1_EnableClock(LL_APB1_GRP1_PERIPH_TIM4);
LL_DBGMCU_APB1_GRP1_FreezePeriph(LL_DBGMCU_APB1_GRP1_TIM4_STOP);
LL_TIM_InitTypeDef TIM_InitStruct = {0};
TIM_InitStruct.Autoreload = 0xFFFFFFFFU;
LL_TIM_Init(TIM4, &TIM_InitStruct);
uint32_t n=6;
uint32_t w,w1;
TIM4->CR1=1;
//--------------------------
do{
w=reg;
w1=w1+w;
w= reg1;
w1=w1+w;
w= reg2;
w1=w1+w;
w= reg3;
w1=w1+w;
}
while (n--!=0) ;
//--------------------------
res=w1;
TIM4->CR1=0;
};Код: Выделить всё
// 1102 //--------------------------
// 1103 do{
// 1104 w=reg;
??test_1:
LDR R0,[R3, #+0]
// 1105 w1=w1+w;
ADDS R2,R0,R2
// 1106 w= reg1;
LDR R0,[R3, #+0]
// 1107 w1=w1+w;
ADDS R2,R0,R2
// 1108 w= reg2;
LDR R0,[R3, #+0]
// 1109 w1=w1+w;
ADDS R2,R0,R2
// 1110 w= reg3;
LDR R0,[R3, #+0]
// 1111 w1=w1+w;
ADDS R2,R0,R2
// 1112 }
// 1113 while (n--!=0) ;
MOV R0,R1
SUBS R1,R0,#+1
CMP R0,#+0
BNE.N ??test_1
// 1114 //-------------------------- Код: Выделить всё
int main(void){
SCB->VTOR = CCMSRAM_BASE;
LL_APB2_GRP1_EnableClock(LL_APB2_GRP1_PERIPH_SYSCFG);
LL_APB1_GRP1_EnableClock(LL_APB1_GRP1_PERIPH_PWR);
LL_RCC_ForceBackupDomainReset();
LL_RCC_ReleaseBackupDomainReset();
LL_PWR_EnableBkUpAccess();
LL_PWR_DisableDeadBatteryPD();
test();
Код: Выделить всё
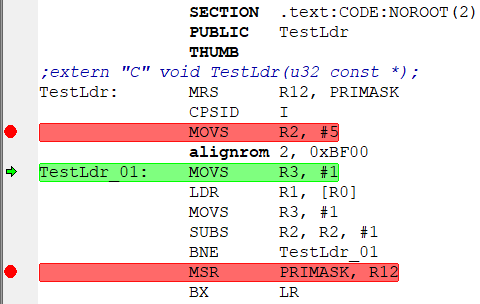
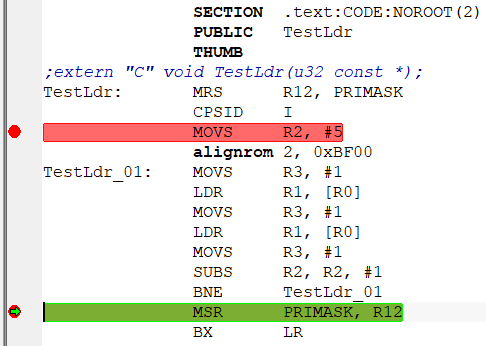
SECTION .text:CODE:NOROOT(2)
PUBLIC TestLdr
THUMB
;extern "C" void TestLdr(u32 const *);
TestLdr: MRS R12, PRIMASK
CPSID I
MOVS R2, #5
alignrom 2, 0xBF00
TestLdr_01: MOVS R3, #1
LDR R1, [R0]
MOVS R3, #1
SUBS R2, R2, #1
BNE TestLdr_01
MSR PRIMASK, R12
BX LRКод: Выделить всё
extern "C" void TestLdr(u32 const *);
TestLdr((u32 const *)0x20000000);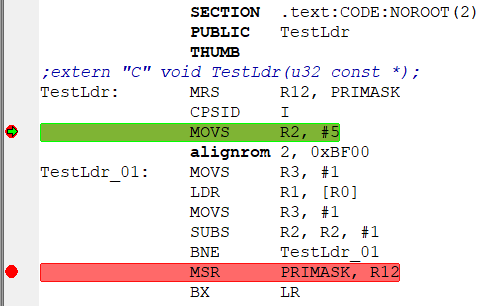



Код: Выделить всё
// 1113 while (n--!=0) ;
MOV R0,R1
SUBS R1,R0,#+1
CMP R0,#+0
BNE.N ??test_1Код: Выделить всё
int n = N; do { ... } while (--n);Код: Выделить всё
int n = N - 1; do { ... } while (--n >= 0);А что тогда делать? "С" - он же намного сложнее асма, я его просто не осилю.[/uquote] Для STM Си не очень страшний,освой указатели массивы, циклы и тебе хватить такого наваять, если канечно ты не будешь туда операционку пихать.NStorm писал(а):Пытаться разбираться не стоит. Писать на асме бесперспективно
Это действительно отличный вариант оптимизации. Заодно я узнал наконец-то, чем живут сишники.Reflector писал(а): Пт дек 04, 2020 16:45:37 Сравнивали много раз, C++ вариант ногодрыжной либы самый умный и эффективный, оптимизирует как на уровне пинов, так и на уровне работы с регистрами. В качестве иллюстрации, вот так выглядит одна из функций оптимизации:Спойлер
Код: Выделить всё
template<uint32_t Mask> static void _inline_ writeReg32(volatile uint32_t* reg, uint32_t value) { using vu8 = volatile uint8_t*; using vu16 = volatile uint16_t*; if constexpr (Mask == 0xFFFF'FFFF) *reg = value; else if constexpr (Mask == 0x0000'FFFF) *vu16(reg) = value; else if constexpr (Mask == 0xFFFF'0000) *(vu16(reg) + 1) = value >> 16; else if constexpr (Mask == 0x0000'00FF) *vu8(reg) = value; else if constexpr (Mask == 0x0000'FF00) *(vu8(reg) + 1) = value >> 8; else if constexpr (Mask == 0x00FF'0000) *(vu8(reg) + 2) = value >> 16; else if constexpr (Mask == 0xFF00'0000) *(vu8(reg) + 3) = value >> 24; else if constexpr (!(Mask & 0xFFFF'00FF)) *(vu8(reg) + 1) = (Mask == value) ? *(vu8(reg) + 1) | value >> 8 : *(vu8(reg) + 1) & ~(Mask >> 8) | value >> 8; else if constexpr (!(Mask & 0xFF00'FFFF)) *(vu8(reg) + 2) = (Mask == value) ? *(vu8(reg) + 2) | value >> 16 : *(vu8(reg) + 2) & ~(Mask >> 16) | value >> 16; else if constexpr (!(Mask & 0x00FF'FFFF)) *(vu8(reg) + 3) = (Mask == value) ? *(vu8(reg) + 3) | value >> 24 : *(vu8(reg) + 3) & ~(Mask >> 24) | value >> 24; else if constexpr (!(Mask & 0xFFFF'0000)) *vu16(reg) = (Mask == value) ? *vu16(reg) | value : *vu16(reg) & ~Mask | value; else if constexpr (!(Mask & 0x0000'FFFF)) *(vu16(reg) + 1) = (Mask == value) ? *(vu16(reg) + 1) | value >> 16 : *(vu16(reg) + 1) & ~(Mask >> 16) | value >> 16; else *reg = *reg & ~Mask | value; }
Код мог быть оптимальнее, если бы обработал pc7-pc3=>pb1-pb5 как отдельную группуVladislavS писал(а): Пн дек 07, 2020 12:24:25 Берём две группы пинов на разных портах. Читаем одну группу как байт, инвертируем и записываем во вторую группу.Сколько вы это будете руками ковырять... Компилятор делает за долю секунды.Код: Выделить всё
PinList<PC7, PC6, PC5, PC4, PC3, PA0, PA1, PA5> pins1; PinList<PB1, PB2, PB3, PB4, PB5, PD5, PD1, PD0> pins2; pins2 = ~pins1;Спойлер
Код: Выделить всё
//pins2 = ~pins1; LDR.N R1,??DataTable1_4 ;; 0x48000010 LDR R2,[R1, #+2048] LDR R3,[R1, #+0] AND R3,R3,#0x23 AND R2,R2,#0xF8 ORR R2,R2,R3, LSR #+5 AND R0,R3,#0x2 LSLS R3,R3,#+2 ORRS R2,R0,R2 AND R3,R3,#0x4 ORRS R2,R3,R2 MVNS R2,R2 AND R3,R2,#0xF8 RBIT R0,R3 LSRS R0,R0,#+23 AND R0,R0,#0x3E ORR R0,R0,#0x3E0000 STR R0,[R1, #+1032] AND R0,R2,#0x3 LSLS R2,R2,#+3 AND R2,R2,#0x20 ORRS R2,R2,R0 ORR R2,R2,#0x230000 STR R2,[R1, #+3080]