|
ążąŠčĆčāą╝ ąĀą░ą┤ąĖąŠąÜąŠčé • ą¤čĆąŠčüą╝ąŠčéčĆ č鹥ą╝čŗ - ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ
ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą▒ąĄąĘ ąŠčéą▓ąĄč鹊ą▓ | ąÉą║čéąĖą▓ąĮčŗąĄ č鹥ą╝čŗ
 
|
ąĪčéčĆą░ąĮąĖčåą░ 1 ąĖąĘ 3
|
[ ąĪąŠąŠą▒čēąĄąĮąĖą╣: 55 ] |
, , |
| ąÉą▓č鹊čĆ |
ąĪąŠąŠą▒čēąĄąĮąĖąĄ |
Paguo-86PK

|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ  ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 07:08:47 |
|
| ą×ą┐čŗčéąĮčŗą╣ ą║ąŠčé |
 |
ąÜą░čĆą╝ą░: 15
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 16
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¦čé ą░ą▓ą│ 19, 2010 23:49:19
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 803
ą×čéą║čāą┤ą░: ąóą░čłą║ąĄąĮčé
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
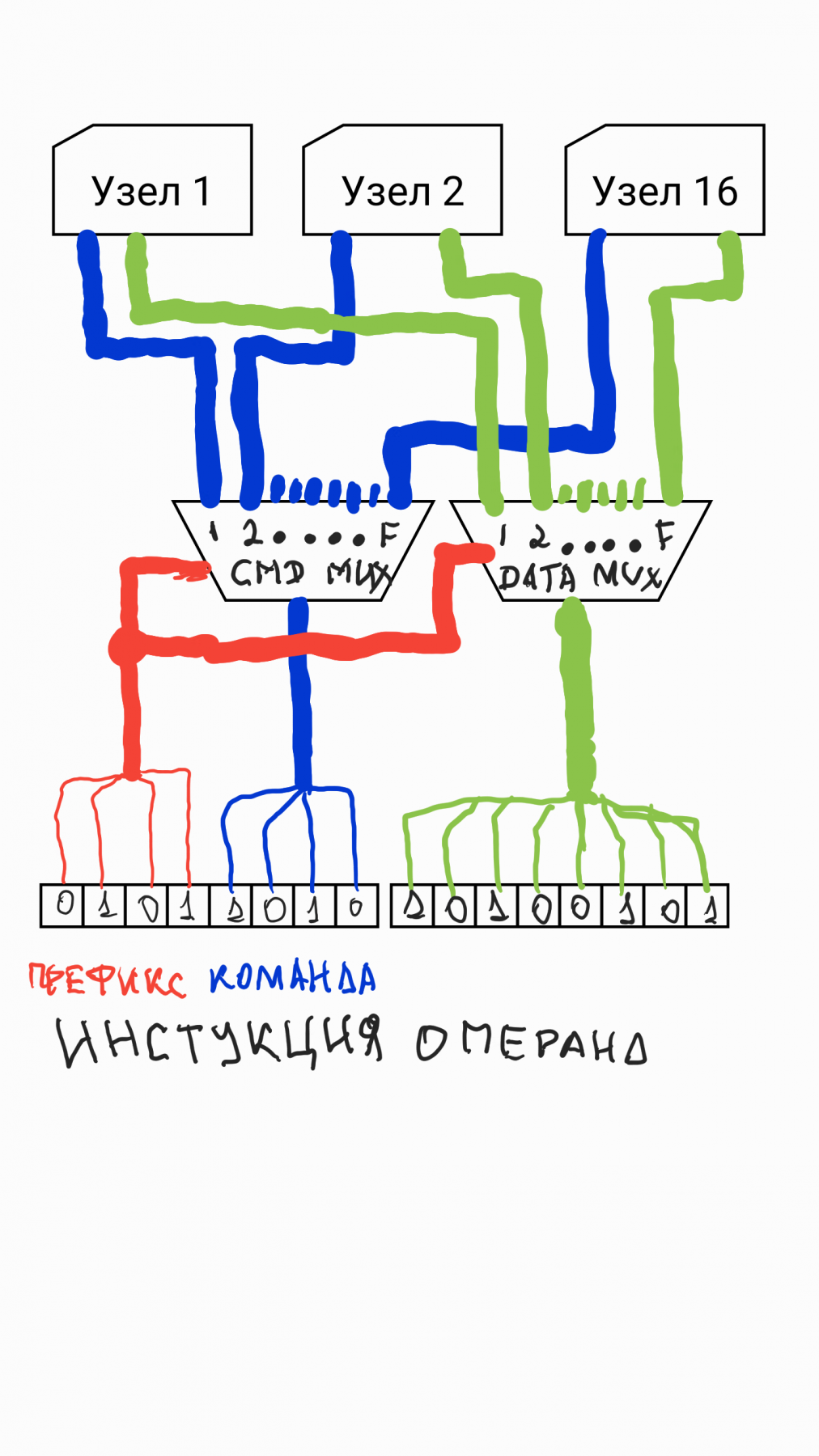
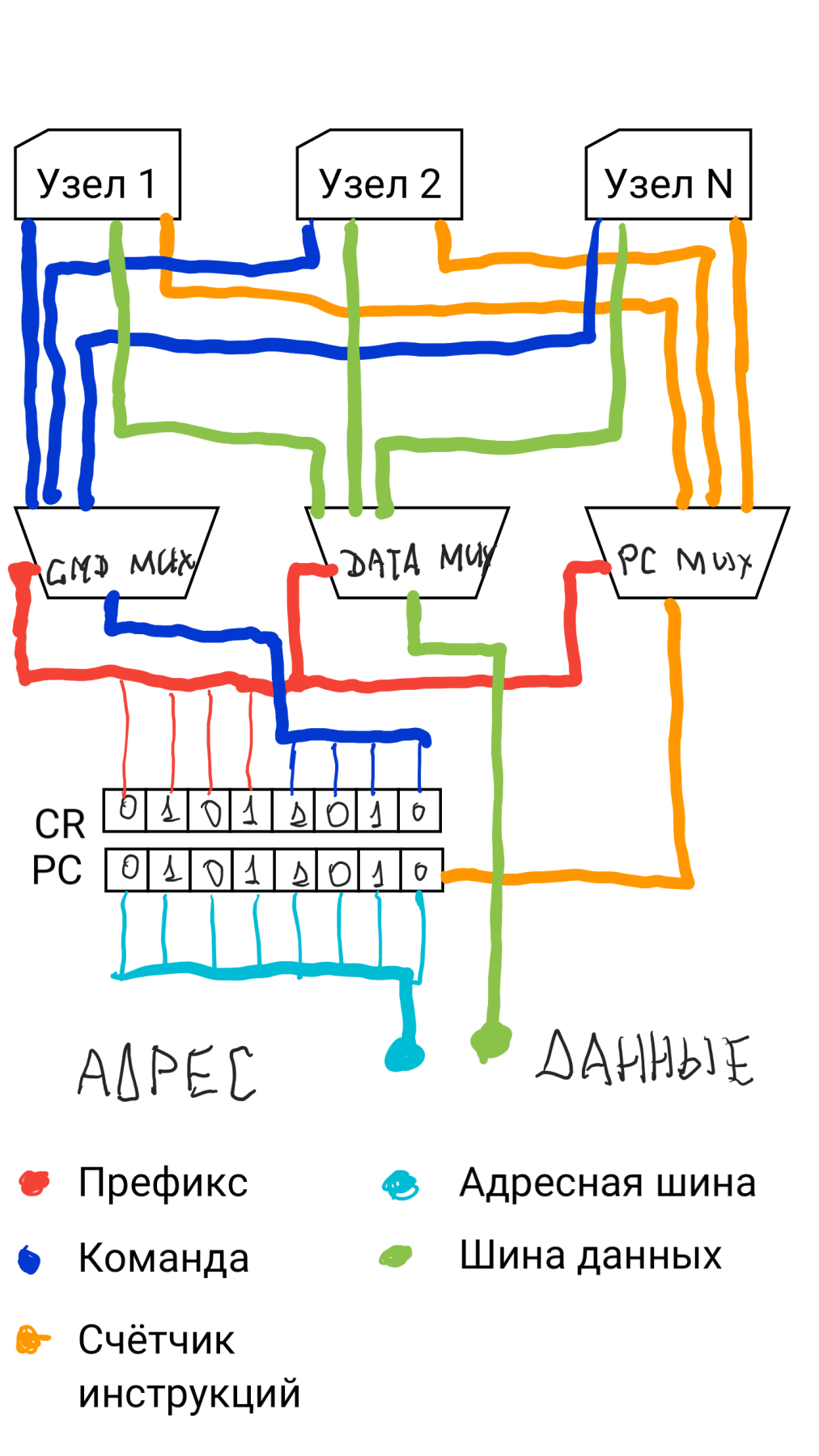
ąÆą░čĆąĖą░čåąĖčÅ ąĮą░ č鹥ą╝čā ą║ą░ą║ąĖą╝ ą▒čŗ ą╝ąŠą│ ą▒čŗčéčī ą┐čĆąŠčåąĄčüčüąŠčĆ 1975 ą│ąŠą┤ą░, ąĄčüą╗ąĖ ą▒čŗ ŌĆ”┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀEčēčæ ą▒čāą┤čāčćąĖ čłą║ąŠą╗čīąĮąĖą║ąŠą╝, ą║ąŠą│ą┤ą░ čĆą░ąĘąŠą▒čĆą░ą╗čüčÅ ą▒ąŠą╗ąĄąĄ-ą╝ąĄąĮąĄąĄ ą▓ ąŠčüąĮąŠą▓ą░čģ čĆą░ą▒ąŠčéčŗ ą╝ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĀąÉąöąśą×-86ąĀąÜ ąĖ ąŠčéą║čĆčŗą╗, čćč鹊 ą▓čüąĄ čüąĖą│ąĮą░ą╗čŗ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ą▓čŗą▓ąŠą┤ąŠą▓ čćą░čüč鹊čéą░/ąŠąČąĖą┤ą░ąĮąĖąĄ/ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ/čüą▒čĆąŠčü, ą│ąĄąĮąĄčĆąĖčĆčāąĄčé čüą░ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆ ą┐ąŠ ą╝ąĄčĆąĄ ąĮą░ą┤ąŠą▒ąĮąŠčüčéąĖ, ąĮą░čćą░ą╗ąĖčüčī ą┐čĆąĄą┤ą┐čĆąĖąĮąĖą╝ą░čéčīčüčÅ ą┐ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą│ąŠ ąĖą┤ąĄą░ą╗čīąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąÜąŠąĮąĄčćąĮąŠ, ąŠą┐ąĖčĆą░čÅčüčī ąĮą░ ąŠą┐čŗčé čĆą░ą▒ąŠčéčŗ čü ąśąÜ80, ą░ ą┐ąŠąĘą┤ąĮąĄąĄ - ąĖ Z80ŌĆ” ąÆ ą┐ąĄčĆą▓čāčÄ ąŠč湥čĆąĄą┤čī, ą▓čüąĄą│ą┤ą░ ą╝ąĮąŠčÄ ą┐čĆąĄą┤ą┐čĆąĖąĮąĖą╝ą░ą╗ą░čüčī ą┐ąŠą┐čŗčéą║ą░ čĆą░ąĘčĆą░ą▒ąŠčéą░čéčī ąĖą┤ąĄą░ą╗čīąĮčāčÄ čéą░ą▒ą╗ąĖčåčā ą║ąŠą╝ą░ąĮą┤, ąĮąĄ čéčĆąĄą▒čāčÄčēąĄą╣ čüčāčēąĄčüčéą▓ąĄąĮąĮčŗčģ čāčüąĖą╗ąĖą╣ ą┤ą╗čÅ ąĘą░ą┐ąŠą╝ąĖąĮą░ąĮąĖčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖą╣ ą╝ą░čłąĖąĮąĮąŠą│ąŠ ą║ąŠą┤ą░ ą║ ą╝ąĮąĄą╝ąŠąĮąĖą║ąĄ ąĖ čüą░ą╝ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ. ą¦č鹊 čüčéą░ą╗ąŠ ą╝ąŠąĄą╣ ąĖą┤ąĄą░ą╗ąŠą│ąĖąĄą╣. ąóą░ą║, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą╝ąĄąĮčÅ ą▓ąŠąĘą╝čāčéąĖą╗ąŠ, čćč鹊 ą▓ i8086 ą║ąŠą┤čā 00 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąŠą┐ąĄčĆą░čåąĖčÅ ADD, čćč鹊 čüą▒ąĖą▓ą░ąĄčé čü č鹊ą╗ą║čā, ąĄčüą╗ąĖ ą┐ą░ą╝čÅčéčī ąŠą▒ąĮčāą╗ąĄąĮą░. ąÆ ą┐ąŠąĖčüą║ą░čģ čüčéą░ą▒ąĖą╗čīąĮąŠčüčéąĖ ąĖ ąĘą░čēąĖčéčŗ ąŠčé čüą▒ąŠąĄą▓, ą║ąŠą┤čā 00 čÅ ąĮą░ą▓čüąĄą│ą┤ą░ ą▓ čüą▓ąŠąĖčģ ąĮą░ą▒čĆąŠčüą║ą░čģ ą┐čĆąĖčüą▓ąŠąĖą╗ ąŠą┐ąĄčĆą░čåąĖčÄ ąŠčüčéą░ąĮąŠą▓ą░ HLT. ąś čŹč鹊 ą▓ą┐ąŠą╗ąĮąĄ ąĘą┤čĆą░ą▓ąŠąĄ čĆąĄčłąĄąĮąĖąĄ. ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀąÜąŠą│ą┤ą░ ąĮą░čćą░ą╗ ą┐čĆą░ą║čéąĖč湥čüą║ąĖ čĆą░ąĘčĆą░ą▒ą░čéčŗą▓ą░čéčī 菹╝čāą╗čÅč鹊čĆ, ą┐čĆąĖčłčæą╗ ą║ ą▓čŗą▓ąŠą┤čā, čćč鹊 ą║ąŠą╝ą░ąĮą┤čŗ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ - ąĮčāąČąĮčŗąĄ, ąĮąŠ ąĖąĘą╗ąĖčłąĮąĖąĄ ą▓ čéą░ą▒ą╗ąĖčåąĄ. ąĪąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ x86 ąĖąĘąŠą▒ąĖą╗čāąĄčé čĆąĄą╗ąĖą║č鹊ą▓čŗą╝ čģą╗ą░ą╝ąŠą╝, ą║ąŠč鹊čĆčŗą╣ ąĘčĆčÅ ąĘą░čģą╗ą░ą╝ą╗čÅąĄčé ą▓čüčæ ąĖ ąŠčéąČąĖčĆą░ąĄčé ą┤čĆą░ą│ąŠčåąĄąĮąĮčŗą╣ ą▒ą░ą╣čé-ą║ąŠą┤: AAA, AAD, AAM, AAS. ąÜąŠą╝ą░ąĮą┤čŗ ENTER/LEAVE ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┐čĆąĖ ą▓čģąŠą┤ąĄ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čā ąĖ ą▓ąŠąĘą▓čĆą░č鹥 ąĖąĘ ąĮąĄčæ, čé.ąĄ. ąĮąĄ ą┤ąŠčüčéą░č鹊čćąĮąŠ čćą░čüč鹊. ą¦ąĄčüčéąĮąŠ ą│ąŠą▓ąŠčĆčÅ, ą▒čŗą╗ąŠ ą╝ąĮąŠą│ąŠ ą▓ą░čĆąĖą░ąĮč鹊ą▓ čü ą┐ąĄčĆąĄčüčéą░ąĮąŠą▓ą║ąŠą╣ ą┐ąŠąĘąĖčåąĖą╣ ą║ąŠą╝ą░ąĮą┤ i8080 (ąĮąĄ Z80) ą▓ ą┐ąŠąĖčüą║ą░čģ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠą│ąŠ. ąöčāą╝ą░ąĄč鹥, ąŠčé ą┐ąĄčĆąĄčüčéą░ąĮąŠą▓ą║ąĖ ą║ąŠą┤ąŠą▓ąŠą│ąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖčÅ ą┐čĆą░ą║čéąĖč湥čüą║ąĖ ąĮąĖč湥ą│ąŠ ąĮąĄ ą╝ąĄąĮčÅąĄčéčüčÅ? ąŁč鹊 - ąĮąĄ čéą░ą║ ąĖ ą┐ąŠčüą╗ąĄ ąĮąĄą╝ąĮąŠą│ąĖčģ čĆą░ąĘą┤čāą╝ąĖą╣ čÅ ą┐čĆąĖčüą▓ąŠąĖą╗ ąŠą┐ąĄčĆą░čåąĖąĖ RET ą║ąŠą┤ FF, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čéčĆčÄą║ąŠą▓čāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ č湥čĆąĄąĘ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ą║ąŠą╝ą░ąĮą┤čŗ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠą│ąŠ ą┐ąĄčĆąĄčģąŠą┤ą░ ąĮą░ čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčé. ąóąĄą╝ čüą░ą╝čŗą╝, ą┐ąŠčÅą▓ąĖą╗čüčÅ ąĮą░ą▒ąŠčĆ ą║ąŠą╝ą░ąĮą┤ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąŠąĘą▓čĆą░čéą░ č湥čĆąĄąĘ čéčĆčÄą║ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ, ąĮąĄ ąĘą░čéčĆą░čćąĖą▓ą░čÅ čÅč湥ą╣ą║ąĖ čéą░ą▒ą╗ąĖčåčŗ ą║ąŠą╝ą░ąĮą┤ŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āąóą░ą║ ą║ą░ą║ ą╝ąŠą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī ą┤čĆčāąČąĄčüčéą▓ąĄąĮąĮčāčÄ čüąĖčüč鹥ą╝čā ą║ąŠą╝ą░ąĮą┤, ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ą╗čæą│ą║čāčÄ ą║ ąĘą░ą┐ąŠą╝ąĖąĮą░ąĮąĖčÄ ą┤ą╗čÅ čĆčāčćąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāčĆąŠą▓ą░ąĮąĖčÅ ą╝ą░čłąĖąĮąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▓ čüą┐ą░čĆčéą░ąĮčüą║ąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ (ą░čüčüąĄą╝ą▒ą╗ąĄčĆ ąĄčēčæ ąĮąĄ ą▒čŗą╗ ą│ąŠč鹊ą▓), ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ ąŠą┐ąĄčĆą░čåąĖą╣ ąĘą░ąĮąĖą╝ą░čÄčé ą▓ čéą░ą▒ą╗ąĖčåąĄ ą┐ąŠąĘąĖčåąĖąĖ čü ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ą┐čĆąŠąĘčĆą░čćąĮčŗą╝ąĖ ą┐ąŠąĘąĖčåąĖčÅą╝ąĖ: A0-AF - ALU, B0-BF - Branch, C0-CF - inCrement, D0-DF - Decrement, E0-EF - Exchange, F0-FF - FunctionsŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀąĪą┐čāčüčéčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝ąĄčüčÅčåąĄą▓ čāą┐ąŠčĆąĮąŠą╣ čĆą░ą▒ąŠčéčŗ ą▒čŗą╗ čģčāą┤ąŠ-ą▒ąĄą┤ąĮąŠ ąĮą░ą┐ąĖčüą░ąĮ ą░čüčüąĄą╝ą▒ą╗ąĄčĆ ąĖ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆ. ąóčĆčāą┤ąĮąŠčüčéčī ą▒čŗą╗ą░ ą▓ č鹊ą╝, čćč鹊 ą║ąŠą│ą┤ą░ čÅ ą▓ąĮąŠčüąĖą╗ ą┐ąŠą┐čĆą░ą▓ą║čā ą▓ čüąĖčüč鹥ą╝čā ą║ąŠą╝ą░ąĮą┤, čéčĆąĄą▒ąŠą▓ą░ą╗ąŠčüčī ą▓ąĮąŠčüąĖčéčī ąĖ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ą▓ ą░čüčüąĄą╝ą▒ą╗ąĄčĆ. ąØąŠ, ą┐ąŠč鹊ą╝ čÅ čĆąĄčłąĄąĮąĖąĄ ąĮą░čłčæą╗ ą┐ąŠčüčĆąĄą┤čüčéą▓ąŠą╝ čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čüčéčĆčāą║čéčāčĆąĮčŗčģ ą╝ą░čüčüąĖą▓ąŠą▓. ąÆčüčÅ čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ čüąŠčéąĮčÄčÄ čüčéčĆąŠą║ ą┤ąĄčłąĖčäčĆą░č鹊čĆą░ ą▓ čüčéąĖą╗ąĄ ą┐ąŠčüčéčāą╗ą░č鹊ą▓ Verilog: 0-1-X. ą¦č鹊 čüčāčēąĄčüčéą▓ąĄąĮąĮąŠ čāą┐čĆąŠčüčéąĖą╗ąŠ ą┤ą░ą╗čīąĮąĄą╣čēčāčÄ čĆą░ąĘčĆą░ą▒ąŠčéą║čā. ąØą░ ą┤ą░ąĮąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé ą┤ąĄčłąĖčäčĆą░č鹊čĆ ąĖą╝ąĄąĄčé čłąĖąĮčā ąĖąĘ 18 čĆą░ąĘčĆčÅą┤ąŠą▓. ą¦č鹊 ą┐čĆąĖą╝ąĄčĆąĮąŠ ąŠą║ąŠą╗ąŠ 4 ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ ą║ąŠą╝ą░ąĮą┤. ąÜąŠąĮąĄčćąĮąŠ, ą║ąŠą╝ą░ąĮą┤ čā ą╝ąĄąĮčÅ ą│ąŠčĆą░ąĘą┤ąŠ ą╝ąĄąĮčīčłąĄ. ąóą░ą║ ą║ą░ą║ ą│čĆčāą┐ą┐ą░ą╝ąĖ ą▒ąĖč鹊ą▓ ą┐čĆąŠčüč鹊 čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐čĆąĖ ą║ą░ą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ čüąŠčüč鹊čÅąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ą┤ą░ąČąĄ ąÉąøąŻ ą║ąŠą╝ą░ąĮą┤ą░ čĆą░čüą┐ąŠąĘąĮą░čæčéčüčÅ ą┤ąĄčłąĖčäčĆą░č鹊čĆąŠą╝ŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀąĪą╗ąĄą┤čāąĄčé čāą║ą░ąĘą░čéčī ąĄčēčæ ąŠą┤ąĖąĮ ą╗čÄą▒ąŠą┐čŗčéąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé. ąæčŗą╗ąŠ ą┤ą░ą▓ąĮąŠ ąĘą░ą╝ąĄč湥ąĮąŠ, čćč鹊 ąÉąøąŻ ąĮąĄčüą┐ąŠčüąŠą▒ąĮąŠ ą▓čŗčüčéą░ą▓ą╗čÅčéčī čäą╗ą░ąČą║ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮąĖ ą┐čĆąĖ ą║ą░ą║ąĖčģ ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓ą░čģ ą▓ čéčĆąĖ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ: ąØąŠą╗čī čüąŠ ąĘąĮą░ą║ąŠą╝ (SF+ZF), ąĮąŠą╗čī čü ąĮąĄčćčæčéąĮčŗą╝ ą┐ą░čĆąĖč鹥č鹊ą╝ (PF+ZF) ąĖ ąĮąŠą╗čī čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮąĄčćčæčéąĮąŠą│ąŠ ą┐ą░čĆąĖč鹥čéą░ (SF+PF+ZF). ąóą░ą║ ą║ą░ą║ čŹč鹊 ą┐ąŠą┐čĆąŠčüčéčā ąĮąĄ ą▓ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ čéą░ą▒ą╗ąĖčåčā ą┐ąŠčüčéčāą╗ą░č鹊ą▓ čĆą░ą▒ąŠčéčŗ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮčŗčģ čāąĘą╗ąŠą▓. ąóąĄą╝ čüą░ą╝čŗą╝, ą▓ čüą▓ąŠąĄą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ čÅ čŹč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ ąĮą░ čāčĆąŠą▓ąĮąĄ čüą░ą╝ąŠą│ąŠ ą┤ąĄčłąĖčäčĆą░č鹊čĆą░ ą║ąŠą╝ą░ąĮą┤. ąś čŹčéąĖ čéčĆąĖ ąĮąĄąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ čäą╗ą░ąČą║ąŠą▓ čüčéą░čéčāčüą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░čüčłąĖčĆąĖą╗ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čüąĖčüč鹥ą╝čŗ ą║ąŠą╝ą░ąĮą┤. ą¤ąŠčÅą▓ąĖą╗ą░čüčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąŠą▓č鹊čĆą░ ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ (ą░ąĮą░ą╗ąŠą│ x86-REP) ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą╗ąĖąĮąĄą╣ąĮąŠą│ąŠ ą┐čĆąŠą┐čāčüą║ą░ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą▒ąĄąĘ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ (ą░ąĮą░ą╗ąŠą│ x86-CMOVcc). ąśąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą╗čāčćąĖą╗ąĖ ą╝ąĮąĄą╝ąŠąĮąĖą║čā LOOP ąĖ SKIP čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠŌĆ” ąóčĆąĄčéčīčÅ ąČąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ čäą╗ą░ąČą║ąŠą▓ (SF+PF+ZF) ąĮąĄ ąĖą╝ąĄąĄčé ą┐čĆčÅą╝ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ą┤ąŠčüčéąĖą│ą░ąĄčéčüčÅ čéčĆčÄą║ąŠą▓čŗą╝ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄą╝ čü ąĘą░ą╝čŗą║ą░ąĮąĖąĄą╝ ąĮą░ čüąĄą▒čÅ (ąĮąĄ ą░čĆą│čāą╝ąĄąĮčé FF, ą░ ąĮą░ ą║ąŠą┤ ąŠą┐ąĄčĆą░čåąĖąĖ JMP). ąóą░ą║ ą║ą░ą║ čÅ čüą▓ąŠą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ą┐čŗčéą░čÄčüčī čüą┤ąĄą╗ą░čéčī čģąŠčéčī ąĮąĄ čāą╝ąĮčŗą╝, ąĮąŠ ą░ą┤ąĄą║ą▓ą░čéąĮčŗą╝, č鹊 ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ąĮą░ ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗą╣ čåąĖą║ą╗ čÅą▓ą╗čÅąĄčéčüčÅ čéčĆčÄą║ąŠą▓ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĄą╣ WAIT - ą░ąĮą░ą╗ąŠą│ LOOP, ąĮąŠ čü čāčüą╗ąŠą▓ąĮčŗą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝: ąæąĄąĘ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą│ąŠ čäą╗ą░ą│ą░ CF čåąĖą║ą╗ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé (ąĮąĄčćč鹊 čüčģąŠą┤ąĮąŠąĄ čü x86-REPNZ)ŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀąÜąŠą╝ą░ąĮą┤čŗ čĆą░ą▒ąŠčéčŗ čü ą┐ąŠčĆčéą░ą╝ąĖ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ IN/OUT ą┤ą░ą▓ąĮąŠ ąĮą░ąĘčŗą▓ą░čÄčé ą║ąŠčüčéčŗą╗čÅą╝ąĖ ą┐ąĄčĆąĄąČąĖčéą║ąŠą▓ čüčéą░čĆąŠą┤ą░ą▓ąĮąĖčģ ą░čĆčģąĖč鹥ą║čéčāčĆ. ąś ą▓ čüąĖčüč鹥ą╝ąĄ ą║ąŠą╝ą░ąĮą┤ ą╝ąŠąĄą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąŠąĮąĖ čÅą▓ąĮąŠ ąŠčéčüčāčéčüčéą▓čāčÄčé. ąźąŠčéčÅ ąĖ ąĖą╝ąĄčÄčéčüčÅ č湥čĆąĄąĘ čéčĆčÄą║ąŠą▓ąŠą╣ WAIT-čåąĖą║ą╗. ąś čŹč鹊 ąĮąĄ ą┐čĆąŠčüč鹊 čéą░ą║. ąÜąŠą│ą┤ą░ ą▓ąĮąĄčłąĮąĄąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą│ąŠč鹊ą▓ąŠ, WAIT-čåąĖą║ą╗ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčéčüčÅ ą▓čüąĄą│ąŠ ąŠą┤ąĮčā ąĖč鹥čĆą░čåąĖčÄ. ąÉ ąĄčüą╗ąĖ čāčüčéčĆąŠą╣čüčéą▓ąŠ ąĘą░ąĮčÅč鹊, WAIT-čåąĖą║ą╗ ąĘą░ą╣ą╝čæčé ąŠčé 7 ą┤ąŠ 255 ąĖč鹥čĆą░čåąĖą╣. ąś ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čüčĆą░ąĘčā ą▒čāą┤ąĄčé ąĘąĮą░čéčī, čāčüčéčĆąŠą╣čüčéą▓ąŠ ą│ąŠč鹊ą▓ąŠ ąĖą╗ąĖ ąĘą░ąĮčÅč鹊, čéą░ą║ ą║ą░ą║ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ IN/OUT ąĖąĘą╝ąĄąĮčÅčÄčé čäą╗ą░ą│ CFŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āą¤čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖą╝ąĄąĄčéčüčÅ ą▓čüąĄą│ąŠ 10 ą║ąŠą╝ą░ąĮą┤ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ INT 0-9 čü ą╝ą░čłąĖąĮąĮčŗą╝ ą║ąŠą┤ąŠą╝ F0-F9 čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ (Fn0-Fn9). ąÆ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą▓ WAIT-čåąĖą║ą╗ąĄ čŹčéąĖ INT-ąĖąĮčüčéčĆčāą║čåąĖąĖ čéą▓ąŠčĆčÅčé čćčāą┤ąĄčüą░: ąöąĄčłąĖčäčĆą░č鹊čĆ ą║ąŠą╝ą░ąĮą┤ ąŠčéą║ą╗čÄčćą░ąĄčéčüčÅ ąŠčé ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ ą░ą┤čĆąĄčüą░/ą┤ą░ąĮąĮčŗčģ ąĖ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčéčüčÅ ą║ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╝čā ą▒čāč乥čĆčā ą║ąŠą╝ą░ąĮą┤, ą▓ ą║ąŠč鹊čĆąŠą╝ ą╝ąŠąČąĮąŠ ąĘą░ą┐ąŠą╝ąĮąĖčéčī ą┤ąŠ 7 ąĖąĮčüčéčĆčāą║čåąĖą╣. ąÆąĮčāčéčĆąĖ WAIT-čåąĖą║ą╗ą░ INT-ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░čüčéą░ą▓ą╗čÅąĄčé ą┤ąĄčłąĖčäčĆą░č鹊čĆ ą║ąŠą╝ą░ąĮą┤ čćąĖčéą░čéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ č鹊ą╗čīą║ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒čāč乥čĆą░, ą║ąŠč鹊čĆčŗąĄ, ąĄčüč鹥čüčéą▓ąĄąĮąĮąŠ, čüą┐ąŠčüąŠą▒ąĮčŗ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ąĘą░ 1 čéą░ą║čé. ąóąĄą╝ čüą░ą╝čŗą╝, ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ą┐ąŠą┤ąŠą▒ąĖąĄ ą╝ą░ą║čĆąŠčüą░ ąĖą╗ąĖ ą│ąĖą▒ą║ąŠą╣ ą╝ąĖą║čĆąŠą║ąŠą╝ą░ąĮą┤čŗ, ą║ąŠč鹊čĆą░čÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ čāčüą╗ąŠą▓ąĮčŗą╝ čåąĖą║ą╗ąŠą╝ ą┤ąŠ 255 čĆą░ąĘ. ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄčéčüčÅ INT- ą┐čĆąŠčłąĖą▓ą║ą░ čéą░ą║ ąČąĄ ą╗ąĄą│ą║ąŠ - ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ SKIP: ąÆčüąĄ ą┐čĆąŠą┐čāčüą║ą░ąĄą╝čŗąĄ ą┤ąĄčłąĖčäčĆą░č鹊čĆąŠą╝ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠą┐ą░ą┤ą░čÄčé ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ ą▒čāč乥čĆŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆ čÅą▓ąĮąŠ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ąĮąĄ čāą╝ąĄąĄčé. ąÉčĆčģąĖč鹥ą║čéčāčĆąĮąŠ ą▓čüčæ ąĘą░ą┤čāą╝ą░ąĮąŠ čéą░ą║, čćč鹊ą▒čŗ čüąĖčüč鹥ą╝ą░ ąĮą░ ą▒ą░ąĘąĄ ą┤ą░ąĮąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą▒čŗą╗ą░ ą╝čāą╗čīčéąĖąĘą░ą┤ą░čćąĮąŠą╣. ąÉą┐ą┐ą░čĆą░čéąĮąŠ ą┐čĆąŠčåąĄčüčüąŠčĆ ąĖą╝ąĄąĄčé 128 čĆąĄą│ąĖčüčéčĆąŠą▓čŗčģ čäą░ą╣ą╗ą░, ą║ą░ąČą┤čŗą╣ ąĖąĘ ą║ąŠč鹊čĆčŗčģ ąĖą╝ąĄąĄčé ąŠą▒čŖčæą╝ ą┤ąŠ 256 čüą╗ąŠą▓, ąĮąĄčüčāčēąĖą╣ ą▓ čüąĄą▒ąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓čüąĄčģ ąĀą×ąØ, čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĖ čüčćčæčéčćąĖą║ąŠą▓. ąóąĄą╝ čüą░ą╝čŗą╝, ą┐čĆąŠčåąĄčüčüąŠčĆ čüą┐ąŠčüąŠą▒ąĄąĮ ą╝ą│ąĮąŠą▓ąĄąĮąĮąŠ ą┐ąĄčĆąĄą║ą╗čÄčćą░čéčī ą║ąŠąĮč鹥ą║čüčéčŗ ąĘą░ą┤ą░čć. ą¤čĆąĖ čŹč鹊ą╝, ą┐ąŠčüą╗ąĄ ąĘą░ą┐čāčüą║ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ ąĮą░čćąĖąĮą░ąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąĘą░ą┤ą░čćčā čü ąĮčāą╗ąĄą▓čŗą╝ ą║ąŠąĮč鹥ą║čüč鹊ą╝, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÅ ąĄą╣ ą┐čĆąĖą▓ąĄą╗ąĄą│ąĖąĖ čÅą┤čĆą░ čüąĖčüč鹥ą╝čŗ. ąÆąĮčāčéčĆąĖ ą║ąŠą┤ą░ čŹč鹊ą│ąŠ čÅą┤čĆą░ ąŠą┐ąĄčĆą░čåąĖąĖ WAIT+IN/OUT, ąĮą░ą┐čĆąĖą╝ąĄčĆ, čĆą░ą▒ąŠčéą░čÄčé čü ą┐ąŠčĆčéą░ą╝ąĖ ąĮą░ą┐čĆčÅą╝čāčÄ, ą║ą░ą║ ąĖ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī. ąØąŠ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐čĆąĖą║ą╗ą░ą┤ąĮčŗčģ ąĘą░ą┤ą░čć ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą┐čĆąŠčüč鹊 čÅą▓ą╗čÅčÄčéčüčÅ ą┐ąĄčĆąĄą║ą╗čÄčćą░č鹥ą╗čÅą╝ąĖ ąĮą░ ą║ąŠąĮč鹥ą║čüčé čÅą┤čĆą░ ąĖ ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓č鹊čĆąĖčćąĮąŠą╝čā ą║ąŠą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░čéčī ą┐ąĄčĆąĖč乥čĆąĖčÄ ąĮą░ą┐čĆčÅą╝čāčÄ. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĖ čü ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠčüč鹊 ąŠčéą║ąĖą┤čŗą▓ą░čÄčé ą║ąŠąĮč鹥ą║čüčé ąĘą░ą┤ą░čćąĖ ą┤ąŠ čÅą┤čĆą░, ą│ą┤ąĄ čāąČąĄ ąĖ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░. ąĪą╗ąĄą┤čāąĄčé ąŠčéą╝ąĄčéąĖčéčī č鹊, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ HLT ą▓ąĮčāčéčĆąĖ ą║ąŠą┤ą░ čÅą┤čĆą░ čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ ąŠčüąŠą▒čŗą╣ ą┐čĆąĄčäąĖą║čü, čāą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ ą┐ąĄčĆąĄą║ą╗čÄčćą░č鹥ą╗ąĄą╝ ą║ąŠąĮč鹥ą║čüč鹊ą▓ ąĘą░ą┤ą░čć. ąōąŠą▓ąŠčĆčÅ ą┐čĆąŠčēąĄ, čÅą┤čĆąŠ ą┐ąĄčĆąĄą┤ą░čæčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐čĆąĖą║ą╗ą░ą┤ąĮąŠą╝čā ą║ąŠą┤čā ą┐ąŠčüčĆąĄą┤čüčéą▓ąŠą╝ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ WAIT+HLT ąĮą░ ą▓čĆąĄą╝čÅ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą▓ ą░ą▓č鹊-čĆąĄąČąĖą╝ąĄ SKIP ą┐čĆąŠą┐čāčüą║ą░ąĄčé ą┤ąŠ 7 čüą╗ąĄą┤čāčÄčēąĖčģ ą║ąŠą╝ą░ąĮą┤ JMP (ąĮą░ą┐ąŠą╝ąĖąĮą░ąĄčé ON n GOTO ąæąĄą╣čüąĖą║ą░) ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čüąĖčéčāą░čåąĖąĄą╣. ąĪąĖčéčāą░čåąĖą╣ ą▓čüąĄą│ąŠ ą▒čŗą▓ą░ąĄčé 8: ąĘą░ą┐čĆąŠčü ą║ API, ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, čüą▒ąŠą╣ čüčéčĆą░ąĮąĖčå ą┐ą░ą╝čÅčéąĖ, ąĖčüč鹥č湥ąĮąĖąĄ ą║ą▓ą░ąĮčéą░ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠąĮą║čĆąĄčéąĮąŠą╣ ąĘą░ą┤ą░čćąĖ, ą┐ąŠą┐čŗčéą║ą░ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ąŠčĆčéčā ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░, ą┐čĆąŠą│čĆą░ą╝ą╝ąĮą░čÅ ąŠčłąĖą▒ą║ą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣, ą▓ąĮąĄčłąĮąĄąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, ą┐čĆąĖčģąŠą┤ čüąĖą│ąĮą░ą╗ą░ Reset. ą¤ąŠčüą╗ąĄ ąĘą░ą┐čāčüą║ą░ čüąĖčüč鹥ą╝čŗ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ, ąĄčüč鹥čüčéą▓ąĄąĮąĮąŠ, čüąĖčéčāą░čåąĖčÅ čü Reset. ą¤čĆąĖčćčæą╝, ąĄčüą╗ąĖ čüąĖą│ąĮą░ą╗ Reset ą┐čĆąĖčģąŠą┤ąĖčé ą┐ąŠąĘą┤ąĮąĄąĄ, ą┐čĆąŠčåąĄčüčüąŠčĆ ąĮąĄ čüą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ, ą░ ą┐ąĄčĆąĄą┤ą░čæčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéčā čÅą┤čĆą░, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą░ą┤ąĄą║ą▓ą░čéąĮąŠ čāčüą┐ąĄčéčī čüąŠą▓ąĄčĆčłąĖčéčī čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ. ąĢčüą╗ąĖ čÅą┤čĆąŠ ąĮąĄ čüą╝ąŠą│ą╗ąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī čŹč鹊 čüąŠą▒čŗčéąĖąĄ ąĖą╗ąĖ ą┐ąŠą▓ąĖčüą╗ąŠ, čü ąŠą▒ąĮčāą╗ąĄąĮąĖąĄą╝ čüčćčæčéčćąĖą║ą░ čéą░ą║č鹊ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆ čüą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ 18-čĆą░ąĘčĆčÅą┤ąĮąŠą╣ čłąĖąĮąŠą╣ ą┤ąĄčłąĖčäčĆą░č鹊čĆą░ ą║ąŠą╝ą░ąĮą┤ 8 čĆą░ąĘčĆčÅą┤ąŠą▓ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ čüąŠą▒čüčéą▓ąĄąĮąĮąŠ ą┐ąŠą┤ ą║ąŠą┤ čüą░ą╝ąŠą╣ ą║ąŠą╝ą░ąĮą┤čŗ. ąóčĆąĖ ą▒ąĖčéą░ - ą║ąŠą┤ ą┐čĆąĄčäąĖą║čüą░ ą║ąŠą╝ą░ąĮą┤čŗ. ą×ą┤ąĖąĮ ą▒ąĖčé - ą┐čĆąĖąĘąĮą░ą║ čéčĆčÄą║ąŠą▓ąŠą│ąŠ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ, ą║ąŠą│ą┤ą░ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗą╣ ą▒ą░ą╣čé ą░čĆą│čāą╝ąĄąĮčéą░ ą║ąŠą╝ą░ąĮą┤čŗ čĆą░ą▓ąĄąĮ -1 (FF). ąĢčēčæ čéčĆąĖ ą▒ąĖčéą░ - čĆą░čüčłąĖčĆąĄąĮąĮąĖąĄ ą┤ąĄčłąĖčäčĆą░čåąĖąĖ ą║ąŠą╝ą░ąĮą┤ čäą╗ą░ą│ą░ą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (LOOP/WAIT/EVAL + ą▒ąĖčé Boot-mode). ą×čüčéą░ą▓čłąĖąĄčüčÅ čéčĆąĖ ą▒ąĖčéą░ ąĮąĄ ąĖą│čĆą░čÄčé ąŠčüąŠą▒ąŠą╣ čĆąŠą╗ąĖ ąĖ ąĮąĄąČąĮčŗ ą╗ąĖčłčī ą┤ą╗čÅ čüčåąĄą┐ą╗ąĄąĮąĖčÅ čüą╝ąĄąČąĮčŗčģ ą▒ą░ą╣čé-ą║ąŠą┤ąŠą▓ (F0-F7 + F8-F9; FA-FD / EA-ED; ą┐čĆąĄčäąĖą║čüąŠą▓ čü ą▓ąŠčüčģąŠą┤čÅčēąĖą╝/ąĮąĖčüčģąŠą┤čÅčēąĖą╝/ą┐čĆčÅą╝čŗą╝ ąĘą░ą╝čŗą║ą░ąĮąĖąĄą╝ ąĖ čé.ą┤.). ┬Ā┬Ā┬Ā┬Ā┬Āą¤ąŠčüą╗ąĄ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ ąĮą░ą┐čĆčÅąČąĄąĮąĖčÅ ą┐ąĖčéą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ "čģąŠą╗ąŠą┤ąĮąŠą│ąŠ čüčéą░čĆčéą░". ąÆ čŹč鹊ą╝ čüąŠčüč鹊čÅąĮąĖąĖ ąŠąĮ ąĮąĄ čĆąĄą░ą│ąĖčĆčāąĄčé ąĮą░ čüąĖą│ąĮą░ą╗čŗ ą│ąĄąĮąĄčĆą░č鹊čĆą░ čéą░ą║č鹊ą▓ąŠą╣ čćą░čüč鹊čéčŗ ąĖ ą▓čüąĄ ąĄą│ąŠ čłąĖąĮčŗ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą▓čŗčüąŠą║ąŠąĖą╝ą┐ąĄąĮą┤ą░ąĮčüąĮąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ. ąĪ ą┐čĆąĖčģąŠą┤ąŠą╝ čüąĖą│ąĮą░ą╗ą░ "čüą▒čĆąŠčüą░" čüčćčæčéčćąĖą║ čéą░ą║č鹊ą▓ ą┤ąŠą╗ąČąĄąĮ ąŠčéčüčćąĖčéą░čéčī 65536 ąĘą░ą┐čāčüą║ą░čÄčēąĖčģ čéą░ą║č鹊ą▓čŗčģ ąĖą╝ą┐čāą╗čīčüąŠą▓, ą┐čĆąĄąČą┤ąĄ č湥ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆ ąĘą░ą┐čāčüčéąĖčéčüčÅ. ąĢčüą╗ąĖ ąĮą░ ą┐čĆąŠčéčÅąČąĄąĮąĖąĖ ą▓čüąĄą│ąŠ ąĘą░ą┐čāčüą║ą░čÄčēąĄą│ąŠ ą┐ąĄčĆąĖąŠą┤ą░ čāčĆąŠą▓ąĄąĮčī čüąĖą│ąĮą░ą╗ą░ "čüą▒čĆąŠčüą░" ąĮąĄ ąĖąĘą╝ąĄąĮčÅą╗čüčÅ, ą▓čüčæ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą▓ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ čĆą░ą▒ąŠčćąĖą╣ čĆąĄąČąĖą╝. ąśąĮą░č湥 čüčćčæčéčćąĖą║ ąĘą░ą┐čāčüą║ą░čÄčēąĖčģ čéą░ą║č鹊ą▓ ąŠą▒ąĮčāą╗čÅąĄčéčüčÅ ą▓ąĮąŠą▓čī. ąóą░ą║ąŠą╣ čāčüą╗ąŠąČąĮčæąĮąĮčŗą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ čüčéą░čĆčéą░ ą▒čŗą╗ ą▓ą▓ąĄą┤čæąĮ čü čåąĄą╗čīčÄ ąŠą▒ąĄąĘąŠą┐ą░čüąĖčéčī ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčāčÄ čüčĆąĄą┤čā ąŠčé čĆą░ąĘąĮčŗčģ ąĮąĄą╗ąĖąĮąĄą╣ąĮčŗčģ čüąĖčéčāą░čåąĖą╣. ┬Ā┬Ā┬Ā┬Ā┬ĀąÆąŠ ą▓čĆąĄą╝čÅ ą┤ąĄą╣čüčéą▓ąĖčÅ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüčĆąĄą┤čŗ ąĖčüą║ą╗čÄčćą░čÄčéčüčÅ čüą╗čāčćą░ą╣ąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čüąŠ čüą▒čĆąŠčüąŠą╝ čüąĖčüč鹥ą╝čŗ ą▓ ąĖčüčģąŠą┤ąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą┐čĆąĖčģąŠą┤ąŠą╝ ą║čĆą░čéą║ąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ "čüą▒čĆąŠčüą░". ąÜą░ą║ ąĖ ą┐čĆąĖ "čģąŠą╗ąŠą┤ąĮąŠą╝ čüčéą░čĆč鹥", ą┐ąĄčĆąĄąĘą░ą┐čāčüą║ čüąŠčüč鹊ąĖčéčüčÅ ąĮąĄ čĆą░ąĮąĄąĄ ąŠčéčüčćčæčéą░ 65536 čéą░ą║č鹊ą▓čŗčģ ąĖą╝ą┐čāą╗čīčüąŠą▓. ąŚą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ č鹊ą│ąŠ, čćč鹊 čüą░ą╝ ą║ąŠą┤ čÅą┤čĆą░ ą╝ąŠąČąĄčé ą▓ą╗ąĖčÅčéčī ąĮą░ ąŠčéčüčćčæčé ąĘą░ą┐čāčüą║ą░čÄčēąĄą│ąŠ ą┐ąĄčĆąĖąŠą┤ą░ ąĖ ąŠčéą║ą╗ą░ą┤čŗą▓ą░čéčī ąĄą│ąŠ ąĮą░ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗čæąĮąĮčŗą╣ čüčĆąŠą║. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, ąĄčüą╗ąĖ ą▓čüčÅ čüąĖčüč鹥ą╝ą░ ąĘą░ą▓ąĖčüą╗ą░ ąĖ ąĮąĄ ąŠčéą║ą╗ąĖą║ą░ąĄčéčüčÅ ąĮą░ ą▓ąĮąĄčłąĮąĖąĄ čüąĖą│ąĮą░ą╗čŗ, čüąĖą│ąĮą░ą╗ "čüą▒čĆąŠčüą░" ą┤ąŠčüčéą░č鹊čćąĮąŠą╣ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥ą╗čīąĮąŠčüčéąĖ ą┐čĆąŠąĖąĘą▓ąĄą┤čæčé ą┐ąĄčĆąĄąĘą░ą┐čāčüą║ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓ ąĖčüčģąŠą┤ąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄŌĆ” ┬Ā┬Ā┬Ā┬Ā┬Āąóą░ą║ ą║ą░ą║ čäą╗ą░ąČą║ąĖ čüąŠčüč鹊čÅąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖąĘą╝ąĄąĮčÅčÄčéčüčÅ ąĮąĄ č鹊ą╗čīą║ąŠ ąÉąøąŻ, ąĮąŠ ąĖ č鹥čüąĮąŠ čüą▓čÅąĘą░ąĮčŗ čü ą┤ąĄčłąĖčäčĆą░č鹊čĆąŠą╝ ą║ąŠą╝ą░ąĮą┤, čäą╗ą░ą│ CF ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ą░ą║ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ ąĮąĄ č鹊ą╗čīą║ąŠ ą▓ WAIT-čåąĖą║ą╗ą░čģ, ąĮąŠ ąĖ ą┐čĆąĖ ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖąĖ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ čüąŠą▒čŗčéąĖčÅ ą▓ čüąĖčüč鹥ą╝ąĄ. ąóą░ą║, ąĮą░ čäą╗ą░ą│ CF ą▓ą╗ąĖčÅąĄčé ą║ą░ą║ čäčĆąŠąĮčé, čéą░ą║ ąĖ čüčĆąĄąĘ čüąĖą│ąĮą░ą╗ą░ "čüą▒čĆąŠčüą░", ą┤ąŠčüčéą░č鹊čćąĮąŠ ąĖąĮč乊čĆą╝ąĖčĆčāčÅ ąŠ ą▓čüąĄčģ čäą░ą║č鹊čĆą░čģ. ┬Ā┬Ā┬Ā┬Ā┬Āą¤ąŠą╝ąĖą╝ąŠ ą║ąŠąĮč鹥ą║čüčéąĮčŗčģ čäą░ą╣ą╗ąŠą▓ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ąĖą╝ąĄąĄčé 8 čāą┐čĆą░ą▓ą╗čÅčÄčēąĖčģ čĆąĄą│ąĖčüčéčĆąŠą╝, ą┤ąŠčüčéčāą┐ąĮčŗąĄ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ą▓ąŠ ą▓čüąĄčģ ą┐čĆąĖą║ą╗ą░ą┤ąĮčŗčģ ąĘą░ą┤ą░čćą░čģ. ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą╝ąŠąČąĄčé čüą▓ąŠą▒ąŠą┤ąĮąŠ ą┐čĆąŠčćąĖčéą░čéčī ąĖ ąŠčüąĮąŠą▓ąĮąŠą╣ ąĮčāą╗ąĄą▓ąŠą╣ čĆąĄą│ąĖčüčéčĆ čü ąĖąĮą┤ąĄą║čüąŠą╝ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą│ąŠ ą║ąŠąĮč鹥ą║čüčéą░ ą▓ čüčĆąĄą┤ąĄ, ą░ čéą░ą║ąČąĄ čüčćčæčéčćąĖą║ ąŠčüčéą░ą▓čłąĖčģčüčÅ čéą░ą║č鹊ą▓ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą┐ąĄčĆąĄą┤ą░čćąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┤čĆčāą│ąŠą╣ ąĘą░ą┤ą░č湥 ą▓ ąŠč湥čĆąĄą┤ąĖ. ą×ą┤ąĮą░ą║ąŠ, ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ą▓ čŹčéąĖ 7 čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąĮąĄčÅą▓ąĮąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ąŠą▒čĆą░čēąĄąĮąĖąĄ ą║ čÅą┤čĆčā čü ąŠąČąĖą┤ą░ąĮąĖąĄą╝. ąØčāą╗ąĄą▓ąŠą╣ čāą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ čĆąĄą│ąĖčüčéčĆ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ čÅą▓ąĮąŠ ąĮąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ ąĮąĖą║ą░ą║, čéą░ą║ ą║ą░ą║ ą┤ąŠčüčéčāą┐ ą║ ąĮąĄą╝čā čÅą▓ą╗čÅąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ ąŠčüčéą░ąĮąŠą▓ą░ HLTŌĆ” ┬Ā┬Ā┬Ā┬Ā┬ĀąĪą╗ąĄą┤čāąĄčé ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 čģąŠą╗ąŠčüčéčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ ą▓čüąĄą│ąŠ 8. ą×ą┤ąĮą░ ąĖąĘ ą║ąŠč鹊čĆčŗčģ ąĖą╝ąĄąĄčé ą║ąŠą┤ FE, ą░ ąŠčüčéą░ą╗čīąĮčŗąĄ 7 - ąĄčæ ą┐čĆąĄčäąĖą║čü-čĆą░čüčłąĖčĆąĄąĮąĮčŗąĄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ. ąÆčüąĄ ąŠąĮąĖ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą│ą░čĆą░ąĮčéąĖčĆčāčÄčé ąĘą░ą┤ąĄčƹȹ║čā ąĮą░ čāą║ą░ąĘą░ąĮąŠąĄ čćąĖčüą╗ąŠ čéą░ą║č鹊ą▓. ąÆ čüąŠčüčéą░ą▓ąĄ čü LOOP ą╝ąŠąČąĮąŠ čüčéą░ą▓ąĖčéčī ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ č鹊čćą║ąĖ čü čāą┐čĆą░ą▓ą╗čÅąĄą╝ąŠą╣ ąĘą░ą┤ąĄčƹȹ║ąŠą╣. ąóąŠą│ą┤ą░ ą║ą░ą║ ą▓ čüąŠčüčéą░ą▓ąĄ čü WAIT čŹčéąĖ NOP/1-7 ąĮąĄčüčāčé čüą▓ąŠą▒ąŠą┤ąĮčŗą╣ čüą╝čŗčüą╗ ąĖ ą╝ąŠą│čāčé čāą▓ąĄą┤ąŠą╝ą╗čÅčéčī ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčāčÄ čüčĆąĄą┤čā ąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠą╣ ą┐ą░čāąĘąĄ ą▓ ą┐čĆąĖą║ą╗ą░ą┤ąĮąŠą╝ ą┐čĆąŠčåąĄčüčüąĄ ą▒ąĄąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą▓ąŠąĘą▓čĆą░čēą░čéčīčüčÅ ą║ ąĮąĄą╝čā ąĮąĄą║ąŠč鹊čĆčŗą╣ ą┐ąĄčĆąĖąŠą┤ ą▓čĆąĄą╝ąĄąĮąĖ ąĖą╗ąĖ ąŠ čüąĮąĖąČąĄąĮąĖąĖ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ąĘą░ą┤ą░čćąĖ ą▓ ąŠč湥čĆąĄą┤ąĖ. ą×čüąŠą▒ąŠ čüą╗ąĄą┤čāąĄčé čéą░ą║ąČąĄ ąŠčéą╝ąĄčéąĖčéčī čüąŠč湥čéą░ąĮąĖąĄ WAIT+HLT ąĖ LOOP+HLT, ąŠąĘąĮą░čćą░čÄčēąĖąĄ čÅą▓ąĮąŠąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ č鹊ą│ąŠ ąĖą╗ąĖ ąĖąĮąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ. ąóą░ą║, LOOP+HLT ą╝ąŠąČąĄčé ąŠąĘąĮą░čćą░čéčī ą┐čĆąĄą║čĆą░čēąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ ą║ąŠąĮą║čĆąĄčéąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░. ąóąŠą│ą┤ą░ ą║ą░ą║ WAIT+HLT čüą▓ąĖą┤ąĄč鹥ą╗čīčüčéą▓čāąĄčé ąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą▓čŗą┤ą░čćąĖ ąŠąČąĖą┤ą░ąĄą╝ąŠą│ąŠ čĆąĄčüčāčĆčüą░ ąŠčé čüąĖčüč鹥ą╝čŗ ąĘą░ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗čæąĮąĮčŗą╣ ą┐ąĄčĆąĖąŠą┤. ąÜą░ą║ ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąŠčåąĄą┤čāčĆą░ ą┐ąĄčĆąĄčĆąĖčüąŠą▓ą║ąĖ čāą║ą░ąĘą░č鹥ą╗čÅ ą╝čŗčłąĖ čéčĆąĄą▒čāąĄčé ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠą│ąŠ ą┐čĆąĖčģąŠą┤ą░ čāą▓ąĄą┤ąŠą╝ą╗ąĄąĮąĖčÅ ąŠ čüą╝ąĄąĮąĄ ą┐ąŠąĘąĖčåąĖąĖ ąĮą░ 菹║čĆą░ąĮąĄ ąĖą╗ąĖ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ą┤čĆčāą│ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ, čćč鹊 ą╝ąŠąČąĄčé čāą║ą╗ą░ą┤čŗą▓ą░čéčīčüčÅ ą▓ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥ą╗čīąĮčŗą╣ ąĖąĮč鹥čĆą▓ą░ą╗ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ ą┐ąĄčĆąĖąŠą┤ąĄ ąŠąČąĖą┤ą░ąĮąĖčÅ ą┤ąĄą╣čüčéą▓ąĖą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅŌĆ” ąÆąŠčé ą║čĆą░čéą║ąŠąĄ ąĖ ąĮąĄ ą┤ąŠą║čāą╝ąĄąĮčéą░ą▒ąĄą╗čīąĮąŠąĄ ąĖąĘą╗ąŠąČąĄąĮąĖąĄ čüčāčéąĖ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĮąŠą╣ ą╝ąĮąŠą╣ ąĘą░ą┤ą░čćąĖ. ąÆčŗą┐ąŠą╗ąĮčÅčÄ ą▓čüčæ ą▓ ąŠą┤ąĖąĮąŠčćą║čā, ą╝ąĄą┤ą╗ąĄąĮąĮąŠ, čüąĄčĆą┤ąĖč鹊 ąĖ čüą║čāą┤ąĮąŠ. ąæčŗą╗ ą▒čŗ čĆą░ą┤ 菹ĮčéčāąĘąĖą░čüčéą░ą╝, ą│ąŠč鹊ą▓čŗą╝ ą┐ąŠą┤ą║ą╗čÄčćąĖčéčīčüčÅ ą║ ą┐čĆąŠčĆą░ą▒ąŠčéą║ąĄ ąĮąĄą║ąŠč鹊čĆčŗčģ ąĮčīčÄą░ąĮčüąŠą▓ ą┐čĆąŠąĄą║čéą░. ąĪčéčĆą░ąĮąĖčćą║ą░ ą┐čĆąŠąĄą║čéą░ čü 菹╝čāą╗čÅč鹊čĆąŠą╝ ą┐ąŠą┤ Chrome - ą▓ ąŠą║ąĮąĄ 菹╝čāą╗čÅč鹊čĆą░: F1 - 1 čłą░ą│ 菹╝čāą╗čÅčåąĖąĖ; F4 - ąĘą░ą┐čāčüą║ ą░ą▓č鹊菹╝čāą╗čÅčåąĖąĖ; Alt+1..7 - ą▓čŗą▒ąŠčĆ ą┐čĆąĄčäąĖą║čüą░ ą▓ čéą░ą▒ą╗ąĖčåąĄ ą║ąŠą╝ą░ąĮą┤; Alt+8..0 - čéčĆčÄą║ąŠą▓čŗąĄ ą┐čĆąĄčäąĖą║čüčŗ INT/LOOP/WAIT; Alt+K - ą▒čāč乥čĆ ą║ą╗ą░ą▓ąĖą░čéčāčĆčŗ; Alt+P,T,R - ą┐ąŠą╗ąĄ ą░ą┤čĆąĄčüą░/čéčĆą░ąĮčüą╗čÅč鹊čĆą░/čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. P.S.: ą¤čĆąĖąĮąĖą╝ą░ąĄčéčüčÅ┬Āą░ą┤ąĄą║ą▓ą░čéąĮą░čÅ ą║čĆąĖčéąĖą║ą░.
| ąÆą╗ąŠąČąĄąĮąĖčÅ: |
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą║ čäą░ą╣ą╗čā: ąĪąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ ą┐čĆąŠčåąĄčüčüąŠčĆą░
+ 7 ą┐ą╗ąŠčüą║ąŠčüč鹥ą╣ ą┐čĆąĄčäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣
 0_7x80.gif [177.97 KiB]
0_7x80.gif [177.97 KiB]
ąĪą║ą░čćąĖą▓ą░ąĮąĖą╣: 483
|
_________________
ą» č鹥ą▒čÅ ą┐ąŠą╗čÄą▒ąĖą╗, čÅ č鹥ą▒čÅ ąĮą░čāčćčā! ┬®ąŻčŹčä
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
 |
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
petrenko
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 20:16:25 |
|
ąÜą░čĆą╝ą░: 45
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: -17
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčé č乥ą▓ 21, 2012 13:51:55
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 5114
ą×čéą║čāą┤ą░: ąØą░čćąĖąĮą░čÄčēąĖą╣
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
ąÜčĆąĖčéąĖą║ą░ ą│ąŠą▓ąŠčĆąĖč鹥 ? ąØčā ą╗ą░ą┤ąĮąŠ, čéą░ą║ ąĖ ą▒čŗčéčī - "ą┐ąŠ ą┐čĆąŠčüčīą▒ą░ą╝ čéčĆčāą┤čÅčēąĖčģčüčÅ" ..  ąĢąČąĄą╗ąĖ ą┐čĆąŠčćąĖčéą░čéčī ą▓čüčæ čéą░ą║ąĖ ąÆą░čłčā "ąĮąĄčéą╗ąĄąĮą║čā" ( , ą▓ čłą║ąŠą╗ąŠą╗ąŠčłąĮąŠą╣ čüčĆąĄą┤ąĄ ą╝ąĮąŠą│ąŠą▓ąĄčĆąŠčÅčéąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ąŠą▒ąĘčŗą▓ą░ąĄą╝ąŠ "ą╝ąĮąŠą│ą░ą▒čāą║ą░čäčäąĮąĖą░čüąĖą╗" ) ,č鹊 .. .. ąŠą▒ąĮą░čĆčāąČąĖčéčüčÅ , čćč鹊 čüą╗ąŠą▓ąŠ "ą░čĆčģąĖč鹥ą║čéčāčĆą░", ą│ąŠčĆą┤ąŠ ąĮą░ą┐ąĖčüą░ąĮąĮąŠąĄ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ą║ąĄ, ą║ ąĖąĘą╗ąŠąČąĄąĮąĮąŠą╝čā ąĖą╝ąĄąĄčé ąŠčéą┤ą░ą╗čæąĮąĮąŠąĄ ąĖ ąŠą┐ąŠčüčĆąĄą┤ąŠą▓ą░ąĮąĮąŠąĄ ąŠčéąĮąŠčłąĄąĮąĖąĄ. ąÆčŗ , čüčāą┤ą░čĆčī, čĆąĄąĘą║ąŠ čāą┤ą░čĆąĖą╗ąĖčüčī ą▓ ą╝ąĄą╗ąŠčćąĖ, ą┐ąŠ ą║ąŠč鹊čĆčŗą╝ ą╝ąŠąČąĮąŠ ą╗ąĖčłčī čüą╝čāčéąĮąŠ ą┤ąŠą│ą░ą┤čŗą▓ą░čéčīčüčÅ ąŠą▒ čŹč鹊ą╣ čüą░ą╝ąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ. ąöąŠą▒čĆčŗą╣ čüąŠą▓ąĄčé : čĆą░ąĘ čāąČ čüą║ą░ąĘą░ą╗ąĖ "ąÉ (čĆčģąĖč鹥ą║čéčāčĆą░)" , č鹊 ą┐čĆąĖą▓ąĄą┤ąĖč鹥 ( čéą░ą║, ą┤ą╗čÅ č鹥čģ, ą║č鹊 ą▓ą┤čĆčāą│ ąĮąĄ ą▓ ą║čāčĆčüąĄ) ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čŹč鹊ą│ąŠ čüą░ą╝ąŠą│ąŠ ą┐ąŠąĮčÅčéąĖčÅ, ąĮą░čĆąĖčüčāą╣č鹥 "ąæ (ą╗ąŠą║-čüčģąĄą╝čā)" ąÆą░čłąĄą│ąŠ ą│ąĖą┐ąŠč鹥čéąĖč湥čüą║ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čāą║ą░ąČąĖč鹥 ąŠčüąĮąŠą▓ąĮčŗąĄ ą┐ąŠč鹊ą║ąĖ ąÆ (ą▓ąŠą┤ą░) ąĖ ąÆ (čŗą▓ąŠą┤ą░) ą┤ą░ąĮąĮčŗčģ - čé.ąĄ ą┐ąŠ ą║ą░ą║ąĖą╝ čłąĖąĮą░ą╝ ąĖ ą║ą░ą║ ąŠąĮąĖ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ, ąŠčéą╝ąĄčéčīč鹥 ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĖčé ą╗ąĖ ąÆą░čłą░ "ą░čĆčģąĖč鹥ą║čéčāčĆą░" ą║ čéąĖą┐čā "ąō (ą░čĆą▓ą░čĆą┤čüą║ąŠą╣)" ąĖą╗ąĖ ąĄčēčæ ą║ą░ą║ąŠą╣, ąĮą░čĆąĖčüčāą╣č鹥 ąĮčā čģąŠčéčÅ ą▒čŗ ą┐čĆąĖą╝ąĄčĆąĮčŗąĄ ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄą╝čŗąĄ ą▓čĆąĄą╝ąĄąĮąĮčŗąĄ ąö (ąĖą░ą│čĆą░ą╝ą╝čŗ) , ąĖ čé.ą┤ - ą░ čāąČ ą┐ąŠč鹊ą╝ ą╝ąĄą╗ąŠčćąĖ ąĖ ą┤ąĄčéą░ą╗ąĖ ą▓ čé.čć ą▓čüčÅą║ąĖąĄ čéčĆčÄą║ąĖ ąĖ ąŠčüąŠą▒ąĄąĮąĮąŠčüčéąĖ . ąÜą░ą║ č鹊 čéą░ą║ .. ąóąŠą│ą┤ą░ ąĖ ą▒čāą┤ąĄčé čćč鹊 ąŠą▒čüčāąČą┤ą░čéčī ą┐ąŠ čüčāčēąĄčüčéą▓čā.
_________________
< ą▓ąĖčĆčéčāą░ą╗čīąĮą░čÅ "ą║ąĮąŠą┐ąŠčćą║ą░" >--( WWW ) <- ąŻą▒ąĄą┤ąĖč鹥ą╗čīąĮą░čÅ ą┐čĆąŠčüčīą▒ą░ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╝čüčÅ čüčéą░čĆčŗą╝ąĖ ą║ąŠą╝ą┐čīčÄč鹥čĆą░ą╝ąĖ čéąĖą┐ą░ ąĀąÜ86 - ąĮąĄ ą┐ąĖčłąĖč鹥 ą▓ č鹥ą╝ąĄ ą▓ ą▒ą░čĆą░čģąŠą╗ą║ąĄ, ą┐ąĖčłąĖč鹥 ąÆą░čłąĖ ą▓ąŠą┐čĆąŠčüčŗ ą▓ ( ą╗čü ) ą┐ąŠąČą░ą╗čāą╣čüčéą░
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
DX168B
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 20:34:15 |
|
| ąöčĆčāą│ ąÜąŠčéą░ |
 |
ąÜą░čĆą╝ą░: 25
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 99
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčü čÅąĮą▓ 24, 2010 19:19:52
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 4470
ą×čéą║čāą┤ą░: ąōą╗ą░ą▓ąĮčŗą╣ ąŻą╗ąĄą╣ ąĀąŠčüčüąĖąĖ (Moscow)
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
|
ąŻ ą╝ąĄąĮčÅ ąĖąĮąŠą│ą┤ą░ ą▒čŗą▓ą░ą╗ąĖ "čĆą░ąĘą╝čŗčłą╗ąĄąĮąĖčÅ ąĮą░ čāąĮąĖčéą░ąĘąĄ" ą┐ąŠ ą┐ąŠą▓ąŠą┤čā ą┤ąĄą║ąŠą┤ąĄčĆą░ ą║ąŠą╝ą░ąĮą┤ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąĪčāčéčī ąĘą░ą║ą╗čÄčćą░ą╗ą░čüčī ą▓ č鹊ą╝, čćč鹊 ą▓ ą║ąŠą╝ą░ąĮą┤ąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗą┤ąĄą╗ąĄąĮčŗ ą▒ąĖčéčŗ ą┐čĆąĖąĘąĮą░ą║ą░ čćč鹥ąĮąĖčÅ\ąĘą░ą┐ąĖčüąĖ, ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ąÉąøąŻ, ą║ ą┐ą░ą╝čÅčéąĖ, ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ ąĖ čé.ą┤. ą×čüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ čāąČąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčé ąĮąŠą╝ąĄčĆ ą║ąŠą╝ą░ąĮą┤čŗ. ąöąŠą┐čāčüčéąĖą╝, ą▒ąĖčéčŗ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą╝ąŠąČąĮąŠ čüą▓čÅąĘą░čéčī čü čłąĖąĮąŠą╣ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąŠčĆąŠą╝, ą║ąŠč鹊čĆčŗą╣ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąĖčĆčāąĄčé ą▒ąĖčéčŗ ąĮąŠą╝ąĄčĆą░ ą║ąŠą╝ą░ąĮą┤čŗ ą║ č鹊ą╝čā ąĖą╗ąĖ ąĖąĮąŠą╝čā čāąĘą╗čā, ąĖą╝ąĄčÄčēąĄą╝čā čüą▓ąŠą╣ ą┤ąĄą║ąŠą┤ąĄčĆ. ąóąŠčé čāąČąĄ ąĘą░ą▒ąĖčĆą░ąĄčé ąŠą┐ąĄčĆą░ąĮą┤čŗ ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé ąŠą┐ąĄčĆą░čåąĖčÄ. ąśą╝ąĄčÅ ąĘą░ą┐ą░čü ą┐ąŠ ą▒ąĖčéą░ą╝ ąŠą▒čĆą░čēąĄąĮąĖčÅ, ą┐čĆąŠčåąĄčüčüąŠčĆ ą╝ąŠąČąĮąŠ ą┤ąŠčĆą░čēąĖą▓ą░čéčī čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ čüąŠą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅčéčī ąĮąŠą▓čŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąĢčüą╗ąĖ ąŠą┤ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╝ąĄčüč鹥 čü ąŠą┐ąĄčĆą░ąĮą┤ą░ą╝ąĖ ą▓ą╗ąĄąĘą░ąĄčé ą▓ čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī ą┐čĆąŠčåąĄčüčüąŠčĆą░, č鹊 ą┐ąŠą╝ąĖą╝ąŠ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąŠą╝ąĄčĆą░ ą║ąŠą╝ą░ąĮą┤čŗ, ą╝ąŠąČąĮąŠ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąĖčĆąŠą▓ą░čéčī ąĖ čüą░ą╝ąĖ ąŠą┐ąĄčĆą░ąĮą┤čŗ. ąÆ ąĖč鹊ą│ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖą╝ąĄąĄčé čłą░ąĮčüčŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčīčüčÅ ąĘą░ čéą░ą║čé. ąöą░ąĮąĮčŗą╣ ą┐ąŠą┤čģąŠą┤ čāą┐čĆąŠčēą░ąĄčé ą┤ąĄą║ąŠą┤ąĄčĆ ą║ąŠą╝ą░ąĮą┤ ąĖ ą┤ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą║ ą┤ą░ą╗čīąĮąĄą╣čłąĄą╣ ą╝ąŠą┤ąĄčĆąĮąĖąĘą░čåąĖąĖ.
ąØąŠ čŹč鹊 ą┐čĆąŠčüč鹊 ą╝čŗčüą╗ąĖ čü ąĮą░čüą║ąŠą║čā. ą£ąŠąČąĄčé čéą░ą╝ ąĮą░ą╣ą┤čāčéčüčÅ ąĖ ą┐ąŠą┤ą▓ąŠą┤ąĮčŗąĄ ą║ą░ą╝ąĮąĖ.
ąśą╝ąĄą╗ ą▒čŗ FPGAčģčā ą┐ąŠą┤ čĆčāą║ąŠą╣, ą╝ąŠąČąĄčé ą▒čŗčéčī čćč鹊-ąĮąĖą▒čāą┤čī ąĖ ą┐ąŠą┐čĆąŠą▒ąŠą▓ą░ą╗ ą▒čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī.
_________________
I am DX168B and this is my favourite forum on internet!
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
petrenko
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: "čĆą░ąĘą╝čŗčłą╗ąĄąĮąĖčÅ ąĮą░ čāąĮąĖčéą░ąĘąĄ" ąŠą▒ čāą╗čāčćčłą░ą╣ąĘąĖąĮą│ąĄ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 20:41:12 |
|
ąÜą░čĆą╝ą░: 45
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: -17
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčé č乥ą▓ 21, 2012 13:51:55
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 5114
ą×čéą║čāą┤ą░: ąØą░čćąĖąĮą░čÄčēąĖą╣
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
DX168B ą┐ąĖčüą░ą╗(ą░): .. "čĆą░ąĘą╝čŗčłą╗ąĄąĮąĖčÅ ąĮą░ čāąĮąĖčéą░ąĘąĄ"* ..
.. ąś ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖą╝ąĄąĄčé čłą░ąĮčüčŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčīčüčÅ ąĘą░ čéą░ą║čé**. ąöą░ąĮąĮčŗą╣ ą┐ąŠą┤čģąŠą┤ ... *_ą¤ąŠą┤čģąŠą┤čÅčēąĖą╣ 菹┐ąĖč鹥čé. **_ąś , ą║ą░ą║ čŹč鹊 ąĮąĖ čüą║čāčćąĮąŠ, ąĮąŠ "ą▓čüčæ čāąČąĄ ą┐čĆąĖą┤čāą╝ą░ąĮąŠ ą┤ąŠ ąĮą░čü ąĖ ą▒ąĄąĘ ąĮą░čü" - ą▓ą┐ąŠą╗ąĮąĄ N-ąĮąŠąĄ čćąĖčüą╗ąŠ ą╗ąĄčé čāąČąĄ ą▓ąŠą▓čüčÄ ą║ą╗ąĄą┐ą░čÄčé "ąŠą┤ąĮąŠčéą░ą║č鹊ą▓ąŠąĄ čÅą┤čĆąŠ" ą┤ą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą░čĆčģąĖč鹥ą║čéčāčĆ.
_________________
< ą▓ąĖčĆčéčāą░ą╗čīąĮą░čÅ "ą║ąĮąŠą┐ąŠčćą║ą░" >--( WWW ) <- ąŻą▒ąĄą┤ąĖč鹥ą╗čīąĮą░čÅ ą┐čĆąŠčüčīą▒ą░ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╝čüčÅ čüčéą░čĆčŗą╝ąĖ ą║ąŠą╝ą┐čīčÄč鹥čĆą░ą╝ąĖ čéąĖą┐ą░ ąĀąÜ86 - ąĮąĄ ą┐ąĖčłąĖč鹥 ą▓ č鹥ą╝ąĄ ą▓ ą▒ą░čĆą░čģąŠą╗ą║ąĄ, ą┐ąĖčłąĖč鹥 ąÆą░čłąĖ ą▓ąŠą┐čĆąŠčüčŗ ą▓ ( ą╗čü ) ą┐ąŠąČą░ą╗čāą╣čüčéą░
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
ą×čĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą┐ąĖčéą░ąĮąĖčÅ ąĮą░ ąŠčüąĮąŠą▓ąĄ ąĮą░ą┤ąĄąČąĮčŗčģ ą╗ąĖčéąĖąĄą▓čŗčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ EVE ąĖ ą╝ąĖą║čĆąŠčüčģąĄą╝ ą░ąĘąĖą░čéčüą║ąŠą│ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤čüčéą▓ą░
ąÜą░č湥čüčéą▓ąĄąĮąĮąŠąĄ ąĖ ą▒ąĄąĘąŠą┐ą░čüąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, čĆą░ą▒ąŠčéą░čÄčēąĄąĄ ąŠčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░, ą┤ąŠą╗ąČąĮąŠ čāčćąĖčéčŗą▓ą░čéčī ąĄą│ąŠ čäąĖąĘąĖč湥čüą║ąĖąĄ ąĖ čģąĖą╝ąĖč湥čüą║ąĖąĄ čüą▓ąŠą╣čüčéą▓ą░, ą┐čĆąŠčäąĖą╗ąĖ ąĘą░čĆčÅą┤ą░ ąĖ čĆą░ąĘčĆčÅą┤ą░, ąĖčģ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ą▓ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąĖ ą┐ąŠą┤ ą▓ą╗ąĖčÅąĮąĖąĄą╝ čĆą░ąĘą╗ąĖčćąĮčŗčģ čāčüą╗ąŠą▓ąĖą╣, čéą░ą║ąĖčģ ą║ą░ą║ č鹥ą╝ą┐ąĄčĆą░čéčāčĆą░ ąĖ č鹊ą║ ąĮą░ą│čĆčāąĘą║ąĖ. ą£čŗ čĆą░čüčüą║ą░ąČąĄą╝ ąŠ ą╗ąĖčéąĖą╣-ąĖąŠąĮąĮčŗčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĮčŗčģ ą▒ą░čéą░čĆąĄčÅčģ EVE ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄčłąĄąĮąĖčÅčģ ąŠčé čĆą░ąĘą╗ąĖčćąĮčŗčģ ą║ąĖčéą░ą╣čüą║ąĖčģ ą║ąŠą╝ą┐ą░ąĮąĖą╣, čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄą╝čŗčģ ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠč鹊ą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čŹčéąĖčģ ąÉąÜąæ. ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮčŗąĄ ą▓ čüčéą░čéčīąĄ ą║ąĖčéą░ą╣čüą║ąĖąĄ ą░ąĮą░ą╗ąŠą│ąĖ ą┐ąŠą╝ąŠą│čāčé ąĘą░ą╝ąĄąĮąĖčéčī ą┐čĆąŠą┤čāą║čåąĖčÄ ąĘą░ą┐ą░ą┤ąĮčŗčģ ą▒čĆąĄąĮą┤ąŠą▓ čü ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣ čåąĄąĮčŗ ą▒ąĄąĘ ą┐ąŠč鹥čĆąĖ ą║ą░č湥čüčéą▓ą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ>>
|
|
|
|
|
|
|
Paguo-86PK
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 20:59:26 |
|
| ą×ą┐čŗčéąĮčŗą╣ ą║ąŠčé |
|
ąÜą░čĆą╝ą░: 15
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 16
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¦čé ą░ą▓ą│ 19, 2010 23:49:19
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 803
ą×čéą║čāą┤ą░: ąóą░čłą║ąĄąĮčé
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
ąĀą░ą▒ąŠčéačÄčēąĖą╣ 菹╝čāą╗čÅč鹊čĆ ąĖ ąĘą░ą┐čāčüą║ą░ąĄą╝ą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ "ą£ąŠąĮąĖč鹊čĆ" (BIOS ) - ą┤čāą╝ą░ą╗, čćč鹊 ą▒ąŠą╗ąĄąĄ, č湥ą╝ ą┤ąŠčüčéą░č鹊čćąĮąŠ, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī, čćč鹊 ąĘą░ą┤čāą╝ą║čā ą▓ąŠą┐ą╗ąŠčéąĖą╗. ą¤čāčüčéčī ą┤ą░ąČąĄ ą┐ąŠą║ą░ ą▓ HTML5+JS. ąÆ ąĖčüčģąŠą┤ąĮąĖą║ąĄ čāą▓ąĖą┤ąĖč鹥 čüą╗ąĄą┤čāčÄčēąĖą╣ ą▒ą╗ąŠą║: ąÜąŠą┤: +----------=> $L:Lock-mask
| +----------=> $K:Keep code
| | +---------=> $Z:PREFIX #Z
| | | +-------=> $J:
| | | | +-----=> $Y:
| | | | | +---=> $I:
| | | | | | +-=> $X:
| | | | | | |
/|\/|\/|\|/|\|/|\
LLLKKKZZZJYYYIXXX_
XXX00000000000C HLT :IS_BOOT ? IS_WAIT ? CR(0, ACC( ) ) : FH(8 ) : (CR(CR(0 ) & 0xF0 ) , FH(0xB ) , FL(0x5 ) ) // Halting
XXX00011111110C NOP :$IB==$IB // No operation
0000000XXX0XXX_ PREFIX R#X/P#X :0 // Prefix for R#X!/P#X!
X1000011101XXXE PUSH+ U#X :HEAP(U#X( ) ) // Push pointer into stack
X1000011111XXXE POP+ U#X :U#X(HEAP( ) ) // Pop pointer from stack
XXXXXX11111110C NOP #Z :#Z // Hollow operation through #Z ticks
XXX10010101XXXA ALU#X IB :$1=ALU#X(DROP(FH( ) ) ,$IB ) ,ACC($1 ) ,FL($1.hi( ) ) // ALU#X! with retained and immediate
XXXXXX10101XXXA ALU#X Z#Z,IB :$1=ALU#X(Z#Z( ) ,$IB ) ,Z#Z($1 ) ,FL($1.hi( ) ) // ALU#X! with Z#Z! and byte
XXX1000XXX1XXXA ALU#X Z#Y :$1=ALU#X(DROP(#Y ) ,REG(#Y ) ) ,REG(#Y,$1 ) ,FL($1.hi( ) ) // ALU#X! with Z#Y! and retained
XXXXXX0XXX1XXXA ALU#X Z#Z,R#Y :$1=ALU#X(Z#Z( ) ,R#Y( ) ) ,Z#Z($1 ) ,FL($1.hi( ) ) // ALU#X! with Z#Z! and R#Y!
000XXX0XXX0XXXC HLT #Z :IS_BOOT && IS_WAIT ? FH( ) ==(#Z+8 ) ? ACC(PORT(ACC( ) ) ) : FH( ) >=8 ? PORT(R#Z( ) ,ACC( ) ) : CR(#Z,ACC( ) ) : FH(#Z+8 ) // Hold #Z index number
X1000011001XXXD INC+ Q#X :Q#X(Q#X( ) +1 ) // Increment Q#X!
X1000011011XXXD DEC+ Q#X :Q#X(Q#X( ) -1 ) // Decrement Q#X!
XXX00011001111A CMC :FL(FL( ) ^ 2 ) // Complement carry flag
XXXXXX11001110D ADC BX,T#Z :$1=BX( ) +T#Z( ) +(_CF?1:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , BX($1 ) // Addition register pair with carry
X10XXX11001XXXD ADD Q#X,T#Z :$1=Q#X( ) +T#Z( ) +(_CF?0:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , Q#X($1 ) // Addition register pair
XXXXXX11011110D SBB BX,T#Z :$1=BX( ) -T#Z( ) -(_CF?1:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , BX($1 ) // Subtraction register pair with borrow
X10XXX11011XXXD SUB Q#X,T#Z :$1=Q#X( ) -T#Z( ) -(_CF?0:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , Q#X($1 ) // Subtraction register pair
XXX00011001010A XCHG :$1=ACC( ) ; for($2=0,$0=0;$0<8;++$0,$1>>=1 ) $2=($2<<1 ) +($1&1 ) ; ACC($2 ) >0 // Exchange retained bits by mirror
XXXXXX11001010A XCHG P#Z :$1=DST( ) ,DST(P#Z( ) ) ,P#Z($1 ) // Exchange P#Z! with retained pair
XXXXXX11001111A XCHG R#Z :$1=ACC( ) ,ACC(R#Z( ) ) ,R#Z($1 ) // Exchange R#Z! with retained register
XXX100110X1XXXA ALU#W :$1=ACC(ALU#W(ACC( ) ) ) ,FL($1.hi( ) ) // ALU#W! with retained
XXXXXX110X1XXXA ALU#W Z#Z :$1=Z#Z(ALU#W(Z#Z( ) ) ) ,FL($1.hi( ) ) // ALU#W! with Z#Z!
X111000XXX0000A MUL R#Y :0 //
X1110000000XXXF XCHG R#X :$1=ACC( ) ,ACC(R#X( ) ) ,R#X($1 ) // Exchange R#Z! with retained register
X111000XXX0100F XCHG P#Y :$1=DST( ) ,DST(P#Y( ) ) ,P#Y($1 ) // Exchange P#Z! with retained pair
X111000XXX0XXXF MOV P#X,T#Y :P#X(T#Y( ) ) // Move T#Y! vector to P#X!
01110000000XXXD_PUSH+ T#X+[T#Y] :HEAP(T#X( ) +DW(T#Y( ) ) ) // Correct effective address in stack
0111000XXX0XXXD_PUSH+ T#X+T#Y :HEAP(T#X( ) +T#Y( ) ) // Push effective address into stack
1111000XXX0000D_PUSH+ [T#X]-T#Y :HEAP(HEAP( ) -T#Y( ) ) // Correct effective address in stack
1111000XXX0XXXD_PUSH+ T#X-T#Y :HEAP(T#X( ) -T#Y( ) ) // Push effective address into stack
XXXXXX00000000C HLT R#Z :IS_WAIT ? FH( ) == #Z ? ACC(CTX(ACC( ) ) ) : $IR ? CTX(ACC( ) ,R#Z( ) ) : R#Z(CR(FH( ) ) ) : FH(#Z ) // Hold R#Z!/P#Z! as retained
XXX0000XXX0XXXF MOV R#X,R#Y :IS_WAIT && true ? #Y == 0 ? ($1=PORT(R#X( ) ) ,trace.eady?R#X($1 ) :0 ) : PORT(R#X( ) ,R#Y( ) ) : R#X(R#Y( ) ) // Move R#Y! data into R#X!
X11XXX0XXX0XXXD_ALU#Z P#X,T#Y :0 //
XXX00010110000B JCND#X $+IB :CND#X?IP(IP( ) +$IV ) :0 // Relative branching if CND#X!
XXX00010100XXXF MOV R#X,IB :R#X($IB ) // Move immediate data into R#X!
XXX00010110001E BIAS $+IB :HEAP($IP+$IV ) // Push instruction based relative address
XXX00010110XXXB CCND#X $+IB :CND#X?HEAP(IP( ) ) +IP(IP( ) +$IV ) :0 // Relative call if CND#X!
XXX00011000XXXA INC+ R#X :$1=ADD(R#X( ) ,1 ) ,R#X($1 ) ,FL($1.hi( ) ) // Increment R#X!
XXX00011010XXXA DEC+ R#X :$1=SUB(R#X( ) ,1 ) ,R#X($1 ) ,FL($1.hi( ) ) // Decrement R#X!
X00XXX1111XXXXB INT #T :HEAP($IP ) +IP(JP(#T<10?0:1 ) ) >0 // Programm interruption indexed by #T
XXX10011101110F XCHG [SP] :$1=DST( ) ,DST(DW($2=SP( ) ) ) , DW($2, $1 ) // Exchange retained pair with stack heap
XXXXXX11101110F XCHG P#Z,[SP] :$1=P#Z( ) ,P#Z(DW(SP( ) ) ) , DW(SP( ) , $1 ) // Exchange pair P#Z with stack heap
001XXX0XXX0XXXF XCHG P#Z,P#Y :$1=P#Z( ) ,P#Z(P#Y( ) ) ,P#Y($1 ) // Exchange P#Z! and P#Y!
010XXX0XXX0XXXF XCHG R#Z,R#Y :$1=R#Z( ) ,R#Z(R#Y( ) ) ,R#Y($1 ) // Exchange R#Z! and R#Y!
011XXX0XXX0XXXD LEA P#Z,T#X+T#Y :P#Z(T#X( ) +T#Y( ) ) // Load T#X!+T#Y! effective address into P#Z
111XXX0XXX0XXXD LEA P#Z,T#X-T#Y :P#Z(T#X( ) -T#Y( ) ) // Load T#X!-T#Y! effective address into P#Z
XXXXXX10100000E POP+ [P#Z+IB] :DW(P#Z( ) +$IV,HEAP( ) ) // Pop data into memory indexed by P#Z
XXXXXX10100XXXF MOV R#X,[P#Z+IB] :trace.is_port=IP_BP; trace.is_context=IP_SP; R#X(DB(P#Z( ) +$IV ) ) // Move memory data by P#Z pointer into R#X
XXXXXX10110000E PUSH+ [P#Z+IB] :HEAP(DW(P#Z( ) +$IV ) ) // Push data from memory indexed by P#Z
XXXXXX10110XXXF MOV [P#Z+IB],R#X :trace.is_port=IP_BP; trace.is_context=IP_SP; DB(P#Z( ) +$IV,R#X( ) ) // Move R#X register data into memory by P#Z
XXX10011101111E PUSH :HEAP(DST( ) ) // Push retained pair
XXXXXX11101111E PUSH+ S#Z :HEAP(S#Z( ) ) // Push service S#Z register pair to stack
XXX10011111111E POP :DST(HEAP( ) ) // Pop retained pair
XXXXXX11111111E POP+ S#Z :S#Z(HEAP( ) ) // Pop service S#Z register pair from stack
XXXXXX11101010E PUSH+ R#Z :DUP(#Z ) // Dup R#Z register history
XXXXXX11101011C SKIP [R#Z] :FH(R#Z( ) |8 ) ,FL((FL( ) & 0x02 ) | 0x05 ) // Exclude next operations by R#Z bits
XXXXXX11101100C SKIP R#Z :FH(#Z ) , FL((FL( ) & 0x02 ) | 0x05 ) // Exclude next operations by R#Z counter
XXXXXX11101101C SKIP #Z :FH(#Z | 8 ) , FL((FL( ) & 0x02 ) | 0x05 ) // Exclude next operations by #Z times
XXXXXX11111010E POP+ R#Z :DROP(#Z ) // Drop R#Z register history
XXXXXX11111011C LOOP [R#Z] :FH(R#Z( ) |8 ) ,FL((FL( ) & 0x02 ) | 0x09 ) // Forcing next operation by R#Z bits
XXXXXX11111100C LOOP R#Z :FH(#Z ) , FL((FL( ) & 0x02 ) | 0x09 ) // Forcing next operation by R#Z counter
XXXXXX11111101C LOOP #Z :FH(#Z | 8 ) , FL((FL( ) & 0x02 ) | 0x09 ) // Forcing next operation by #Z times
XXXXXX100XXXXXE PUSH+ #VIB :HEAP(0x#V00 + $IB ) // Push immediate data into stack
0XX10010111XXXX --- IB :return 0 // Reserved extended code
XXX10010111010E LEA +IB :DST(DST( ) +$IB ) // Load retained effective address
X1010010111XXXF MOV [U#X],IB :DB(U#X( ) ,$IB ) // Load immediate data into memory by U#X
XXXXXX10111000B JMP $+#UIB :$IW==-2?(FL((FL( ) & 0x02 ) | 0x0D ) ,trace.expression=0 ) :IP(IP( ) +$IW ) // Unonditional relative branching
XXXXXX10111001B CALL $+#UIB :$IW==-2?0:HEAP(IP(IP( ) +$IW ) ) // Unconditional relative call
XXXXXX10111XXXB JCND#X $+#UIB :CND#X?IP(IP( ) +$IW ) :0 // Branching if CND#X!
XXXXXXXXXXXXXXX --- :return 0 // Reserved code ą¦č鹊 ą┤ąŠčüčéą░č鹊čćąĮąŠ ąĮąĄčüą╗ąŠąČąĮąŠ ą▓ ą┐ąĄčĆčüą┐ąĄą║čéąĖą▓ąĄ ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī ą▓ Verilog-ą╝ąŠą┤čāą╗čī. ąóąĖčģąŠ, ąĮąŠ ą┤ą▓ąĖą│ą░čÄčüčī ą║ čŹč鹊ą╣ čäą░ąĘąĄ, čéą░ą║ ąĖą╗ąĖ ąĖąĮą░č湥. ąÉ ąĮą░čüčćčæčé ą░čĆčģąĖč鹥ą║čéčāčĆčŗ. ąØą░ą▓ąĄčĆąĮąŠąĄ, čÅ čüąĖą╗čīąĮąŠ ąŠčłąĖą▒ą░čÄčüčī, čĆą░ąĘ čćąĖčéą░čÄ ą┤ąŠčüčéą░č鹊čćąĮąŠ čĆąĄąĘą║čāčÄ ą║čĆąĖčéąĖą║čā ą▓ čüč鹊čĆąŠąĮčā čŹč鹊ą│ąŠ č鹥čĆą╝ąĖąĮą░ ą╝ąŠąĄą╣ čüč鹊čĆąŠąĮčŗ. ąĢčüą╗ąĖ čÅ ąĮąĄ ąŠč湥ąĮčī ąŠčłąĖą▒ą░čÄčüčī, ąĖą╝ąĄąĮąĮąŠ ą░čĆčģąĖč鹥ą║čéčāčĆąŠą╣ ąÆą£80 ąŠą┐ąĖčüčŗą▓ą░ą╗ąŠčüčī, čćč鹊 ą▓čüąĄ ą░čĆąĖčäą╝ąĄčéąĖą║ąŠ-ą╗ąŠą│ąĖč湥čüą║ąĖąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčéčüčÅ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝; čćč鹊 ąĖą╝ąĄąĄčéčüčÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą┤ąŠ 256 ąŻąÆąÆ; čćč鹊 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą░ą┤čĆąĄčüčāąĄą╝ąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ - 64ą║ą▒; čćč鹊 ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą┐čĆčÅą╝ą░čÅ ąĖ ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅŌĆ” ąśąĘą▓ąĖąĮčÅčÄčüčī, ąĮąŠ čĆą░ąĘą▓ąĄ čÅ ąĮąĄ ą┤ąŠčüčéą░č鹊čćąĮąŠ čāą┤ąĄą╗ąĖą╗ ą▓ąĮąĖą╝ą░ąĮąĖčÅ čŹčéąĖą╝ ą┤ąĄčéą░ą╗čÅą╝? P.S.: ąæą╗ą░ą│ąŠą┤ą░čĆčÄ┬ĀąĘą░ ą║čĆąĖčéąĖą║čā. ąæčāą┤čā ąĖčüą┐čĆą░ą▓ą╗čÅčéčī (ąŠą┐ąĖčüą░ąĮąĖąĄ ąÉčĆčģąĖč鹥ą║čéčāčĆčŗ ) ŌĆ”
_________________
ą» č鹥ą▒čÅ ą┐ąŠą╗čÄą▒ąĖą╗, čÅ č鹥ą▒čÅ ąĮą░čāčćčā! ┬®ąŻčŹčä
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
ąØąŠą▓čŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ EVE čüąĄčĆąĖąĖ PLM ą┤ą╗čÅ GSM-čéčĆąĄą║ąĄčĆąŠą▓, čĆą░ą▒ąŠčéą░čÄčēąĖčģ ą▓ ąČčæčüčéą║ąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ (ą┤ąŠ -40┬░ąĪ)
ąÜąŠą╝ą┐ą░ąĮąĖčÅ EVE ą▓čŗą┐čāčüčéąĖą╗ą░ ąĮąŠą▓čŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ čüąĄčĆąĖąĖ PLM, čüąŠč湥čéą░čÄčēąĖą╣ ą▓ čüąĄą▒ąĄ ą▓čŗčüąŠą║čāčÄ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéčī, ą┤ą╗ąĖč鹥ą╗čīąĮčŗą╣ čüčĆąŠą║ čüą╗čāąČą▒čŗ, čłąĖčĆąŠą║ąĖą╣ č鹥ą╝ą┐ąĄčĆą░čéčāčĆąĮčŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ ąĖ ą▓čŗčüąŠą║čāčÄ č鹊ą║ąŠąŠčéą┤ą░čćčā ą┤ą░ąČąĄ ą┐čĆąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą╣ č鹥ą╝ą┐ąĄčĆą░čéčāčĆąĄ.
ąŁčéąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ąĘą░čĆčÅą┤ ą┐čĆąĖ č鹥ą╝ą┐ąĄčĆą░čéčāčĆąĄ ąŠčé -40/-20┬░ąĪ (čüąĮąĖąČąĄąĮąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ č鹊ą║ą░), ą▒ąĄąĘąŠą┐ą░čüąĮčŗ (ąĮąĄ ą▓ąŠčüą┐ą╗ą░ą╝ąĄąĮčÅčÄčéčüčÅ ąĖ ąĮąĄ ą▓ąĘčĆčŗą▓ą░čÄčéčüčÅ) ą┐čĆąĖ ą╝ąĄčģą░ąĮąĖč湥čüą║ąŠą╝ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĖąĖ (ą┐čĆąŠčéčŗą║ą░ąĮąĖąĄ ąĖ čüą┤ą░ą▓ą╗ąĖą▓ą░ąĮąĖąĄ), čāčüč鹊ą╣čćąĖą▓čŗ ą║ ą▓ąĖą▒čĆą░čåąĖąĖ. ą×ąĮąĖ ą╝ąŠą│čāčé ą┐čĆąĖą╝ąĄąĮčÅčéčīčüčÅ ą║ą░ą║ ą┤ą╗čÅ ą░ą▓č鹊čéčĆą░ąĮčüą┐ąŠčĆčéą░ (čéčĆąĄą║ąĄčĆčŗ, ą╝ą░čÅčćą║ąĖ, čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖčÅ), čéą░ą║ ąĖ ą┤ą╗čÅ ą┐čĆąŠą╝čŗčłą╗ąĄąĮąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░, IoT-čāčüčéčĆąŠą╣čüčéą▓.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ>>
|
|
|
|
|
|
|
DX168B
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: "čĆą░ąĘą╝čŗčłą╗ąĄąĮąĖčÅ ąĮą░ čāąĮąĖčéą░ąĘąĄ" ąŠą▒ čāą╗čāčćčłą░ą╣ąĘąĖąĮą│ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 21:01:55 |
|
| ąöčĆčāą│ ąÜąŠčéą░ |
|
ąÜą░čĆą╝ą░: 25
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 99
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčü čÅąĮą▓ 24, 2010 19:19:52
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 4470
ą×čéą║čāą┤ą░: ąōą╗ą░ą▓ąĮčŗą╣ ąŻą╗ąĄą╣ ąĀąŠčüčüąĖąĖ (Moscow)
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
petrenko ą┐ąĖčüą░ą╗(ą░): ąś , ą║ą░ą║ čŹč鹊 ąĮąĖ čüą║čāčćąĮąŠ, ąĮąŠ "ą▓čüčæ čāąČąĄ ą┐čĆąĖą┤čāą╝ą░ąĮąŠ ą┤ąŠ ąĮą░čü ąĖ ą▒ąĄąĘ ąĮą░čü" - ą▓ą┐ąŠą╗ąĮąĄ N-ąĮąŠąĄ čćąĖčüą╗ąŠ ą╗ąĄčé čāąČąĄ ą▓ąŠą▓čüčÄ ą║ą╗ąĄą┐ą░čÄčé "ąŠą┤ąĮąŠčéą░ą║č鹊ą▓ąŠąĄ čÅą┤čĆąŠ" ą┤ą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą░čĆčģąĖč鹥ą║čéčāčĆ. ąś ą║ą░ą║ ąĮąĖ čüčéčĆą░ąĮąĮąŠ, čéą░ą║ąĖąĄ ą╝čŗčüą╗ąĖ ą▒čŗą▓ą░čÄčé ą┐ąŠą╗ąĄąĘąĮčŗą╝ąĖ ą┤ą╗čÅ čüą░ą╝ąŠčĆą░ąĘą▓ąĖčéąĖčÅ. ąś ą▓čüąĄčéą░ą║ąĖ ą╝ąĮąĄ ąĖąĮč鹥čĆąĄčüąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą▒ąŠą╗čéą░čéčī ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąŠčüčéčĆąŠąĖč鹥ą╗čīčüčéą▓ąĄ. ą¤ąŠčÅčüąĮčÄ čüą▓ąŠčÄ ąĖą┤ąĄčÄ: ąöąŠą┐čāčüčéąĖą╝, ąĮą░čłą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ąŠčüčīą╝ąĖą▒ąĖčéąĮąŠą╣. ąöąĄą╗ąĖą╝ ąĄąĄ ąĮą░ ą┤ą▓ąĄ čćą░čüčéąĖ. ąØą░ ą┤ą▓ąĄ č鹥čéčĆą░ą┤čŗ ą║ ą┐čĆąĖą╝ąĄčĆčā. ą£ą╗ą░ą┤čłą░čÅ č鹥čéčĆą░ą┤ą░ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ ą░ą┤čĆąĄčü čāąĘą╗ą░, ą║ąŠč鹊čĆąŠą╝čā ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮą░ čüčéą░čĆčłą░čÅ č鹥čéčĆą░ą┤ą░ ą║ąŠą╝ą░ąĮą┤čŗ, ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčēą░čÅ čüąŠą▒ąŠą╣ ąĮąŠą╝ąĄčĆ ą║ąŠą╝ą░ąĮą┤čŗ. ąŁč鹊ą╝čā ąČąĄ čāąĘą╗čā čüčĆą░ąĘčā ąČąĄ ą╝ąŠąČąĮąŠ ą┐ąĄčĆąĄą┤ą░čéčī ąĖ ąŠą┐ąĄčĆą░ąĮą┤čŗ. ą¤ąŠą╗čāčćą░ąĄą╝ čüą╗ąĄą┤čāčÄčēčāčÄ ą╝ąŠą┤ąĄą╗čī čĆą░ą▒ąŠčéčŗ. ą¤čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆą▓čŗą╣ čéą░ą║čé. ąśąĘ ą┐ą░ą╝čÅčéąĖ ąĘą░ą▒ąĖčĆą░ąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ čü ąŠą┐ąĄčĆą░ąĮą┤ą░ą╝ąĖ ąĖ ąĘą░ąĮąŠčüąĖčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ą║ąŠą╝ą░ąĮą┤čŗ. ąÜą░ą║ ąŠąĮą░ čéčāą┤ą░ ą┐ąŠą┐ą░ą┤ą░ąĄčé, ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąŠčĆ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčé ąŠčüčéą░ą▓čłąĖąĄčüčÅ ą▓čŗčģąŠą┤čŗ (ą║čĆąŠą╝ąĄ ą▓čŗčģąŠą┤ąŠą▓ ą╝ą╗ą░ą┤čłąĄą╣ č鹥čéčĆą░ą┤čŗ ą║ąŠą╝ą░ąĮą┤čŗ ) čĆąĄą│ąĖčüčéčĆą░ ą║ąŠą╝ą░ąĮą┤čŗ, čüąŠą│ą╗ą░čüąĮąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝čā ą╝ą╗ą░ą┤čłąĄą╣ č鹥čéčĆą░ą┤čŗ, ą║ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╝čā čāąĘą╗čā. ąóąŠčé ąĖą╝ąĄąĄčé čüą▓ąŠąĖ čĆąĄą│ąĖčüčéčĆčŗ-ąĘą░čēąĄą╗ą║ąĖ ąĮą░ ą▓čģąŠą┤ąĄ ąĖ ą┐ąŠą╗čāč湥ąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čäąĖą║čüąĖčĆčāčÄčéčüčÅ ą▓ ąĮąĖčģ. ą¤čĆąŠąĖčüčģąŠą┤ąĖčé ą▓č鹊čĆąŠą╣ čéą░ą║čé. ąŻąĘąĄą╗ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą║ąŠą╝ą░ąĮą┤čā, ą░ ą▓ čĆąĄą│ąĖčüčéčĆ ą║ąŠą╝ą░ąĮą┤čŗ ąĘą░ąĮąŠčüąĖčéčüčÅ čüą╗ąĄą┤čāčÄčēą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖąĘ ą¤ąŚąŻ. ą£ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī čĆąĄą│ąĖčüčéčĆ ą║ąŠą╝ą░ąĮą┤ ą▓ ą▓ąĖą┤ąĄ FIFO ą▒čāč乥čĆą░, čćč鹊ą▒čŗ ąĮąĄ čüč鹊ą┐ąŠčĆąĖčéčīčüčÅ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ą╝ąĮąŠą│ąŠčéą░ą║čéąĮčŗčģ ą║ąŠą╝ą░ąĮą┤. ą£ąŠąČąĮąŠ čŹč鹊čé "ą║ąŠąĮą▓ąĄą╣ąĄčĆ" čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą▓ ą▓ąĖą┤ąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą║ąŠą╝ą░ąĮą┤, čćč鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąĘą░čĆą░ąĮąĄąĄ ą║ą░ą║ąĖąĄ-ąĮąĖą▒čāą┤čī ą┐ąŠą┤ą│ąŠč鹊ą▓ąĖč鹥ą╗čīąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┐ąŠą┐ą░ą▓čłąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ FIFO ą▒čāč乥čĆ.
_________________
I am DX168B and this is my favourite forum on internet!
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
petrenko
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: "čĆą░ąĘą╝čŗčłą╗ąĄąĮąĖčÅ ąĮą░ čāąĮąĖčéą░ąĘąĄ" ąŠą▒ čāą╗čāčćčłą░ą╣ąĘąĖąĮą│ąĄ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 21:28:29 |
|
ąÜą░čĆą╝ą░: 45
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: -17
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčé č乥ą▓ 21, 2012 13:51:55
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 5114
ą×čéą║čāą┤ą░: ąØą░čćąĖąĮą░čÄčēąĖą╣
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
petrenko ą┐ąĖčüą░ą╗(ą░): ąś , ą║ą░ą║ čŹč鹊 ąĮąĖ čüą║čāčćąĮąŠ, ąĮąŠ "ą▓čüčæ čāąČąĄ ą┐čĆąĖą┤čāą╝ą░ąĮąŠ ą┤ąŠ ąĮą░čü ąĖ ą▒ąĄąĘ ąĮą░čü" - ą▓ą┐ąŠą╗ąĮąĄ N-ąĮąŠąĄ čćąĖčüą╗ąŠ ą╗ąĄčé čāąČąĄ ą▓ąŠą▓čüčÄ ą║ą╗ąĄą┐ą░čÄčé "ąŠą┤ąĮąŠčéą░ą║č鹊ą▓ąŠąĄ čÅą┤čĆąŠ" ą┤ą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą░čĆčģąĖč鹥ą║čéčāčĆ. DX168B ą┐ąĖčüą░ą╗(ą░): ąś ,ą║ą░ą║ ąĮąĖ čüčéčĆą░ąĮąĮąŠ, čéą░ą║ąĖąĄ ą╝čŗčüą╗ąĖ ą▒čŗą▓ą░čÄčé ą┐ąŠą╗ąĄąĘąĮčŗą╝ąĖ ą┤ą╗čÅ čüą░ą╝ąŠčĆą░ąĘą▓ąĖčéąĖčÅ*.
ąś ą▓čüąĄ čéą░ą║ąĖ ą╝ąĮąĄ ąĖąĮč鹥čĆąĄčüąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą▒ąŠą╗čéą░čéčī ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąŠčüčéčĆąŠąĖč鹥ą╗čīčüčéą▓ąĄ .. *_ąĪąŠą▓ąĄčĆąĄčłąĄąĮąĮąŠ ą▓ąĄčĆąĮąŠ ! ąśą╝ąĄąĮąĮąŠ ą┤ą╗čÅ čüą░ą╝ąŠąŠą▒čāč湥ąĮąĖčÅ - ąĮą░ąĖą╗čāčćčłąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ! ąØčā ąĖ ąĄčēčæ ą╝ąŠąČąĮąŠ ą┤ą╗čÅ ą┤ąŠčüčāą│ąŠą▓čŗčģ čåąĄą╗ąĄą╣ č鹊ąČ . ą×ą┤ąĮą░ ąĖąĘ ąÆą░čłąĖčģ ą╝čŗčüą╗ąĄą╣ ą┐ąŠ čüčāčéąĖ ą┐ąŠą┤čģąŠą┤ąĖčé ą┐ąŠčćčéąĖ ą▓ą┐ą╗ąŠčéąĮčāčÄ ą║ čāąČąĄ čüčāčēąĄčüčéą▓čāčÄčēąĄą╣ ąĖą┤ąĄąĄ čāą┐čĆą░ą▓ą╗čÅčÄčēąĄą│ąŠ čÅą┤čĆą░ ą▒ąĄąĘ ą░.ą╗.čā. - č鹊ą╗čīą║ąŠ "čĆčāą╗ąĄąĮąĖąĄ" čłąĖąĮą░ą╝ąĖ ąĖ ą┐ąĄčĆąĄą┤ą░čćą░ ąĘą░ą┤ą░ąĮąĖą╣ ą░.ą╗.čā.( ąĖčģ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ) ąĖ ą▓ ą┤čĆ. ąŠą▒čĆą░ą▒ą░čéčŗą▓čÄčēąĖąĄ čāčüčéčĆąŠą╣čüčéą▓ą░. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ ąĮą░ nedopc.org/forum čāąČąĄ ąŠą▒čüčāąČą┤ą░ą╗čüčÅ ą┐čĆąĖąĮčåąĖą┐ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą│ąŠ ąĖąĘą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠą▒čŖąĄą║č鹊ą▓ - ą║ąŠą│ą┤ą░ čā ą┤ą░ąĮąĮčŗčģ ąĄčüčéčī č鹥ą│, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖą╣ čéąĖą┐ ąĖ ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ą┐čĆąŠčåąĄą┤čāčĆčŗ/ąŠą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ čéą░ą║ąŠą▓čŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ. ąŻą┐čĆą░ą▓ą╗čÅčÄčēąĄą╝čā čÅą┤čĆčā ąŠčüčéą░čæčéčüčÅ ą╗ąĖčłčī ąĮą░ą┐čĆą░ą▓ąĖčéčī čéą░ą║ąŠą▓čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčēąĄąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ - ą║ą░ą║ čćą░čüčéąĮčŗą╣ čüą╗čāčćą░ą╣ - ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ&ą╗ąŠą│ąĖč湥čüą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ ąĮą░ą┐čĆą░ą▓ąĖčéčī ą▓ ą░.ą╗.čā. ąÜą░ą║ ą│ąŠą▓ąŠčĆąĖčéčüčÅ "ąĖą┤ąĄčÅ ą▓ąĖčéą░ąĄčé ą▓ ą▓ąŠąĘą┤čāčģąĄ" - ąŠčüčéą░ą╗ąŠčüčī ą┐ąŠą┐čĆąŠą▒ąŠą▓ą░čéčī .. 
_________________
< ą▓ąĖčĆčéčāą░ą╗čīąĮą░čÅ "ą║ąĮąŠą┐ąŠčćą║ą░" >--( WWW ) <- ąŻą▒ąĄą┤ąĖč鹥ą╗čīąĮą░čÅ ą┐čĆąŠčüčīą▒ą░ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╝čüčÅ čüčéą░čĆčŗą╝ąĖ ą║ąŠą╝ą┐čīčÄč鹥čĆą░ą╝ąĖ čéąĖą┐ą░ ąĀąÜ86 - ąĮąĄ ą┐ąĖčłąĖč鹥 ą▓ č鹥ą╝ąĄ ą▓ ą▒ą░čĆą░čģąŠą╗ą║ąĄ, ą┐ąĖčłąĖč鹥 ąÆą░čłąĖ ą▓ąŠą┐čĆąŠčüčŗ ą▓ ( ą╗čü ) ą┐ąŠąČą░ą╗čāą╣čüčéą░
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
B@R5uk
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 21:43:03 |
|
| ąĪąŠą▒čāčéčŗą╗čīąĮąĖą║ ąÜąŠčéą░ |
 |
ąÜą░čĆą╝ą░: 28
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 756
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąĪą▒ ąĮąŠčÅ 13, 2010 12:53:25
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 2893
ą×čéą║čāą┤ą░: ą┐čĆąĖčģąŠą┤ąĖčé ą▓ąĄčüąĮą░?
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
ąĪčĆą░ąĘčā ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą▓ąŠą┐čĆąŠčü "ąŚą░č湥ą╝?" ą×ą▒čŗčćąĮąŠ ąŠčéą▓ąĄč鹊ą╝ čÅą▓ą╗čÅąĄčéčüčÅ ą▒ą░ą╗ą░ąĮčü ą╝ąĄąČą┤čā "ąæčŗčüčéčĆąŠ", "ąŻąĮąĖą▓ąĄčĆčüą░ą╗čīąĮąŠ", "ąöčæčłąĄą▓ąŠ". ąśą╝ąĄąĮąĮąŠ ą▒ą░ą╗ą░ąĮčü, čéą░ą║ ą║ą░ą║ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čü čĆą░ąĘą╗ąĖčćąĮčŗą╝ ąĮą░ąĘąĮą░č湥ąĮąĖąĄą╝ ąĮą░ čĆą░ąĘąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ čü čĆą░ąĘąĮąŠą╣ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčīčÄ. ąØąĄ ą│ąŠą▓ąŠčĆčÅ čāąČąĄ ąŠ č鹊ą╝, čćč鹊 ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čā ą╝ąŠąČąĮąŠ ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą╝ąŠąČąĮąŠ ąĮą░ą┐ąĖčüą░čéčī čüąŠą▓ąĄčĆčłąĄąĮąĮąŠ čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ ą▓ ą┐ą╗ą░ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠčüčéąĖ (ą┐ą░ą╝čÅčéčī ą┐čĆąŠą│čĆą░ą╝ą╝, ą┐ą░ą╝čÅčéčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ, ą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠčüčéčī ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ) čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ą¤čĆąĖ ąĮą░ą╗ąĖčćąĖąĖ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ ą┐čĆąŠą│čĆą░ą╝ą╝ čŹčéąĖ čüą┐ąŠčüąŠą▒čŗ ą┐ąŠčĆąŠą╣ čüčéą░ąĮąŠą▓čÅčéčüčÅ čüąŠą▓ąĄčĆčłąĄąĮąĮąŠ ąĮąĄąŠč湥ą▓ąĖą┤ąĮčŗą╝ąĖ. ą» ą┤čāą╝ą░čÄ, čćč鹊 ą║ąŠąĮčåąĄą┐čéčāą░ą╗čīąĮą░čÅ ą║čĆą░čüąŠčéą░ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą║ąŠą╝ą░ąĮą┤, ą║ąŠč鹊čĆčāčÄ ą┐čĆąĄčüą╗ąĄą┤čāąĄčé ą░ą▓č鹊čĆ č鹊ą┐ąĖą║ą░, ŌĆö čŹč鹊 čüą░ą╝ąŠąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ, ąŠ čćčæą╝ ąĮą░ą┤ąŠ ąĘą░ą┤čāą╝čŗą▓ą░čéčīčüčÅ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ ą╝ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆą░. ąØąĄčćč鹊 ą▒ą╗ąĖąĘą║ąŠąĄ ą║ čŹč鹊ą╝čā ą┐ąŠąĮčÅčéąĖčÄ čĆąŠą┤ąĖčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ąĄčüą╗ąĖ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ ą▒čāą┤ąĄčé ą┐čĆąĄčüą╗ąĄą┤ąŠą▓ą░čéčī čåąĄą╗čī čüąŠąĘą┤ą░čéčī ą╝ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆ (ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ) čü ąĮą░ąĖą▒ąŠą╗ąĄąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮčŗą╝ čÅą┤čĆąŠą╝ ąĖ/ąĖą╗ąĖ čü ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčīčÄ ą┤ą░ą╗čīąĮąĄą╣čłąĄą│ąŠ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ą▒ąŠčĆą░ ąĖąĮčüčéčĆčāą║čåąĖą╣. petrenko ą┐ąĖčüą░ą╗(ą░): ąśą╝ąĄąĮąĮąŠ ą┤ą╗čÅ čüą░ą╝ąŠąŠą▒čāč湥ąĮąĖčÅ - ąĮą░ąĖą╗čāčćčłąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ! ą» ą┤čāą╝ą░čÄ, ą┤ą╗čÅ čüą░ą╝ąŠąŠą▒čāč湥ąĮąĖčÅ ą▓ ą┐ąĄčĆą▓čāčÄ ąŠč湥čĆąĄą┤čī ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą╗ąĄąĘąĮąŠ čĆą░ąĘąŠą▒čĆą░čéčīčüčÅ ą▓ čāąČąĄ ąĖą╝ąĄčÄčēąĖčģčüčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ, ą┐ąŠą┐čŗčéą░čéčīčüčÅ ą┐ąŠąĮčÅčéčī ąĖą╗ąĖ ą┐ąŠą┤ąĮčÅčéčī ąĖčüč鹊čĆąĖčÄ ą▓ąŠą┐čĆąŠčüą░, ą┐ąŠč湥ą╝čā ą▓ č鹊ą╝ ąĖą╗ąĖ ąĖąĮąŠą╝ ą╝ąŠą╝ąĄąĮč鹥 ą▒čŗą╗ąŠ ą▓čŗą▒čĆą░ąĮąŠ ąĖą╝ąĄąĮąĮąŠ čéą░ą║ąŠąĄ čĆąĄčłąĄąĮąĖąĄ, ą░ ąĮąĄ ą║ą░ą║ąŠąĄ-č鹊 ą┤čĆčāą│ąŠąĄ, ąĖ ą║ ą║ą░ą║ąĖą╝ ąĮąĄčāą┤ą░čćąĮčŗą╝ ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖčÅą╝ čŹč鹊 čĆąĄčłąĄąĮąĖąĄ ą┐čĆąĖą▓ąĄą╗ąŠ ą▓ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╝. ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ after 9 minutes 5 seconds:Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗPaguo-86PK ą┐ąĖčüą░ą╗(ą░): ąÉ ąĮą░čüčćčæčé ą░čĆčģąĖč鹥ą║čéčāčĆčŗ... ąĢčüą╗ąĖ čÅ ąĮąĄ ąŠč湥ąĮčī ąŠčłąĖą▒ą░čÄčüčī, ąĖą╝ąĄąĮąĮąŠ ą░čĆčģąĖč鹥ą║čéčāčĆąŠą╣ ąÆą£80 ąŠą┐ąĖčüčŗą▓ą░ą╗ąŠčüčī, čćč鹊 ą▓čüąĄ ą░čĆąĖčäą╝ąĄčéąĖą║ąŠ-ą╗ąŠą│ąĖč湥čüą║ąĖąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčéčüčÅ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝; čćč鹊 ąĖą╝ąĄąĄčéčüčÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą┤ąŠ 256 ąŻąÆąÆ; čćč鹊 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą░ą┤čĆąĄčüčāąĄą╝ąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ - 64ą║ą▒; čćč鹊 ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą┐čĆčÅą╝ą░čÅ ąĖ ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ąØčā, ąĮą░ą┐čĆąĖą╝ąĄčĆ, čĆą░ąĘąĮąĖčåą░ ą╝ąĄąČą┤čā Z80 ąĖ čüąĄą╝ąĄą╣čüčéą▓ąŠą╝ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą▓ AVR, čćč鹊 ą╝ąĮąĄ ą┤ąŠą▓ąŠą┤ąĖą╗ąŠčüčī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░čéčī, ą▒čĆąŠčüą░ąĄčéčüčÅ ą▓ ą│ą╗ą░ąĘą░ čüčĆą░ąĘčā: ą▓ ą┐ąĄčĆą▓ąŠą╝ čłąĖąĮą░ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ ąĖ ą║ąŠą╝ą░ąĮą┤ ąŠą┤ąĮą░, ą▓ąŠ ą▓č鹊čĆąŠą╝ ŌĆö ąĖčģ ą┤ą▓ąĄ, ą┐ąŠ ąŠą┤ąĮąŠą╣ ąĮą░ ą║ą░ąČą┤čāčÄ. ąÆ Z80 ąĖ AVR ą▓ąĮąĄčłąĮąĖąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ą░ą┤čĆąĄčüčāčÄčéčüčÅ č湥čĆąĄąĘ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ŌĆö ą┐ąŠčĆčéčŗ ą▓ą▓ąŠą┤ą░-ą▓čŗą▓ąŠą┤ą░, ą░ ą▓ STM32 ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░čģ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┤ą╗čÅ čāčüčéčĆąŠą╣čüčéą▓, ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ ąĖ ą¤ąŚąŻ ąĄą┤ąĖąĮąŠ. ą» ąĄčēčæ ą┤ą░ą╗ąĄą║ąŠ ą┤ąĖą╗ąĄčéą░ąĮčé ą▓ ą┐ąŠą┤ąŠą▒ąĮčŗčģ ą▓ąŠą┐čĆąŠčüą░čģ, čģąŠčéčī ąĖ ąĘą░ąĮąĖą╝ą░čÄčüčī ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ, ąĮąŠ ą╝ąĮąĄ ą║ą░ąČąĄčéčüčÅ, čćč鹊 ąĄčüčéčī ąĖ ą┤čĆčāą│ąĖąĄ ą┐ąŠčģąŠą┤čŗ ą║ ą▓ąŠą┐čĆąŠčüčā.
ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ čĆą░ąĘ čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░ą╗ąŠčüčī B@R5uk ą¦čé čÅąĮą▓ 12, 2017 21:55:05, ą▓čüąĄą│ąŠ čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░ą╗ąŠčüčī 1 čĆą░ąĘ.
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
petrenko
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: "čĆą░ąĘą╝čŗčłą╗ąĄąĮąĖčÅ ąĮą░ čāąĮąĖčéą░ąĘąĄ" ąŠą▒ čāą╗čāčćčłą░ą╣ąĘąĖąĮą│ąĄ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 21:49:18 |
|
ąÜą░čĆą╝ą░: 45
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: -17
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčé č乥ą▓ 21, 2012 13:51:55
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 5114
ą×čéą║čāą┤ą░: ąØą░čćąĖąĮą░čÄčēąĖą╣
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
Paguo-86PK ą┐ąĖčüą░ą╗(ą░): .. ą┤ąŠčüčéą░č鹊čćąĮąŠ čĆąĄąĘą║čāčÄ* ą║čĆąĖčéąĖą║čā..
..
.. čĆą░ąĘą▓ąĄ čÅ ąĮąĄ ą┤ąŠčüčéą░č鹊čćąĮąŠ čāą┤ąĄą╗ąĖą╗ ą▓ąĮąĖą╝ą░ąĮąĖčÅ čŹčéąĖą╝ ą┤ąĄčéą░ą╗čÅą╝** ? .. *_ąØčā čŹč鹊 ą▓ąŠą▓čüąĄ ąĮąĄ čĆąĄąĘą║ą░čÅ, ą░ ą▓ąĄčüčīą╝ą░ ą┤ą░ąČąĄ ą╝čÅą│ą║ą░čÅ ą║čĆąĖčéąĖą║ą░  **_ **_ąÆąŠčé ą┤ąĄčéą░ą╗čÅą╝ č鹊 ą║ą░ą║ čĆą░ąĘ ą▒ąŠą╗ąĄąĄ, č湥ą╝ ą┐čĆąĄą┤ąŠčüčéą░č鹊čćąĮąŠ, ą▓ąĮąĖą╝ą░ąĮąĖčÅ. ą¢ą░ą╗čī, čćč鹊 ąŠčüąĮąŠą▓ąĮąŠą╣ čüą╝čŗčüą╗ ą║čĆąĖčéąĖą║ąĖ ąÆčŗ ąĄčēčæ ąĮąĄ ą┐ąŠąĮčÅą╗ąĖ. ąØąĄ ąŠčéčćą░ąĖą▓ą░ą╣č鹥čüčī - ą┐ąĄčĆąĄčćąĖčéą░ą╣č鹥 čüąŠąŠą▒čēąĄąĮąĖąĄ, ąĮčā .. ąĖ .. ąĮą░čĆąĖčüčāą╣č鹥 , čćč鹊 ą╗ąĖ .. ą▒ą╗ąŠą║-čüčģąĄą╝čā .. ą┐ąŠąČą░ą╗čāą╣čüčéą░ .. , ą░ č鹊 ąŠą▒čüčāąČą┤ą░čéčī ąĮčā čüąŠą▓čüąĄą╝ ąĮąĄč湥ą│ąŠ ą┐ąŠ čüčāčēąĄčüčéą▓čā ąĮą░ąĘą▓ą░ąĮąĖčÅ č鹥ą╝čŗ. ą”ąĖčéą░čéą░: ą┤čāą╝ą░čÄ, čćč鹊 ą║ąŠąĮčåąĄą┐čéčāą░ą╗čīąĮą░čÅ ą║čĆą░čüąŠčéą░ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą║ąŠą╝ą░ąĮą┤, .. - čŹč鹊 čüą░ą╝ąŠąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ, ąŠ čćčæą╝ ąĮą░ą┤ąŠ ąĘą░ą┤čāą╝čŗą▓ą░čéčīčüčÅ ąÆąŠąĖčüčéąĖąĮčā čéą░ą║ !
_________________
< ą▓ąĖčĆčéčāą░ą╗čīąĮą░čÅ "ą║ąĮąŠą┐ąŠčćą║ą░" >--( WWW ) <- ąŻą▒ąĄą┤ąĖč鹥ą╗čīąĮą░čÅ ą┐čĆąŠčüčīą▒ą░ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╝čüčÅ čüčéą░čĆčŗą╝ąĖ ą║ąŠą╝ą┐čīčÄč鹥čĆą░ą╝ąĖ čéąĖą┐ą░ ąĀąÜ86 - ąĮąĄ ą┐ąĖčłąĖč鹥 ą▓ č鹥ą╝ąĄ ą▓ ą▒ą░čĆą░čģąŠą╗ą║ąĄ, ą┐ąĖčłąĖč鹥 ąÆą░čłąĖ ą▓ąŠą┐čĆąŠčüčŗ ą▓ ( ą╗čü ) ą┐ąŠąČą░ą╗čāą╣čüčéą░
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
ąĀąĄą║ą╗ą░ą╝ą░
|
|
|
|
|
|
|
|
|
|
B@R5uk
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 21:49:52 |
|
| ąĪąŠą▒čāčéčŗą╗čīąĮąĖą║ ąÜąŠčéą░ |
|
ąÜą░čĆą╝ą░: 28
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 756
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąĪą▒ ąĮąŠčÅ 13, 2010 12:53:25
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 2893
ą×čéą║čāą┤ą░: ą┐čĆąĖčģąŠą┤ąĖčé ą▓ąĄčüąĮą░?
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
Paguo-86PK ą┐ąĖčüą░ą╗(ą░): ąóą░ą║, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą╝ąĄąĮčÅ ą▓ąŠąĘą╝čāčéąĖą╗ąŠ, čćč鹊 ą▓ i8086 ą║ąŠą┤čā 00 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąŠą┐ąĄčĆą░čåąĖčÅ ADD, čćč鹊 čüą▒ąĖą▓ą░ąĄčé čü č鹊ą╗ą║čā, ąĄčüą╗ąĖ ą┐ą░ą╝čÅčéčī ąŠą▒ąĮčāą╗ąĄąĮą░. ąÆ IBM-ą┐ąŠą┤ąŠą▒ąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ ąŠą▒ąĮčāą╗ąĄąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ ąĘą░ąĮąĖą╝ą░ąĄčéčüčÅ ą▒ąĖąŠčü ąĮą░ čŹčéą░ą┐ąĄ ą┐čĆąŠą▓ąĄčĆą║ąĖ čĆą░ą▒ąŠč鹊čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąĖ ą▓ą║ą╗čÄč湥ąĮąĖąĖ ą┐ą░ą╝čÅčéčī ąĘą░ą▒ąĖčéą░ ą╝čāčüąŠčĆąŠą╝. ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ čüą┐ąŠčüąŠą▒ "čüą▒čĆąŠčüąĖčéčī" ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ ą×ąŚąŻ ŌĆö ąĘą░ą┐ąĖčüą░čéčī čéčāą┤ą░ ą║ąŠąĮą║čĆąĄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąŁčéąĖą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ą║ąŠą╝ą░ąĮą┤ą░ NOP ąĖą╗ąĖ ą╗čÄą▒ą░čÅ ą┤čĆčāą│ą░čÅ ą┐ąŠ ą▓ą░čłąĄą╝čā ąČąĄą╗ą░ąĮąĖčÄ. ąÆ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░čģ, ą┐ą░ą╝čÅčéčī ąŠą│čĆą░ąĮąĖč湥ąĮą░ ąĖ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĮą░ čéčĆąĖą│ą│ąĄčĆą░čģ, ą┐ąŠčŹč鹊ą╝čā ąĖą╝ąĄąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▒čŗčéčī čüą▒čĆąŠčłąĄąĮąŠą╣ ą▓ ąĮąŠą╗čī ą┐ąŠ čüąĖą│ąĮą░ą╗čā ą╗ąĖąĮąĖąĖ čüą▒čĆąŠčüą░. ą×ąĮą░ ąĮąĄ čéčĆąĄą▒čāąĄčé ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĖ ą╝ąŠąČąĄčé čüąŠčģčĆą░ąĮčÅčéčī čüą▓ąŠąĖ ąĘąĮą░č湥ąĮąĖčÅ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ čÅą┤čĆąŠ ą┐čĆąŠčüčéą░ąĖą▓ą░ąĄčé (ą┐ąŠą║ą░ ą┐ąĖčéą░ąĮąĖąĄ ą▓ą║ą╗čÄč湥ąĮąŠ, čĆą░ąĘčāą╝ąĄąĄčéčüčÅ).
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
DX168B
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: "čĆą░ąĘą╝čŗčłą╗ąĄąĮąĖčÅ ąĮą░ čāąĮąĖčéą░ąĘąĄ" ąŠą▒ čāą╗čāčćčłą░ą╣ąĘąĖąĮą│ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 21:57:11 |
|
| ąöčĆčāą│ ąÜąŠčéą░ |
|
ąÜą░čĆą╝ą░: 25
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 99
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčü čÅąĮą▓ 24, 2010 19:19:52
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 4470
ą×čéą║čāą┤ą░: ąōą╗ą░ą▓ąĮčŗą╣ ąŻą╗ąĄą╣ ąĀąŠčüčüąĖąĖ (Moscow)
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
petrenko ą┐ąĖčüą░ą╗(ą░): ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ ąĮą░ nedopc.org/forum čāąČąĄ ąŠą▒čüčāąČą┤ą░ą╗čüčÅ ą┐čĆąĖąĮčåąĖą┐ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą│ąŠ ąĖąĘą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠą▒čŖąĄą║č鹊ą▓ - ą║ąŠą│ą┤ą░ čā ą┤ą░ąĮąĮčŗčģ ąĄčüčéčī č鹥ą│, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖą╣ čéąĖą┐ ąĖ ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ą┐čĆąŠčåąĄą┤čāčĆčŗ/ąŠą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ čéą░ą║ąŠą▓čŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ.
ąŻą┐čĆą░ą▓ą╗čÅčÄčēąĄą╝čā čÅą┤čĆčā ąŠčüčéą░čæčéčüčÅ ą╗ąĖčłčī ąĮą░ą┐čĆą░ą▓ąĖčéčī čéą░ą║ąŠą▓čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčēąĄąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ - ą║ą░ą║ čćą░čüčéąĮčŗą╣ čüą╗čāčćą░ą╣ - ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ&ą╗ąŠą│ąĖč湥čüą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ ąĮą░ą┐čĆą░ą▓ąĖčéčī ą▓ ą░.ą╗.čā. ąØčā, ą▓ ą┐čĆąĖąĮčåąĖą┐ąĄ, čŹč鹊 ą╝ąŠąČąĮąŠ ąĮą░ąĘą▓ą░čéčī ą┤ą░ą╗čīąĮąĄą╣čłąĖą╝ čĆą░ąĘą▓ąĖčéąĖąĄą╝ ą╝ąŠąĖčģ ą╝čŗčüą╗ąĄą╣. ąóąĖą┐ą░, čüąŠą▒čĆą░čéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ ą▒ą╗ąŠą║ąĖ ąĖ ą┐ąŠą╝ąĄčéąĖčéčī ą▒ą╗ąŠą║ č鹥ą│ąŠą╝. ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą▒ą╗ąŠą║ ąĘą░ą│čĆčāąĘąĖčéčüčÅ ą▓ ą║ąŠąĮą▓ąĄą╣ąĄčĆ, ą┐ąĄčĆąĄą┤ą░čéčī ąĄą│ąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╝čā čāąĘą╗čā ąĮą░ ąĖčüą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąóąĄą│ ą╝ąŠąČąĄčé ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčéčī čüąŠą▒ąŠą╣ ąĮąŠą╝ąĄčĆ čāąĘą╗ą░, ą║ąŠč鹊čĆąŠą╝čā čŹč鹊čé ą▒ą╗ąŠą║ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ. ąÉ ąĄčüą╗ąĖ čŹč鹊čé ą▒ą╗ąŠą║ čüąŠčüč鹊ąĖčé ąĖąĘ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąŠą┐ąĄčĆą░čåąĖą╣, č鹊 ąĖčģ ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ. ąÜąŠčĆąŠč湥, čéčāčé ą╝ąŠąČąĮąŠ čĆą░ąĘą▓ąĖą▓ą░čéčī, čĆą░ąĘą▓ąĖą▓ą░čéčī ąĖ ą┐ąŠą╗čāčćąĖčéčī "ąŁą╗čīą▒čĆčāčü". 
_________________
I am DX168B and this is my favourite forum on internet!
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
Paguo-86PK
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 21:59:50 |
|
| ą×ą┐čŗčéąĮčŗą╣ ą║ąŠčé |
|
ąÜą░čĆą╝ą░: 15
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 16
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¦čé ą░ą▓ą│ 19, 2010 23:49:19
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 803
ą×čéą║čāą┤ą░: ąóą░čłą║ąĄąĮčé
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
ąśąĮčéčāąĖčéąĖą▓ąĮąŠ čÅčüąĮą░čÅ čĆą░čüčüčéą░ąĮąŠą▓ą║ą░ ą║ąŠą╝ą░ąĮą┤ąØą░ čāčĆąŠą▓ąĮąĄ ą╝ą░čłąĖąĮąĮąŠą│ąŠ ą║ąŠą┤ą░ čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ čāčüčéčĆąŠąĄąĮą░ ą│ąŠčĆą░ąĘą┤ąŠ ą┐čĆąŠčēąĄ, č湥ą╝ ą╝ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčīčüčÅ ąĮą░ ą┐ąĄčĆą▓čŗą╣ ą▓ąĘą│ą╗čÅą┤. ąóą░ą║, ąĖąĮčüčéčĆčāą║čåąĖąĖ čü čüąĖą╝ą╝ąĄčéčĆąĖčćąĮčŗą╝ąĖ č鹥čéčĆą░ą┤ą░ą╝ąĖ (ąĮąĖą▒ą▒ą╗ą░ą╝ąĖ) čü ą║ąŠą┤ą░ą╝ąĖ 11/22/33/44/55/66/77 čÅą▓ą╗čÅčÄčéčüčÅ ą┐čĆąĄčäąĖą║čüą░ą╝ąĖ ą┐ąŠą┤ą╝ąĄąĮčŗ ą┤ąĄą╣čüčéą▓čāčÄčēąĄą│ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ąĖą╗ąĖ čāą║ą░ąĘą░č鹥ą╗čÅ. ą×ą┐ąĄčĆą░čåąĖąĖ ąÉąøąŻ čéą░ą║ąČąĄ ąĘą░ąĮąĖą╝ą░čÄčé ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ą┐ąŠąĮčÅčéąĮčŗąĄ ą┐ąŠąĘąĖčåąĖąĖ: A(Add)/B(suB)/C(Conjunction-AND)/D(Disjunction-OR)/E(Exclusive OR). ą¦ą░čüčéčŗąĄ ą║ąŠą╝ą░ąĮą┤čŗ ąĖą╝ąĄčÄčé ą║čĆą░čéą║ąĖą╣ ą║ąŠą┤ą×ą│ą╗čÅą┤čŗą▓ą░čÅčüčī ąĮą░ x86 ąĮąĄ čÅ ą┐ąĄčĆą▓čŗą╣ ąĮąĄ ą╝ąŠą│čā čüą┤ąĄčƹȹ░čéčī ą║čĆąĖčéąĖą║čā: ąóą░ą▒ą╗ąĖčåą░ ą║ąŠą╝ą░ąĮą┤ ą┤ą░ą▓ąĮąŠ čüčéą░ą╗ą░ ą╝čāčüąŠčĆą║ąŠą╣. ąÆčüąĄ MMX/SSE ą║ąŠą╝ą░ąĮą┤čŗ čüą▓ą░ą╗ąĖą╗ąĖčüčī ą┐ąŠą┤ ą┐čĆąĄčäąĖą║čü 0F; ąĪąĄą│ą╝ąĄąĮčéąĮčŗąĄ ą┐čĆąĄčäąĖą║čüčŗ, ą▒ą╗ą░ą│ąŠą┐ąŠą╗čāčćąĮąŠ ąŠčéąČąĖą▓čłąĖąĄ čüą▓ąŠą╣ ą▓ąĄą║, ąĘčĆčÅ ą┐ąŠąČąĖčĆą░čÄčé ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą╝ą░čłąĖąĮąĮąŠą│ąŠ ą║ąŠą┤ą░. ą£ąĮąŠą│ąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąŠąĮąĮčŗąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą║ą░ą║ ą▒čŗą╗ąĖ ą┐ąŠą┤ čüčéą░čéčāčüąŠą╝ "ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ", čéą░ą║ ąĖ ąŠčüčéą░ą╗ąĖčüčī. ąóąĄą╝ čüą░ą╝čŗą╝, ą▓ čüą▓ąŠąĄą╣ ą║ąŠąĮčåąĄą┐čåąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ čÅ ąĖ čŹč鹊 čāčćąĖčéčŗą▓ą░ą╗. ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠ ąĮąĄčé ąĮąĖą║ą░ą║ąĖčģ ą▓čüčÅą║ąĖčģ ą┐čĆąĄčäąĖą║čüąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖčłą╗ąŠčüčī ą▒čŗ ą┐ąŠč鹊ą╝ ą▓čŗą║ąĖą┤čŗą▓ą░čéčī. ąØąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ąŠčĆčéą░ą╝, ąĘą░ą┐čĆąĄčéą░/čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, ą┤ąŠčüčéčāą┐ą░ ą║ čüą╗čāąČąĄą▒ąĮčŗą╝ čĆąĄą│ąĖčüčéčĆą░ą╝. ąÆ čāą┐čĆą░ą▓ą╗čÅčÄčēąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ, čćč鹊ą▒čŗ ąĘą░ą┐ąĖčüą░čéčī ą▒ą░ą╣čé ą▓ čüąĖčüč鹥ą╝ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ, ąĮčāąČąĮąŠ ąĮą░ą│ąŠčĆąŠą┤ąĖčéčī ą┤čĆčāą│ ąĮą░ ą┤čĆčāą│ą░ čéčĆąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąŠą▒čēąĄą╣ ą┤ą╗ąĖąĮąŠčÄ ą▓ 6 ą▒ą░ą╣čé. ąŁč鹊 - ąĮąĄ ąŠčüąŠą▒ąĄąĮąĮą░čÅ ą┐čĆąĖą▓ąĄą╗ąĄą│ąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą║ąŠą╝ą░ąĮą┤ą░. ąÉ ąĮąĄąŠą▒čŗčćąĮąŠąĄ čüąŠč湥čéą░ąĮąĖąĄ ąĖąĘ čéčĆčæčģ čüą░ą╝čŗčģ ąŠą▒čŗčćąĮčŗčģ ą║ąŠą╝ą░ąĮą┤. ąöąĄčłąĖčäčĆą░č鹊čĆ ą║ąŠą╝ą░ąĮą┤ąØą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą┤ąĮąŠą╣ ą║ąŠą╝ą░ąĮą┤čŗ ą╝ąŠąČąĄčé ąĘą░čéčĆą░čćąĖą▓ą░čéčīčüčÅ ąŠčé č湥čéčŗčĆčæčģ ą┤ąŠ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┤ąĄčüčÅčéą║ąŠą▓ čéą░ą║č鹊ą▓. ąĢčüą╗ąĖ ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ "čāą┐ą░ą║ąŠą▓čŗą▓ą░čÄčéčüčÅ" ą▓ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ąŠčéą▓ąĄą┤čæąĮąĮčŗą╣ ą▒čāč乥čĆ čüčéą░čéąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ, ąĖąĘ ą║ąŠč鹊čĆąŠą╣ ąĖčģ ą▓čŗą▒ąŠčĆą║ą░ ą╝ąŠąČąĄčé ąĘą░ąĮąĖą╝ą░čéčī čāąČąĄ ąŠčé 1 čéą░ą║čéą░ ąĮą░ ą║ąŠą╝ą░ąĮą┤čā. ąÆčüąĄą│ąŠ ą╝ąŠąČąĮąŠ ąĖą╝ąĄčéčī ąĘą░ą│ąŠč鹊ą▓ą║čā ą┤ąŠ 10 čéą░ą║ąĖčģ ą╝ą░ą║čĆąŠčüąŠą▓, ą║ą░ąČą┤čŗą╣ ą┤ą╗ąĖąĮąŠčÄ ą┤ąŠ 7 ą║ąŠą╝ą░ąĮą┤. ą×ą▒čĆą░ą▒ąŠčéą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ąōąŠą▓ąŠčĆčÅ ą┐čĆąŠčüčéčŗą╝ čÅąĘčŗą║ąŠą╝, ą▓ąĮčāčéčĆąĖ ą▓čüąĄą│ąŠ čüąĖčüč鹥ą╝ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▓čŗčüčłąĄą│ąŠ čāčĆąŠą▓ąĮčÅ ą┐čĆąĖą▓ąĄą╗ąĄą│ąĖą╣ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĘą░ą┐čĆąĄčēąĄąĮčŗ. ą¤čĆąĖ ąĖčüą┐ąŠą╗ąĮąĄąĮąĖąĖ ą║ąŠą┤ą░ ą┐čĆąĖą║ą╗ą░ą┤ąĮčŗčģ ąĘą░ą┤ą░čć ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą▓čüąĄą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮčŗ. ą¦č鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī ąĮą░ą╗ąĖčćąĖąĄ ą▓ąĮąĄčłąĮąĄą│ąŠ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, čüąĖčüč鹥ą╝ąĮąŠą╝čā ą║ąŠą┤čā ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┐ąĄčĆąĄą┤ą░čéčī čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą╗čÄą▒ąŠą╝čā ą║ąŠą┤čā ą┐čĆąĖą║ą╗ą░ą┤ąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ą░ čüąĖčüč鹥ą╝ąĮčŗą╣ ą║ąŠą┤ ą┐ąŠą╗čāčćąĖčé ąĖąĮą┤ąĄą║čü čüąĖčéčāą░čåąĖąĖ ąŠčé ą┐ąĄčĆąĖč乥čĆąĖąĖ. ą¤ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖąÆ čüąŠčüčéą░ą▓ čüą╗čāąČąĄą▒ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓čģąŠą┤ąĖčé čüčćčæčéčćąĖą║ čéą░ą║č鹊ą▓ čü ąŠą▒čĆą░čéąĮčŗą╝ ąŠčéčüčćčæč鹊ą╝. ąÆ ą┐čĆąĖą▓ąĄą╗ąĄą│ąĖčĆąŠą▓ą░ąĮąĮąŠą╝ čĆąĄąČąĖą╝ąĄ čüąĖčüč鹥ą╝ąĮąŠą│ąŠ ą║ąŠą┤ą░ ąĄą│ąŠ čüčćčæčé ąĘą░ą╝ąŠčĆąŠąČąĄąĮ ąĖ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄą┤ą░č湥ą╣ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║ąŠąĮą║čĆąĄčéąĮąŠą╝čā ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ čÅą┤čĆąŠ ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĄą┤čāčüčéą░ąĮąŠą▓ąĖčéčī čŹč鹊čé čüčćčæčéčćąĖą║ čüąŠą│ą╗ą░čüąĮąŠ ą┐čĆąĖąŠčĆąĖč鹥čéčā ą┤ą░ąĮąĮąŠą╣ ąĘą░ą┤ą░čćąĖ. ąÆąĮčāčéčĆąĖ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝ąŠą╣ ą┐čĆąĖą║ą╗ą░ą┤ąĮąŠą╣ ąĘą░ą┤ą░č湥 čüčćčæčéčćąĖą║ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ ą┤ąĄą║čĆąĄą╝ąĄąĮčé ą┤ąŠ ąŠą▒ąĮčāą╗ąĄąĮąĖčÅ. ąĢą│ąŠ ąŠą▒ąĮčāą╗ąĄąĮąĖąĄ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ č鹥ą║čāčēąĄą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ čÅą┤čĆčā čüąĖčüč鹥ą╝čŗ. ąÜą░ą║ čāą║ą░ąĘą░ąĮąŠ ą▓čŗčłąĄ, ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĖ ą▓ čüą╗čāčćą░čÅčģ čüą▒ąŠčÅ čüčéčĆą░ąĮąĖčå ą┐ą░ą╝čÅčéąĖ, ą▓čüčéčĆąĄčćąĖ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čüą▒ąŠčÅ čüč鹥ą║ą░ ąĖ čé.ą┤. ąĪą▒ąŠą╣ čüč鹥ą║ą░ (ą▓ ą┐čĆąŠčĆą░ą▒ąŠčéą║ąĄ) ąŻą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ ą▓čüąĄą│ą┤ą░ ąŠą▒čÅąĘą░ąĮ ą▒čŗčéčī ą▓čŗčĆą░ą▓ąĮąĄąĮąĮčŗą╝ ą┐ąŠ ą╝ąŠą┤čāą╗čÄ 2. ąÜąŠą╝ą░ąĮą┤čŗ ą▓čŗąĘąŠą▓ą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (CALL) ąĖ ą▓ąŠąĘą▓čĆą░čéą░ (RET) čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčé ą╝ą╗ą░ą┤čłąĖą╣ ą▒ąĖčé SP ą▓ 1 ąĖ ąĮą░čĆčāčłą░čÄčé č鹥ą╝ čüą░ą╝čŗą╝ čŹč鹊 ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĮąĄ ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī ąĖ PUSH/POP ą║ąŠą╝ą░ąĮą┤čŗ, ą┐čĆąĄčĆčŗą▓ą░čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čü čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ąĖąĮą┤ąĄą║čüąŠą╝ ąŠčłąĖą▒ą║ąĖ ą┤ą╗čÅ čÅą┤čĆą░. ąŁč鹊 ą┐ąŠą╝ąŠą│ą░ąĄčé ą▒ąŠčĆąŠčéčīčüčÅ čü "ą║čĆąĖą▓čŗą╝" ą║ąŠą┤ąŠą╝ ą▓ ą║čĆąĖčéąĖč湥čüą║ąĖčģ ą╝ąĄčüčéą░čģ. ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ ąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĄąĄ ąĘą░ąĮąĖą╝ą░čéčīčüčÅ čü ą▓ąŠą┐čĆąŠčüąŠą╝ ą░ą║ą║čāčĆą░čéąĮąŠčüčéąĖ čüą▓ąŠąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąóą░ą║, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąŠčüčéčāą┐ą░ ą║ ąĮąĄčüčāčēąĄčüčéą▓čāčÄčēąĄą╣ čüčéčĆą░ąĮąĖčåąĄ ą┐ą░ą╝čÅčéąĖ ąĮąĄ ą▓čŗąĘąŠą▓ąĄčé ąŠčłąĖą▒ą║čā ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮą░ ą┐ąĄčĆą▓ąŠą╝ čłą░ą│ąĄ. ą¤čĆąŠčüč鹊, ą╝ą╗ą░ą┤čłąĖą╣ ą▒ąĖčé čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ čüąŠą▒čŖčæčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ. ąØąŠčĆą╝ą░ą╗čīąĮčŗą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ ą┤ąŠą╗ąČąĄąĮ čĆąĄą│čāą╗čÅčĆąĮąŠ ą┐čĆąŠą▓ąĄčĆčÅčéčī čŹč鹊čé čüčéą░čéčāčü čüč鹥ą║ą░, ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠ GetLastError ą▓ Win-API ą┐ąŠčüą╗ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮąĄčüčéą░ą▒ąĖą╗čīąĮčŗčģ ą┐čĆąŠčåąĄą┤čāčĆ. ąĢčüą╗ąĖ ą║ąŠą┤ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┐čĆąŠčłčæą╗ ą╝ąĖą╝ąŠ čüąĖčéčāą░čåąĖąĖ, č鹊 čüą▒ąĖčéčŗą╣ ą▒ąĖčé čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ ąĮąĄ ą┤ą░čüčé ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ą║ąŠą╝ą░ąĮą┤ą░ą╝ CALL/RET/PUSH/POP ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤čæčé čÅą▓ąĮą░čÅ ąŠčłąĖą▒ą║ą░ čü ą▓ąŠąĘą▓čĆą░č鹊ą╝ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čÅą┤čĆčā. P.S.: ąĀą░ąĘąĮčŗąĄ┬Āčüčüčŗą╗ąŠčćą║ąĖ: BMOWą¤čĆąŠčåąĄčüčüąŠčĆ ąĖ ą¤ąÜ čüą▓ąŠąĖą╝ąĖ čĆčāą║ą░ą╝ąĖ: ą┐čĆąŠąĄą║čé BMOW 1Homebrew ComputerąŻč湥ą▒ąĮčŗąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ ( 00 - HLT)
_________________
ą» č鹥ą▒čÅ ą┐ąŠą╗čÄą▒ąĖą╗, čÅ č鹥ą▒čÅ ąĮą░čāčćčā! ┬®ąŻčŹčä
ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ čĆą░ąĘ čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░ą╗ąŠčüčī Paguo-86PK ą¦čé čÅąĮą▓ 12, 2017 22:26:08, ą▓čüąĄą│ąŠ čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░ą╗ąŠčüčī 1 čĆą░ąĘ.
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
B@R5uk
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 22:22:24 |
|
| ąĪąŠą▒čāčéčŗą╗čīąĮąĖą║ ąÜąŠčéą░ |
|
ąÜą░čĆą╝ą░: 28
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 756
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąĪą▒ ąĮąŠčÅ 13, 2010 12:53:25
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 2893
ą×čéą║čāą┤ą░: ą┐čĆąĖčģąŠą┤ąĖčé ą▓ąĄčüąĮą░?
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
Paguo-86PK ą┐ąĖčüą░ą╗(ą░): ą×ą┐ąĄčĆą░čåąĖąĖ ąÉąøąŻ čéą░ą║ąČąĄ ąĘą░ąĮąĖą╝ą░čÄčé ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ą┐ąŠąĮčÅčéąĮčŗąĄ ą┐ąŠąĘąĖčåąĖąĖ: A(Add)/B(suB)/C(Conjunction-AND)/D(Disjunction-OR)/E(Exclusive OR). ąĀą░čüčüčéą░ąĮąŠą▓ą║čā ą║ąŠą╝ą░ąĮą┤ ą╗ąŠą│ąĖčćąĮąĄąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī ąĮą░ čŹčéą░ą┐ąĄ čĆą░ąĘą▓ąŠą┤ą║ąĖ čÅą┤čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ čŹčéą░ čĆą░ąĘą▓ąŠą┤ą║ą░ ąĖ čüčģąĄą╝ąŠč鹥čģąĮąĖą║ą░ ą▒čŗą╗ąĖ ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüčéčŗ. ąĪąĮąĖąČą░ąĄčé čåąĄąĮčā ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą▒čāą┤ąĄčé ą▓čüčæ čĆą░ą▓ąĮąŠ, ą║ą░ą║ą░čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ čā ą║ą░ą║ąŠą╣ ą║ąŠą╝ą░ąĮą┤čŗ.
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
Paguo-86PK
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 22:41:01 |
|
| ą×ą┐čŗčéąĮčŗą╣ ą║ąŠčé |
|
ąÜą░čĆą╝ą░: 15
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 16
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¦čé ą░ą▓ą│ 19, 2010 23:49:19
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 803
ą×čéą║čāą┤ą░: ąóą░čłą║ąĄąĮčé
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
B@R5uk ą┐ąĖčüą░ą╗(ą░): Paguo-86PK ą┐ąĖčüą░ą╗(ą░): ą×ą┐ąĄčĆą░čåąĖąĖ ąÉąøąŻ čéą░ą║ąČąĄ ąĘą░ąĮąĖą╝ą░čÄčé ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ą┐ąŠąĮčÅčéąĮčŗąĄ ą┐ąŠąĘąĖčåąĖąĖ: A(Add)/B(suB)/C(Conjunction-AND)/D(Disjunction-OR)/E(Exclusive OR). ąĀą░čüčüčéą░ąĮąŠą▓ą║čā ą║ąŠą╝ą░ąĮą┤ ą╗ąŠą│ąĖčćąĮąĄąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī ąĮą░ čŹčéą░ą┐ąĄ čĆą░ąĘą▓ąŠą┤ą║ąĖ čÅą┤čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ čŹčéą░ čĆą░ąĘą▓ąŠą┤ą║ą░ ąĖ čüčģąĄą╝ąŠč鹥čģąĮąĖą║ą░ ą▒čŗą╗ąĖ ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüčéčŗ. ąĪąĮąĖąČą░ąĄčé čåąĄąĮčā ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą▒čāą┤ąĄčé ą▓čüčæ čĆą░ą▓ąĮąŠ, ą║ą░ą║ą░čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ čā ą║ą░ą║ąŠą╣ ą║ąŠą╝ą░ąĮą┤čŗ. ąÆąŠčé čéčāčé č鹊 čÅ ą║ą░č鹥ą│ąŠčĆąĖč湥čüą║ąĖ ąĮąĄ čüąŠą│ą╗ą░čüąĄąĮ. ą¤čĆąĖ čĆą░ąĘą▓ąŠą┤ą║ąĄ čÅą┤čĆą░ i8086 ą╝ąŠąČąĄčé čŹč鹊 ą▒čŗą╗ąŠ ąĖ ą░ą║čéčāą░ą╗čīąĮąŠ. ąØąŠ, čü ą┐čĆąĖčģąŠą┤ąŠą╝ i386, i486, Pentium ąĖ čé.ą┤. čĆą░čüčüčéą░ąĮąŠą▓ą║ą░ ą║ąŠą╝ą░ąĮą┤ čüčéą░ą╗ą░ ąĮąĄ čéą░ą║ ą░ą║čéčāą░ą╗čīąĮą░ ąĖ 00-ADD čüčéą░ą╗ąŠ ą▓čŗą│ą╗čÅą┤ąĖčéčī ą┐ąŠ-ąĖą┤ąĖąŠčéčüą║ąĖ  ą¤čŗčéą░čÅčüčī ą│ą╗čÅą┤ąĄčéčī čćčāč鹊čćą║čā ą▓ą┤ą░ą╗čī, čĆą░čüčüčéą░ąĮąŠą▓ą║čā ą║ąŠą╝ą░ąĮą┤ čÅ ą┤ąĄą╗ą░ą╗ ąĖčüčģąŠą┤čÅ ąĖąĘ čŹčüč鹥čéąĖč湥čüą║ąŠą│ąŠ ąĖ ąĖąĮčéčāąĖčéąĖą▓ąĮąŠą│ąŠ ą▓ąĖąĘčāą░ą╗čīąĮąŠą│ąŠ ąŠčģą▓ą░čéą░ čéą░ą▒ą╗ąĖčåčŗ ą▓ąĘą│ą╗čÅą┤ąŠą╝, ą░ ąĮąĄ ą┐čĆąĖą║ąĖą┤čŗą▓ą░čÅ ąĮą░ ą╝ąĖą╗ą╗ąĖą╝ąĄčéčĆąŠą▓ą║ąĄ čĆą░čüčüč鹊čÅąĮąĖčÅ ą┐čĆąŠą▓ąŠą┤ą║ąŠą▓. ąĪąŠą│ą╗ą░čüąĖč鹥čüčī, čćč鹊 ąĖ ąČčæčüčéą║ąĖą╣ čéą░ą▒ą╗ąĖčćąĮčŗą╣ čüąĖąĮčéą░ą║čüąĖčü ążą×ąĀąóąĀąÉąØą░, ąŠč湥ąĮčī ą░ą║čéčāą░ą╗čīąĮčŗą╣ ąĮą░ ąĘą░čĆąĄ ą»ąÆąŻ, ąŠč湥ąĮčī ą┐ąŠč鹊ą╝ ąĮąĄą┐čĆčÅą│ą░ą╗ ą▓čüąĄčģ ą▓ 80-90-čģ. ąÆ ą║ąŠąĮčåąĄ-ą║ąŠąĮčåąŠą▓, ą▓ ąĮąŠą▓čŗčģ čüčéą░ąĮą┤ą░čĆčéą░čģ ą▓ąĄčĆčüąĖą╣ čÅąĘčŗą║ą░ čüąĖąĮčéą░ą║čüąĖčü čüą┤ąĄą╗ą░ą╗ąĖ ą▒ąŠą╗ąĄąĄ čüą▓ąŠą▒ąŠą┤ąĮčŗą╝. ąóąĄą╝ čüą░ą╝čŗą╝, čÅ ą┐čĆąĖąĮčåąĖą┐ąĖą░ą╗čīąĮąŠ ąĮąĄ ąŠą┐ąĖčĆą░čÄčüčī ąĮą░ č鹥čģąĮąĖč湥čüą║ąĖąĄ ąĖąĘą┤ąĄčƹȹ║ąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čÅą┤čĆą░ ą┐čĆąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ čéą░ą▒ą╗ąĖčåčŗ ą║ąŠą╝ą░ąĮą┤. ąÜąĖčłą║ąĖ čÅą┤čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ą▓čŗą╗ą░ąĘąĖčéčī ą│čĆčŗąČąĄą╣ čüąĖčüč鹥ą╝čŗ ą║ąŠą╝ą░ąĮą┤. (ą║čüčéą░čéąĖ, NOP čā ą╝ąĄąĮčÅ čĆą░ąĮčīčłąĄ ą▒čŗą╗ ą▓ čåąĄąĮčéčĆąĄ - ą║ąŠą┤ 80h (čŹčüč鹥čéąĖč湥čüą║ąĖ). ąĮąŠ ą▓ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ, ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ ąĖ čüą░ą╝ąŠą╝ ą┤ąĄčłąĖčäčĆą░č鹊čĆąĄ ą▒čŗą╗ąŠ ą╝ąĮąŠą│ąŠ ąĮą░ą┐čĆčÅą│ą░ ąĖąĘ-ąĘą░ čŹč鹊ą│ąŠ. čÅ ąĄą│ąŠ čüą╝ąĄčüčéąĖą╗ ą┤ąŠ FEh ąĖ ą┤ąŠą▓ąŠą╗ąĄąĮ. ą▓ąĮąĖą║ąĮąĖč鹥 ą▓ ąĖą┤ąĄą░ą╗ąŠą│ąĖčÄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ą┐ąŠą╣ą╝čæč鹥, ą┐ąŠč湥ą╝čā) (ą║ č鹊ą╝čā ąČąĄ ą┐čĆąŠčåąĄčüčüąŠčĆ - ąĮąĄ ą┤ą╗čÅ ąĖąĮą┤čāčüąŠą▓: ą┐ąŠ-ąĖą┤ąĄąĄ, čłą║ąŠą╗čīąĮąĖą║, čāąČąĄ ą▓ą╗ą░ą┤ąĄčÄčēąĄą╣ čéą░ą▒ą╗ąĖčåąĄą╣ čāą╝ąĮąŠąČąĄąĮąĖčÅ, ą╝ąŠąČąĄčé ąĮą░čāčćąĖčéčīčüčÅ ą│ąŠą╗čŗą╝ąĖ čĆčāą║ą░ą╝ąĖ ą▒ąĖčéčī ą▒ą░ą╣čé-ą║ąŠą┤ ą┐ąŠą┤ čŹč鹊čé ą┐čĆąŠčåąĄčüčüąŠčĆ, ą║ą░ą║ ąĮąĄą║ąŠą│ą┤ą░ ą▒ąĖą╗ ąĖ čÅ 25 ą╗ąĄčé ąĮą░ąĘą░ą┤ ą▓ ą┤ą░ą╝ą┐ą░čģ ąĀąÉąöąśą×-86ąĀąÜ) P.S.: ąÆčüčæ┬Āčéą░ą║ąĖ XXI ą▓ąĄą║ ąĖ ą▓ FPGA-čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮą░ čéą░ą▒ą╗ąĖčåčā ą║ąŠą╝ą░ąĮą┤ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖąĄ ą▓ąĄąĮčéąĖą╗ąĄą╣ ąĮąĄ ą┤ąŠą╗ąČąĮąŠ ąŠą║ą░ąĘčŗą▓ą░čéčī ąĮąĖą║ą░ą║ąŠą│ąŠ ą▓ą╗ąĖčÅąĮąĖčÅ. (ą┐ą░ą┐, ą░ ą┐ąŠč湥ą╝čā ą▓ IA-64 00=ADD? čüčŗąĮąŠą║, ą▓ ąśąĮč鹥ą╗ č鹊ą│ą┤ą░ ą▒čŗą╗ ąĮą░ą┐čĆčÅą│ ąĖ ąČą░ą╗ąŠ ą┐ą░čÅą╗čīąĮąĖą║ą░ ą┤ąŠčüčéą░ą╗ąŠ ąŠčé čüčāą╝ą╝ą░č鹊čĆą░ ą┤ąŠ ą┐ąĄčĆą▓ąŠą╣ ąĮąŠąČą║ąĖ ą┤ąĄčłąĖčäčĆą░č鹊čĆą░ )
_________________
ą» č鹥ą▒čÅ ą┐ąŠą╗čÄą▒ąĖą╗, čÅ č鹥ą▒čÅ ąĮą░čāčćčā! ┬®ąŻčŹčä
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
LastHopeMan
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¦čé čÅąĮą▓ 12, 2017 23:36:59 |
|
| ąÆčŗą╝ąŠą│ą░č鹥ą╗čī ą┐čĆąĖą┐ąŠčÅ |
 |
ąÜą░čĆą╝ą░: 2
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: -38
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¤čé čüąĄąĮ 30, 2016 05:52:37
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 529
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
|
ąóąĪ, ą░ ą▓ą░čł ą┐čĆąŠčåąĄčüčüąŠčĆ - čŹč鹊 ą▓ąĖčĆčéčāą░ą╗čīąĮąŠ-ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ ą┐čĆąŠą┤čāą║čé, ąĖą╗ąĖ ąČąĄ čĆąĄą░ą╗čīąĮąŠąĄ ąČąĄą╗ąĄąĘąĮąŠąĄ ą▓ąŠą┐ą╗ąŠčēąĄąĮąĖąĄ ąĮą░ čéčĆą░ąĮąĘąĖčüč鹊čĆą░čģ\ąóąóąø ą╗ąŠą│ąĖą║ąĄ?
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
Paguo-86PK
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¤čé čÅąĮą▓ 13, 2017 00:26:17 |
|
| ą×ą┐čŗčéąĮčŗą╣ ą║ąŠčé |
|
ąÜą░čĆą╝ą░: 15
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 16
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¦čé ą░ą▓ą│ 19, 2010 23:49:19
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 803
ą×čéą║čāą┤ą░: ąóą░čłą║ąĄąĮčé
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
LastHopeMan ą┐ąĖčüą░ą╗(ą░): ąóąĪ, ą░ ą▓ą░čł ą┐čĆąŠčåąĄčüčüąŠčĆ - čŹč鹊 ą▓ąĖčĆčéčāą░ą╗čīąĮąŠ-ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ ą┐čĆąŠą┤čāą║čé, ąĖą╗ąĖ ąČąĄ čĆąĄą░ą╗čīąĮąŠąĄ ąČąĄą╗ąĄąĘąĮąŠąĄ ą▓ąŠą┐ą╗ąŠčēąĄąĮąĖąĄ ąĮą░ čéčĆą░ąĮąĘąĖčüč鹊čĆą░čģ\ąóąóąø ą╗ąŠą│ąĖą║ąĄ? ąÆočé čŹč鹊 ą▓ąŠą┐čĆąŠčü ą┐ąŠ čüčāčēąĄčüčéą▓čā  ąŁč鹊čé ą┐čĆąŠčåąĄčüčüąŠčĆ - ąĮą░ą▓ąĄčĆąĮąŠąĄ čéčĆąĖą┤čåą░čéčŗą╣ ą┐ąŠ čüčćčæčéčā, ą║ąŠč鹊čĆčŗą╣ ą╝ąĮąĄ čāą┤ą░ą╗ąŠčüčī ąŠąČąĖą▓ąĖčéčī 菹╝čāą╗čÅčåąĖąĄą╣. ąöąŠ čŹč鹊ą│ąŠ, ąĄčēčæ čü 17 ą╗ąĄčé, ą┐čŗčéą░ą╗čüčÅ čĆą░ąĘčĆą░ą▒ąŠčéą░čéčī ąĖą┤ąĄą░ą╗čīąĮčŗą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▒ąĄąĘ ą┐ąĄčĆąĄąČąĖčéą║ąŠą▓ ą┐čĆąŠčłą╗čŗčģ 菹┐ąŠčģ. ąØąŠ, ą┤ą░ą╗čīčłąĄ ąĮą░ą▒čĆąŠčüą║ąŠą▓ ą┤ąĄą╗ą░ ąĮąĄ ą┤ąŠčģąŠą┤ąĖą╗ąŠ, čéą░ą║ ą║ą░ą║ ą┐čĆąĖčüčéčāą┐ą░čÅ ą║ 菹╝čāą╗čÅčåąĖąĖ ąĮą░čéčŗą║ą░ą╗čüčÅ ąĮą░ čĆčÅą┤ ą║ąŠąĮčåąĄą┐čéčāą░ą╗čīąĮčŗčģ ą┐čĆąŠą▒ą╗ąĄą╝ (ąĘą░ą│čĆčāąĘą║ą░ ą▓ čüč鹥ą║ ąĮą░ ą┤ąĄą╗ąĄ ąĮąĄ čéą░ą║ą░čÅ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ą░ą║ ąĮą░ą╝ąĄčćą░ą╗ą░čüčī. ąĖ čé.ą┤.) ą£ąŠąČąĮąŠ čüą║ą░ąĘą░čéčī, čŹč鹊 - ą┐ąĄčĆą▓čŗą╣ ą┐čĆą░ą║čéąĖč湥čüą║ąĖą╣ čłą░ą│, ą│ą┤ąĄ ąĖ 菹╝čāą╗čÅč鹊čĆ čĆą░ą▒ąŠčéą░ąĄčé, ąĖ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆ ąĖą╝ąĄąĄčéčüčÅ, ąĖ ą░čüčüąĄą╝ą▒ą╗ąĄčĆ čüąĮąŠčüąĮąŠ čĆą░ą▒ąŠčéą░ąĄčé, ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘą░ą┤ą░čć ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▓ čüčĆąĄą┤ąĄ čü ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąŠą╣. ą¤čĆą░ą▓ą┤ą░, ąĄčüčéčī ą▒čāą║ąĄčé ąĮąĄą┤ąŠčćčæč鹊ą▓, čü ą║ąŠč鹊čĆčŗą╝ąĖ ąĮčāąČąĮąŠ ą┤ąŠą╗ą│ąŠ ąĖ ąĮčāą┤ąĮąŠ čüą┐čĆą░ą▓ą╗čÅčéčīčüčÅ. ąØąŠ, ą┐čĆą░ą║čéąĖč湥čüą║ąĖ, č鹊, čćč鹊 20 ą╗ąĄčé ąĮą░ąĘą░ą┤ čÅ ąĮą░ą▒čĆąŠčüą░ą╗ ą▓ DOS 3.11 ąĮą░ "ą¤ąŠąĖčüą║ąĄ", ą╝ąĮąĄ ąĮą░ą║ąŠąĮąĄčå-č鹊 čāą┤ą░ą╗ąŠčüčī "ąŠąČąĖą▓ąĖčéčī". ąöčāą╝ą░čÄ, ą▓ ąŠą┤ąĖąĮąŠčćą║čā ą▓ą┐ąĖčģąĖą▓ą░čéčī ą▓čüčæ čŹč鹊 ą▓ ą¤ąøąśąĪ ą▒čāą┤čā ą│ąŠą┤ą░ą╝ąĖ. ąóą░ą║ ą║ą░ą║ ąĖ ą▓ Chrome ą║ąŠąĮčüąŠą╗ąĖ čü ą┐ąŠčłą░ą│ąŠą▓ąŠą╣ ąŠčéą╗ą░ą┤ą║ąŠą╣ čüą║čĆąĖą┐čéą░ čćčāą┤ąŠą▓ąĖčēąĮąŠ čüą╗ąŠąČąĮąŠ ąŠčéą╗ą░ą▓ą╗ąĖą▓ą░čéčī ą▓čüąĄ ą│ą╗čÄčćąĮčŗąĄ čüąĖčéčāą░čåąĖąĖ. ą¤ąŠ ą╝ąŠąĖą╝ čüą║čĆąŠą╝ąĮčŗą╝ ąĖ ą║čĆą░ą╣ąĮąĄ ą│čĆčāą▒čŗą╝ ąŠčåąĄąĮą║ą░ą╝ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐ą░čÅą╗čīąĮąĖą║ąŠą╝ ą┐ąŠčéčĆąĄą▒čāąĄčé ąŠą║ąŠą╗ąŠ 20 čéčŗčüčÅčć čéčĆą░ąĮąĘąĖčüč鹊čĆąŠą▓, čćč鹊 čüą╗ąĖčłą║ąŠą╝ ąĖąĘą▒čŗč鹊čćąĮąŠ. ąØąŠ, ąĘą┤ąĄčüčī ąĖą╝ąĄčÄčéčüčÅ ą╝ąŠą│čāčćąĖąĄ ą┐ąĄčĆčüą┐ąĄą║čéąĖą▓čŗ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┐ąŠą┤ą║ą╗čÄčćą░čÅ ą║ ąĄą│ąŠ čłąĖąĮąĄ ą║ą░ą║ąŠąĄ-ą╗ąĖą▒ąŠ čāčüčéčĆąŠą╣čüčéą▓ąŠ, ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą░ čüą░ą╝ąŠą╣ čüąĖčüč鹥ą╝ąĄ ą║ąŠą╝ą░ąĮą┤ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ ą┐čĆąĄčäąĖą║čü ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ čü čŹčéąĖą╝ čāčüčéčĆąŠą╣čüčéą▓ąŠą╝. ąóą░ą║, ą║ąŠą┤ E0-E9 ąĮąĄ ąĖą╝ąĄąĄčé ąĮąĖą║ą░ą║ąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą║ąŠą╝ą░ąĮą┤čŗ čü čŹčéąĖą╝ ą║ąŠą┤ąŠą╝ ąĮąĄą╗čīąĘčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī, čéą░ą║ ą║ą░ą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čüą▓ą░ą╗ąĖčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ą▓ čÅą┤čĆąŠ. ą»ą┤čĆąŠ ąČąĄ čüą░ą╝ąŠ ą╝ąŠąČąĄčé ą┐ąŠą┤čéčÅąĮčāčéčī ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆąŠą▓ą░čéčī čŹčéąĖ ą║ąŠą╝ą░ąĮą┤čŗ. ąØąŠ, ąĄčüą╗ąĖ čäąĖąĘąĖč湥čüą║ąĖ ą║ ą┐čĆąŠčåąĄčüčüąŠčĆčā ą┐ąŠą┤ą║ą╗čÄč湥ąĮąŠ ą║ą░ą║ąŠąĄ-č鹊 čāčüčéčĆąŠą╣čüčéą▓ąŠ ąĖ ąĘą░ ąĮąĖą╝ ąĘą░ą║čĆąĄą┐ą╗čæąĮ ąŠą┤ąĖąĮ ąĖąĘ č鹥čģ ą║ąŠą┤ąŠą▓, č鹊 čŹč鹊 čāčüčéčĆąŠą╣čüčéą▓ąŠ čüčéą░ąĮąĄčé ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄą╝ ą┤ąĄčłąĖčäčĆą░č鹊čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ąŠą▒čĆą░ą▒ąŠčéą░ąĄčé ąĮčāąČąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ čüą░ą╝ąŠ. ąÜ č鹊ą╝čā ąČąĄ ą┐čĆąŠčåąĄčüčüąŠčĆ ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗąĄ ą▓čŗą▓ąŠą┤ą░ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╝čā čäą░ą╣ą╗čā. ą¦č鹊 ą┐ąŠąĘą▓ąŠą╗ąĖą╗ąŠ ą▒čŗ ąĮą░čĆą░čēąĖą▓ą░čéčī čüąĖčüč鹥ą╝čā ą║ąŠą╝ą░ąĮą┤ ą░ą┐ą┐ą░čĆą░čéąĮąŠ. ąæčāą┤čī č鹊 ąĖąĮčüčéčĆčāą║čåąĖąĖ FPU/MMX/SSE ąĖą╗ąĖ ą║ą░ą║ąĖąĄ-č鹊 ą┤čĆčāą│ąĖąĄ. P.S.: ą¤ą╗ą░ąĮčŗ,┬Āą║ąŠąĮąĄčćąĮąŠ, ą░ą╝ą▒ąĖčåąĖąŠąĘąĮąŠ ą│čĆą░ąĮą┤ąĖąŠąĘąĮčŗąĄ. ąÜą░ą║ ą▓ąĖą┤ąĮąŠ ąĖąĘ ąŠčäąĖčåąĖą░ą╗čīąĮąŠą╣ čüčéčĆą░ąĮąĖčćą║ąĖ, x80 - ąČąĄą╗ą░ąĄą╝ą░čÅ ą╗ąĖąĮąĄą╣ą║ą░, ą┐ąŠą┤ąŠą▒ąĮąŠ x86, ą│ą┤ąĄ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéčī ą┤ąŠą╗ąČąĮą░ čüąŠčģčĆą░ąĮčÅčéčīčüčÅ ą╝ąĄąČą┤čā ą┤čĆčāą│ ą┤čĆčāą│ąŠą╝, ąĖ čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī ąŠčé 8 ą┤ąŠ 16- ąĖ 32-ą▒ąĖčé ąĮą░ą╝ąĄčćą░ąĄčéčüčÅ ą▓ ą┐ąĄčĆčüą┐ąĄą║čéąĖą▓ąĄ. ą¤čĆąĖčćčæą╝, ą║ą░ą║čĆą░čü-čéą░ą║ąĖ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéčī ą▓ ąŠą▒ąĄ čüč鹊čĆąŠąĮčŗ: ąĢčüą╗ąĖ ąĮčāąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐čĆąŠą│čĆą░ą╝ą╝čā "čüą▓ąĄąČąĄą│ąŠ" ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮą░ "čüčéą░čĆąŠą╝", ą│ą┤ąĄ ąĮąĄčé ą║ą░ą║ąĖčģ-č鹊 ąĖąĮčüčéčĆčāą║čåąĖą╣, ąĖčģ ą╝ąŠąČąĮąŠ 菹╝čāą╗ąĖčĆąŠą▓ą░čéčī čÅą┤čĆąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ ąĖą╗ąĖ 菹╗ąĄą║čéčĆąĖč湥čüą║ąĖ ą┐ąŠą┤ą║ą╗čÄčćąĖą▓ ą║ ą┐čĆąŠčåąĄčüčüąŠčĆčā ąĮčāąČąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą║ą░ą║ ą┐čĆąĖčüčéą░ą▓ą║čā ą╝ ąĮą░čĆą░čüčéąĖčéčī ą┤ąĄčłąĖčäčĆą░č鹊čĆ čÅą┤čĆą░. ą× čćčæą╝ čÅ ą╝ąĄčćčéą░ą╗ 20 ą╗ąĄčé ąĮą░ąĘą░ą┤ 
_________________
ą» č鹥ą▒čÅ ą┐ąŠą╗čÄą▒ąĖą╗, čÅ č鹥ą▒čÅ ąĮą░čāčćčā! ┬®ąŻčŹčä
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
LastHopeMan
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¤čé čÅąĮą▓ 13, 2017 01:12:07 |
|
| ąÆčŗą╝ąŠą│ą░č鹥ą╗čī ą┐čĆąĖą┐ąŠčÅ |
|
ąÜą░čĆą╝ą░: 2
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: -38
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¤čé čüąĄąĮ 30, 2016 05:52:37
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 529
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
|
ą¤čāčüą║ą░čéčī čāčüčéčĆąŠą╣čüčéą▓ą░ ąĘą░ ą┤ąĄčłąĖčäčĆą░č鹊čĆąŠą╝ - čŹč鹊 ąĘą┤čĆą░ą▓ą░čÅ ąĖą┤ąĄčÅ, ą║ą░ą║ ąĖą┤ąĄčÅ. ą» ąĖą╝ąĄąĮąĮąŠ čéą░ą║ ą┐ą╗ą░ąĮąĖčĆčāčÄ čāčüčéčĆą░ąĖą▓ą░čéčī čüą▓ąŠčÄ čüą░ą╝ąŠą┤ąĄą╗ą║čā. ąØąŠ ąĄčüą╗ąĖ ą┐čĆąĖčüą╝ąŠčéčĆąĄčéčīčüčÅ, č鹊 čéąĖą┐ąŠą▓ą░čÅ čüčģąĄą╝ą░ ąĖąĮč鹥ą╗ąŠą▓čüą║ąĖčģ ą¤ąÜ ą║ą░ą║ čĆą░ąĘ ąĖ čÅą▓ą╗čÅą╗ą░čüčī čŹčéąĖą╝ ą▓ąŠą┐ą╗ąŠčēąĄąĮąĖąĄą╝. ą×ą▒čēą░čÅ čłąĖąĮą░, ą┐čĆąŠčåąĄčüčüąŠčĆ ą║ąŠą╝ą░ąĮą┤čāąĄčé čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ ąĮą░ ąĮąĄą╣. ąÉ ą▓čŗ ą┐ąŠčģąŠąČąĄ čģąŠčéąĖč鹥, čćč鹊ą▒čŗ ą▓ąĮčāčéčĆąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ č鹊ąČąĄ čüą╗ąŠąČąĖą╗ą░čüčī ą┐ąŠą┤ąŠą▒ąĮą░čÅ čüąĖčüč鹥ą╝ą░, ąĄčüą╗ąĖ čÅ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ą┐ąŠąĮčÅą╗. ąŁč鹊 čģąŠčĆąŠčłą░čÅ ą╝čŗčüą╗čī, ąĄčüą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆ čÅą▓ą╗čÅąĄčéčüčÅ čüą▒ąŠčĆąĮčŗą╝ čü "ą╝ąŠą┤čāą╗čÅą╝ąĖ", ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą┤ą║ą╗čÄčćą░čéčī. ąØąŠ ą▓ ąĮą░čłąĄ ą▓čĆąĄą╝čÅ ąŻą¢ąĢ ąĮąĄ ą┐čĆą░ą║čéąĖčćąĮąŠ. ąøąĖąĮąĖąĖ ą┤ą╗ąĖąĮąĮąĄąĄ, čĆą░ąĘą╝ąĄčĆčŗ ą▒ąŠą╗čīčłąĄ. ą¤ąŠčŹč鹊ą╝čā ą┐ąĄčĆčüą┐ąĄą║čéąĖą▓ čā ą┤ą░ąĮąĮąŠą│ąŠ ą┐ąŠą┤čģąŠą┤ą░ ąĮąĄčé - ą▓čüčÅ ą▓čŗčüąŠą║ąŠčćą░čüč鹊čéąĮąŠčüčéčī ą▓ čāą║ąŠčĆąŠč湥ąĮąĖąĖ ą╗ąĖąĮąĖą╣ ą▓ąĮčāčéčĆąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ą¦č鹊 ąČąĄ ą║ą░čüą░ąĄčéčüčÅ ąŠą┐ą║ąŠą┤ąŠą▓ ąĖ ą░ąĮąĄą║ą┤ąŠčéą░ ą┐čĆąŠ čüčāą╝ą╝ą░č鹊čĆ, č鹊 ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą▓čüąĄ ąĖą╝ąĄąĮąĮąŠ čéą░ą║. ąÜąŠą│ą┤ą░ čÅ ą┐čĆąĖčüčéčāą┐ąĖą╗ ą║ ąĮą░ą┐ąĖčüą░ąĮąĖčÄ čģąŠčéčī ą║ą░ą║ąŠą╣-č鹊 čüčģąĄą╝čŗ ą┤ą╗čÅ ą┐ąŠą┤ąŠą▒ąĮąŠą╣ ą▓ąĄčēąĖčåčŗ, č鹊 ą▓ ą┐ąĄčĆą▓čŗą╣ ąČąĄ ą┤ąĄąĮčī čüčéą░ą╗ąŠ ąŠč湥ą▓ąĖą┤ąĮąŠ: čĆą░ą┤ąĖ ą┐čĆąŠčüč鹊čéčŗ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ čÅ ą│ąŠč鹊ą▓ ą┐ąŠąČąĄčĆčéą▓ąŠą▓ą░čéčī 90% čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéąĖ ąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ. ąæčāą┤čī čā ą╝ąĄąĮčÅ ąĘą░ą▓ąŠą┤ ą┐ąŠą┤ čĆčāą║ąŠą╣ - ą▓čüąĄ čĆą░ą▓ąĮąŠ ą▒čŗ čüą┤ąĄą╗ą░ą╗ čéą░ą║ąČąĄ. ąöąĄčłąĖčäčĆą░č鹊čĆ - čŹč鹊 č湥čĆč鹊ą▓čüą║ąĖ čüą╗ą░ą▒ąŠąĄ ą╝ąĄčüč鹊 ąĮą░ ą╝ąŠą╣ ą▓ąĘą│ą╗čÅą┤, ą┐čĆąĖ čüą╗ąŠąČąĮąŠą╣ ąĄą│ąŠ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ (ą║ąŠą╝ą░ąĮą┤čŗ ą▓ą┐ąĄčĆąĄą╝ąĄčłą║čā čĆą░ąĘą╗ąĖčćąĮąŠą│ąŠ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ) ą┤ąĄčłąĖčäčĆą░čåąĖčÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą║ąŠą╝ą░ąĮą┤ ą╝ąŠąČąĄčé ąĘą░ąĮąĖą╝ą░čéčī ąŠčēčāčéąĖą╝ąŠąĄ ą▓čĆąĄą╝čÅ, ą╗ąĖą▒ąŠ ąŠčēčāčéąĖą╝ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéčĆą░ąĮąĘąĖčüč鹊čĆąŠą▓. ąŁč鹊 ą▓čüąĄ č湥čĆč鹊ą▓čüą║ąĖ ąĮąĄ ąŠą║čāą┐ą░ąĄčéčüčÅ. ą¤ąŠą║ą░ čŹč鹊 ą▓čüąĄ ą▓ąĖčĆčéčāą░ą╗čīąĮąŠ, č鹊 ą╝ąŠąČąĮąŠ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ąĖ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░čéčī. ąÜą░ą║ č鹊ą╗čīą║ąŠ ą┐ąĄčĆąĄčģąŠą┤ąĖą╝ ą║ ą┐čĆą░ą║čéąĖą║ąĄ - čāą▓čŗ...
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
Paguo-86PK
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¤čé čÅąĮą▓ 13, 2017 13:11:31 |
|
| ą×ą┐čŗčéąĮčŗą╣ ą║ąŠčé |
|
ąÜą░čĆą╝ą░: 15
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 16
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¦čé ą░ą▓ą│ 19, 2010 23:49:19
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 803
ą×čéą║čāą┤ą░: ąóą░čłą║ąĄąĮčé
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
LastHopeMan ą┐ąĖčüą░ą╗(ą░): ą¤čāčüą║ą░čéčī čāčüčéčĆąŠą╣čüčéą▓ą░ ąĘą░ ą┤ąĄčłąĖčäčĆą░č鹊čĆąŠą╝ - čŹč鹊 ąĘą┤čĆą░ą▓ą░čÅ ąĖą┤ąĄčÅ, ą║ą░ą║ ąĖą┤ąĄčÅ. ą» ąĖą╝ąĄąĮąĮąŠ čéą░ą║ ą┐ą╗ą░ąĮąĖčĆčāčÄ čāčüčéčĆą░ąĖą▓ą░čéčī čüą▓ąŠčÄ čüą░ą╝ąŠą┤ąĄą╗ą║čā. ąØąŠ ąĄčüą╗ąĖ ą┐čĆąĖčüą╝ąŠčéčĆąĄčéčīčüčÅ, č鹊 čéąĖą┐ąŠą▓ą░čÅ čüčģąĄą╝ą░ ąĖąĮč鹥ą╗ąŠą▓čüą║ąĖčģ ą¤ąÜ ą║ą░ą║ čĆą░ąĘ ąĖ čÅą▓ą╗čÅą╗ą░čüčī čŹčéąĖą╝ ą▓ąŠą┐ą╗ąŠčēąĄąĮąĖąĄą╝. ą×ą▒čēą░čÅ čłąĖąĮą░, ą┐čĆąŠčåąĄčüčüąŠčĆ ą║ąŠą╝ą░ąĮą┤čāąĄčé čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ ąĮą░ ąĮąĄą╣. ąÉ ą▓čŗ ą┐ąŠčģąŠąČąĄ čģąŠčéąĖč鹥, čćč鹊ą▒čŗ ą▓ąĮčāčéčĆąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ č鹊ąČąĄ čüą╗ąŠąČąĖą╗ą░čüčī ą┐ąŠą┤ąŠą▒ąĮą░čÅ čüąĖčüč鹥ą╝ą░, ąĄčüą╗ąĖ čÅ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ą┐ąŠąĮčÅą╗. ąŁč鹊 čģąŠčĆąŠčłą░čÅ ą╝čŗčüą╗čī, ąĄčüą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆ čÅą▓ą╗čÅąĄčéčüčÅ čüą▒ąŠčĆąĮčŗą╝ čü "ą╝ąŠą┤čāą╗čÅą╝ąĖ", ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą┤ą║ą╗čÄčćą░čéčī. ąØąŠ ą▓ ąĮą░čłąĄ ą▓čĆąĄą╝čÅ ąŻą¢ąĢ ąĮąĄ ą┐čĆą░ą║čéąĖčćąĮąŠ. ąøąĖąĮąĖąĖ ą┤ą╗ąĖąĮąĮąĄąĄ, čĆą░ąĘą╝ąĄčĆčŗ ą▒ąŠą╗čīčłąĄ. ą¤ąŠčŹč鹊ą╝čā ą┐ąĄčĆčüą┐ąĄą║čéąĖą▓ čā ą┤ą░ąĮąĮąŠą│ąŠ ą┐ąŠą┤čģąŠą┤ą░ ąĮąĄčé - ą▓čüčÅ ą▓čŗčüąŠą║ąŠčćą░čüč鹊čéąĮąŠčüčéčī ą▓ čāą║ąŠčĆąŠč湥ąĮąĖąĖ ą╗ąĖąĮąĖą╣ ą▓ąĮčāčéčĆąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ą¦č鹊 ąČąĄ ą║ą░čüą░ąĄčéčüčÅ ąŠą┐ą║ąŠą┤ąŠą▓ ąĖ ą░ąĮąĄą║ą┤ąŠčéą░ ą┐čĆąŠ čüčāą╝ą╝ą░č鹊čĆ, č鹊 ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą▓čüąĄ ąĖą╝ąĄąĮąĮąŠ čéą░ą║. ąÜąŠą│ą┤ą░ čÅ ą┐čĆąĖčüčéčāą┐ąĖą╗ ą║ ąĮą░ą┐ąĖčüą░ąĮąĖčÄ čģąŠčéčī ą║ą░ą║ąŠą╣-č鹊 čüčģąĄą╝čŗ ą┤ą╗čÅ ą┐ąŠą┤ąŠą▒ąĮąŠą╣ ą▓ąĄčēąĖčåčŗ, č鹊 ą▓ ą┐ąĄčĆą▓čŗą╣ ąČąĄ ą┤ąĄąĮčī čüčéą░ą╗ąŠ ąŠč湥ą▓ąĖą┤ąĮąŠ: čĆą░ą┤ąĖ ą┐čĆąŠčüč鹊čéčŗ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ čÅ ą│ąŠč鹊ą▓ ą┐ąŠąČąĄčĆčéą▓ąŠą▓ą░čéčī 90% čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéąĖ ąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ. ąæčāą┤čī čā ą╝ąĄąĮčÅ ąĘą░ą▓ąŠą┤ ą┐ąŠą┤ čĆčāą║ąŠą╣ - ą▓čüąĄ čĆą░ą▓ąĮąŠ ą▒čŗ čüą┤ąĄą╗ą░ą╗ čéą░ą║ąČąĄ. ąöąĄčłąĖčäčĆą░č鹊čĆ - čŹč鹊 č湥čĆč鹊ą▓čüą║ąĖ čüą╗ą░ą▒ąŠąĄ ą╝ąĄčüč鹊 ąĮą░ ą╝ąŠą╣ ą▓ąĘą│ą╗čÅą┤, ą┐čĆąĖ čüą╗ąŠąČąĮąŠą╣ ąĄą│ąŠ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ (ą║ąŠą╝ą░ąĮą┤čŗ ą▓ą┐ąĄčĆąĄą╝ąĄčłą║čā čĆą░ąĘą╗ąĖčćąĮąŠą│ąŠ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ) ą┤ąĄčłąĖčäčĆą░čåąĖčÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą║ąŠą╝ą░ąĮą┤ ą╝ąŠąČąĄčé ąĘą░ąĮąĖą╝ą░čéčī ąŠčēčāčéąĖą╝ąŠąĄ ą▓čĆąĄą╝čÅ, ą╗ąĖą▒ąŠ ąŠčēčāčéąĖą╝ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéčĆą░ąĮąĘąĖčüč鹊čĆąŠą▓. ąŁč鹊 ą▓čüąĄ č湥čĆč鹊ą▓čüą║ąĖ ąĮąĄ ąŠą║čāą┐ą░ąĄčéčüčÅ. ą¤ąŠą║ą░ čŹč鹊 ą▓čüąĄ ą▓ąĖčĆčéčāą░ą╗čīąĮąŠ, č鹊 ą╝ąŠąČąĮąŠ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ąĖ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░čéčī. ąÜą░ą║ č鹊ą╗čīą║ąŠ ą┐ąĄčĆąĄčģąŠą┤ąĖą╝ ą║ ą┐čĆą░ą║čéąĖą║ąĄ - čāą▓čŗ... ąÜąŠą│ą┤ą░ ą▓ ą┤ąĄčéčüčéą▓ąĄ čćąĖčéą░ą╗ ąŠčéčåąŠą▓čüą║ąĖąĄ čüą┐čĆą░ą▓ąŠčćąĮąĖą║ąĖ čü ąŠą┐ąĖčüą░ąĮąĖąĄą╝ čāčüčéčĆąŠą╣čüčéą▓ ąŁąÆą£, ąĖąĮąŠą│ą┤ą░ ą╝ąĄčćčéą░ą╗ ą▒čŗčéčī ąĖąĮąČąĄąĮąĄčĆąŠą╝ ąĖ čāčćą░čüčéą▓ąŠą▓ą░čéčī ą▓ čĆą░ąĘčĆą░ą▒ąŠčéą║ą░čģ ą╝ą░čłąĖąĮ, ą┐ąŠą┤ąŠą▒ąĮčŗčģ Cray ąĖ CYBERŌĆ” ąØą░ č乊č鹊ą│čĆą░čäąĖčÅčģ ą▓ąĖą┤ąĮąŠ, ą║ą░ą║ ą╝ąĮąŠą│ąŠ čéą░ą╝ ą▒čŗą╗ąŠ ą║ą░ą▒ąĄą╗ąĄą╣. ą¦č鹊, č鹥ą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, ąĮąĄ ą╝ąĄčłą░ą╗ąŠ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╣ čĆą░ą▒ąŠč鹥. ąÆąŠčé ą▓ą░ą╝ąĖ ą▓čŗčłąĄ čüą║ą░ąĘą░ąĮąŠ, čćč鹊 ą▓ i8086 ą║ąŠą╝ą░ąĮą┤ą░ ADD ą┐ąŠą╗čāčćąĖą╗ą░ ą║ąŠą┤ 00 ą▓ čćą░čüčéąĮąŠčüčéąĖ ą┐ąŠ ą┐čĆąĖčģąŠčéąĖ ą┤ą╗ąĖąĮčŗ ą┐čĆąŠą▓ąŠą╗ąŠč湥ą║ ą┤ąĄčłąĖčäčĆą░č鹊čĆą░ ąĮą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ. ąĪčĆą░ą▓ąĮąĖč鹥 č乊č鹊ą│čĆą░čäąĖąĖ ą║čĆąĖčüčéą░ą╗ą╗ąŠą▓ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ąŠą┤ąĮąŠą╣ ą╗ąĖąĮąĄą╣ą║ąĖ. ąÆąĖą┤ąĮąŠ, čćč鹊 ąĮą░ ą┐ąĄčĆą▓ąŠą╝ - čüą┐ą╗ąŠčłąĮąŠą╣ ą▒ą░čĆą┤ą░ą║ ąĖąĘ čüą┐ą░ąĄą║ ą┐čĆąŠą▓ąŠą╗ąŠą║, č鹊ą│ą┤ą░ ą║ą░ą║ ą┤ą░ą╗čīčłąĄ čüčéčĆčāą║čéčāčĆą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą▒ąŠą╗ąĄąĄ čćčæčéą║ąŠą╣ ąĖ ą║čĆą░čüąĖą▓ąŠą╣. ąś ąĮąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ąŠą┐čĆą░ą▓ą┤ą░ąĮąĖčÅ ą┐čĆąĖčćčāą┤ą░ą╝ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą┤ąĄčłąĖčäčĆą░č鹊čĆą░ ą║ąŠą╝ą░ąĮą┤ čü čāčĆąŠą┤ąŠą▓ą░ąĮąĖąĄą╝ čéą░ą▒ą╗ąĖčåčŗ čüąĖčüč鹥ą╝čŗ ą║ąŠą╝ą░ąĮą┤ ą┐ąĄčĆą▓ąŠą│ąŠ i8086. ąÜą░ą║-č鹊 ą▓ Visual Basic ą╝ąĮąŠčÄ ą▒čŗą╗ ą┐čĆąĖą┤čāą╝ą░ąĮ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ. ąś ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čģąŠčéčī ą║ą░ą║ąĖąĄ-č鹊 ą░ą▓č鹊čĆčüą║ąĖąĄ ą┐čĆą░ą▓ą░ ąĮą░ ąĮąĄą│ąŠ, čÅ ąĘą░ąĮčÅą╗čüčÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣ ąĄą│ąŠ ą┐čĆąŠčĆąĖčüąŠą▓ą║ąĖ. ą×ą┤ąĖąĮ ąĖąĘ ą┤čĆčāąĘąĄą╣ ą║ą░ą║-č鹊 čüą┐čĆąŠčüąĖą╗, ą╝ąŠą╗ ąĘą░č湥ą╝ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ą┐ąŠą┤ ą┐ą╗ą░čéč乊čĆą╝čā Windows, ą║ąŠą│ą┤ą░ čŹč鹊 čüą┤ąĄą╗ą░čÄčé ą┤čĆčāą│ąĖąĄ ą┐ąŠą┤ čüą▓ąŠčÄ ą┐ą╗ą░čéč乊čĆą╝čā? ąōą╗ą░ą▓ąĮąŠąĄ - ą┐ąŠą╗čāčćąĖčéčī ą┐čĆą░ą▓ą░ ą░ą▓č鹊čĆčüčéą▓ą░. ąØąŠ ąĮąĄčé ąČąĄ, čÅ ą║ą░ą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé, ą░ ąĮąĄ ą┐čĆąĄą┤ą┐čĆąĖąĮąĖą╝ą░č鹥ą╗čī, ą┤ąŠčüčéą░ą╗ Visual C++ 6 ąĖ ą┐čĆąŠą┤ąŠą╗ąČą░ą╗ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ą┐čĆąŠčĆąĖčüąŠą▓ą║čā čāąČąĄ ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ ą┤ąŠ čāčĆąŠą▓ąĮčÅ MMXŌĆ” ąÉ č鹥ą┐ąĄčĆčī, ąĮą░ ą╗čÄą▒čŗčģ ąÉąĮą┤čĆąŠąĖą┤ą░čģ ą▓čüčéčĆąĄčćą░čÄčéčüčÅ čŹą╗ąĄą╝ąĄąĮčéčŗ ąĮą░čüčéčĆąŠą╣ą║ąĖ, č鹊čćčī-ą▓-č鹊čćčī čüčģąŠą┤ąĮčŗąĄ čü č鹥ą╝, čćč鹊 čÅ ą▓ čüą▓ąŠąĖ ą│ąŠą┤čŗ, ą┤čāčĆą░ą║, čéčāą┐ąŠ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ą╗. ąÉ ą▓čŗ ąĮą░čüčéą░ąĖą▓ą░ąĄč鹥, čćč鹊 ąĮą░ ą┐čĆą░ą║čéąĖą║ąĄ čÅ čāą▓ąĖąČčā, čćč鹊 ą║ąŠą┤čŗ ąĮąĄą║ąŠč鹊čĆčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ čĆą░ąĘčāą╝ąĮąĄąĄ ą▒čŗą╗ąŠ ąĖąĘą╝ąĄąĮąĖčéčī, č湥ą╝ ą┐ą░čÅčéčī ą┐čĆąŠą▓ąŠą╗ąŠą║čā ąĮą░ 10 čüą╝ ą┤ą╗ąĖąĮąĮąĄąĄ. ąĪąŠą│ą╗ą░čüąĄąĮ, čéą░ą║ ą║ą░ą║ čüčéą░ą╗ą║ąĖą▓ą░ą╗čüčÅ čü ą┐ąŠą┤ąŠą▒ąĮčŗą╝ąĖ čüąĖčéčāą░čåąĖčÅą╝ąĖ. ą×č鹥čå ąĖ ą▓ąŠą▓čüąĄ čüą┐ą░čÅą╗ ą║ą╗ą░ą▓ąĖą░čéčāčĆčā ąĀą░ą┤ąĖąŠ-86ąĀąÜ ą┐ą░čāčéąĖąĮąŠą╣ ą┐čĆąŠą▓ąŠą╗ąŠč湥ą║ ąĖ čÅ čāąČą░čüą░ą╗čüčÅ ą┐čāčéą░ąĮąĮąĖčåąĄ. ą¤ąŠą║ą░ ąĮąĄ ąĮą░čāčćąĖą╗čüčÅ čĆą░ąĘą▒ąĖčĆą░čéčīčüčÅ ą▓ čüčģąĄą╝ą░čģ ąĖ ąĮąĄ ą┐ąŠąĮčÅą╗, čćč鹊 ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮą░čÅ ą║ą╗ą░ą▓ąĖą░čéčāčĆą░ ąĀąÜ čģąŠčéčī čüčģąĄą╝ą░čéąĖč湥čüą║ąĖ ąĘą░ą┐čāčéą░ąĮą░ ąĖąĘ-ąĘą░ čĆą░čüčüą║ą╗ą░ą┤ą║ąĖ, ąĮąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ - ąĮąĄ čéčĆąĄą▒čāąĄčé čéą░ą▒ą╗ąĖčå ąĖ ą┐čĆąŠąĘčĆą░čćąĮą░ ą┤ą╗čÅ ą║ąŠą┤ą░. ąÆ ąŠčéą╗ąĖčćąĖąĖ ąŠčé ą║ą╗ą░ą▓ąĖą░čéčāčĆčŗ ZX-Spectrum - čüą▓ąĄčĆčģ-ą┐čĆąŠčüč鹊ą╣ čüčģąĄą╝ą░čéąĖč湥čüą║ąĖ, ąĮąŠ čéčĆąĄą▒čāčÄčēąĄą╣ čéą░ą▒ą╗ąĖčåčŗ čĆą░čüą║ą╗ą░ą┤ą║ąĖ. P.S.: ąØą░┬Āčüčćčæčé ą▓ąĮąĄą┤čĆąĄąĮąĖčÅ ą▓ąĮąĄčłąĮąĖčģ čāčüčéčĆąŠą╣čüčéą▓ ąĮą░ą┐čĆčÅą╝čāčÄ ą▓ čüąĖčüč鹥ą╝čā ą║ąŠą╝ą░ąĮą┤ čü ą┤ąŠčüčéčāą┐ąŠą╝ ą║ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╝čā čäčĆąĄą╣ą╝čā č鹥ą║čāčēąĄą╣ ąĘą░ą┤ą░čćąĖ ąĖąĘ-ą▓ąĮąĄ čüą║ą░ąČčā ą▓ąŠčé čćč鹊. ąĪąĄą╣čćą░čü čüčāčēąĄčüčéą▓čāąĄčé čāą╣ą╝ą░ čüą▓ąĄčĆčģčüą║ąŠčĆąŠčüčéąĮčŗčģ ą┐čĆąŠč鹊ą║ąŠą╗ąŠą▓, čéąĖą┐ą░ I┬▓C, 1-wire, USB 3.0 ąĖ čé.ą┤. ąØąĄčé ąĮąĖą║ą░ą║ąĖčģ ąĘą░ą┐čĆąĄč鹊ą▓ ąŠą▒ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą┐ąŠą┤ąŠą▒ąĖčÅ čüąĄč鹥ą▓ąŠą│ąŠ ąŠą▒ą╝ąĄąĮą░ ą╝ąĄąČą┤čā ą▓ąĮąĄčłąĮąĖą╝ čāčüčéčĆąŠą╣čüčéą▓ąŠą╝ ąĖ čÅą┤čĆąŠą╝ čüą░ą╝ąŠą│ąŠ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąóąĄą╝ čüą░ą╝čŗą╝, ą┐ąŠčéčĆąĄą▒čāąĄčéčüčÅ ą▓čüąĄą│ąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓čŗą▓ąŠą┤ąŠą▓ čüą║ąŠčĆąŠčüčéąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą╣ ą╗ąĖąĮąĖąĖ, čćč鹊ą▒čŗ ą▓ąĮąĄčłąĮčÅčÅ "ą║ą░čĆč鹊čćą║ą░" ą▓ąĮąĄą┤čĆąĖą╗ą░čüčī ą▓ čüą░ą╝ ą┤ąĄčłąĖčäčĆą░č鹊čĆ ą║ąŠą╝ą░ąĮą┤ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ą╗ą░ ąĖčüą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠ čüą▓ąŠąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ą░ą║ ąĮąĄą║ąŠą│ą┤ą░ ą▒čŗą╗ąŠ čü i8087.
| ąÆą╗ąŠąČąĄąĮąĖčÅ: |
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą║ čäą░ą╣ą╗čā: CYBER 205 čäąĖčĆą╝čŗ Control Data Corporation, ą║ąŠąĮą║čāčĆąĖčĆčāčÄčēąĖą╣ čü Cray-1. ąśąĘąŠą▒čĆą░ąČąĄąĮąĮąŠąĄ ąĘą┤ąĄčüčī čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┐čĆąŠčģąŠą┤ąĖčé ąŠą║ąŠąĮčćą░č鹥ą╗čīąĮčŗąĄ ąĖčüą┐čŗčéą░ąĮąĖčÅ ąĮą░ ąĘą░ą▓ąŠą┤ąĄ čäąĖčĆą╝čŗ ą▓ ąÉčĆą┤ąĄąĮ-ąźąĖą╗ą╗čüąĄ (čłčé. ą£ąĖąĮąĮąĄčüąŠčéą░). ąĪč鹊ąĖą╝ąŠčüčéčī CYBER 205, čéą░ą║ ąČąĄ ą║ą░ą║ ąĖ Cray-1, čüąŠčüčéą░ą▓ą╗čÅąĄčé ąŠčé 10 ą┤ąŠ 15 ą╝ą╗ąĮ. ą┤ąŠą╗ą╗. ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┐ąŠčüčéą░ą▓ą╗čÅąĄą╝ąŠą│ąŠ ąŠą▒čŖčæą╝ą░ ą┐ą░ą╝čÅčéąĖ ąĖ ą┤čĆčāą│ąŠą│ąŠ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ ąŠą▒ąŠčĆčāą┤ąŠą▓ą░ąĮąĖčÅ. ą¤ąĄčĆą▓čŗą╣ CYBER 205 ą▒čŗą╗ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮ ą▓ ą£ąĄč鹥ąŠčĆąŠą╗ąŠą│ąĖč湥čüą║čāčÄ čüą╗čāąČą▒čā ąÆąĄą╗ąĖą║ąŠą▒čĆąĖčéą░ąĮąĖąĖ ą▓ 1981 ą│. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čćąĖčüą╗ąĄąĮąĮčŗčģ ą╝ąĄč鹊ą┤ąŠą▓ ą▓ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖąĖ ą┐ąŠą│ąŠą┤čŗ ą▓čŗąĘą▓ą░ą╗ąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéčī čĆą░ąĘą▓ąĖčéąĖčÅ čüčāą┐ąĄčĆą║ąŠą╝ą┐čīčÄč鹥čĆąŠą▓, ą║ąŠč鹊čĆąŠąĄ ąĮą░čćą░ą╗ąŠčüčī čü čüąŠąĘą┤ą░ąĮąĖčÅ MANIAC (Mathematical Analyzer, Numerical Integrator and Computer), čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąĮąŠą│ąŠ ą▓ ą║ąŠąĮčåąĄ 1940 ą│. ą┐ąŠą┤ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠą╝ ąöąČąŠąĮą░ č乊ąĮ ąØąĄą╣ą╝ą░ąĮą░. ąÜąŠą╝ą┐čīčÄč鹥čĆ CYBER 205 ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ čāčüąŠą▓ąĄčĆčłąĄąĮčüčéą▓ąŠą▓ą░ąĮąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé ą╝ą░čłąĖąĮčŗ STAR 100 čäąĖčĆą╝čŗ Control Data ąĖ ąĖą╝ąĄąĄčé ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéčī čåąĖą║ą╗ą░ 20 ąĮčü. ą¤ąŠčüą║ąŠą╗čīą║čā Cray-1 - ąŠč湥ąĮčī ą║ąŠą╝ą┐ą░ą║čéąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, čüąĖą│ąĮą░ą╗čŗ ą▓ ąĮąĄą╝ ą╝ąŠą│čāčé ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčīčüčÅ ąŠčé ąŠą┤ąĮąŠą╣ č鹊čćą║ąĖ ą║ ą┤čĆčāą│ąŠą╣ čüąŠ čüą║ąŠčĆąŠčüčéčīčÄ, ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄą╝ąŠą╣ ą╝ąĄą┤ąĮčŗą╝ ą┐čĆąŠą▓ąŠą┤ąĮąĖą║ąŠą╝, čé. ąĄ. ą┐čĆąĖą╝ąĄčĆąĮąŠ 0,3 čüą║ąŠčĆąŠčüčéąĖ čüą▓ąĄčéą░. ą¦č鹊ą▒čŗ čāą╝ąĄąĮčīčłąĖčéčī ą▓čĆąĄą╝čÅ ą┐čĆąŠčģąŠąČą┤ąĄąĮąĖčÅ čüąĖą│ąĮą░ą╗ąŠą▓ ą▓ CYBER 205, ą║ąŠč鹊čĆčŗą╣ ąĖą╝ąĄąĄčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą▒ąŠą╗čīčłąĖąĄ čĆą░ąĘą╝ąĄčĆčŗ, čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ ą┐čĆąĄą┤čāčüą╝ąŠčéčĆąĄą╗ąĖ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čéčŗčüčÅčć čüčģąĄą╝ąĮčŗčģ ą┐ą╗ą░čé ą║ąŠą░ą║čüąĖą░ą╗čīąĮčŗą╝ąĖ ą║ą░ą▒ąĄą╗čÅą╝ąĖ, ą┐ąŠ ą║ąŠč鹊čĆčŗą╝ čüąĖą│ąĮą░ą╗čŗ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮčÅčÄčéčüčÅ čüąŠ čüą║ąŠčĆąŠčüčéčīčÄ, ą┐čĆąĖą╝ąĄčĆąĮąŠ čĆą░ą▓ąĮąŠą╣ 0,9 čüą║ąŠčĆąŠčüčéąĖ čüą▓ąĄčéą░.
super.15.jpeg [179.54 KiB]
ąĪą║ą░čćąĖą▓ą░ąĮąĖą╣: 479
|
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą║ čäą░ą╣ą╗čā: ąÜąŠą╝ą┐čīčÄč鹥čĆ CRAY-1 (čüą╗ąĄą▓ą░) čäąĖčĆą╝čŗ Cray Research, Inc.- čŹč鹊 ąŠą┤ąĮą░ ąĖąĘ ą┤ą▓čāčģ ą┐ąŠčüčéčāą┐ą░čÄčēąĖčģ čüąĄą│ąŠą┤ąĮčÅ ą▓ ą┐čĆąŠą┤ą░ąČčā ą╝ą░čłąĖąĮ čü ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčīčÄ ąĮąĄ ą╝ąĄąĮąĄąĄ 100 ą╝ą╗ąĮ. ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą▓ čüąĄą║čāąĮą┤čā. ąØą░ č乊č鹊ą│čĆą░čäąĖąĖ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮą░ ą╝ąŠą┤ąĄą╗čī, ąĮąĄą┤ą░ą▓ąĮąŠ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮą░čÅ ą▓ Ames Research Center, ą│ą┤ąĄ ą┤ąŠ čŹč鹊ą│ąŠ čĆą░ą▒ąŠčéą░ą╗ ILLIAC IV. ąæą×ą╗čīčłą░čÅ ąĖąĘ ą┤ą▓čāčģ čüč鹊ąĄą║, ąĖąĘąŠą▒čĆą░ąČąĄąĮąĮčŗčģ ąĮą░ ą┐ąĄčĆąĄą┤ąĮąĄą╝ ą┐ą╗ą░ąĮąĄ, - čŹč鹊 ąŠčüąĮąŠą▓ąĮą░čÅ čćą░čüčéčī ą║ąŠą╝ą┐čīčÄč鹥čĆą░, ą▓ ą║ąŠč鹊čĆąŠą╣ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮčŗ čåąĄąĮčéčĆą░ą╗čīąĮčŗą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ąĖ čåąĄąĮčéčĆą░ą╗čīąĮą░čÅ ą┐ą░ą╝čÅčéčī. ą£ąĄąĮčīčłą░čÅ čüč鹊ą╣ą║ą░ - ą┐ąŠą┤čüąĖčüč鹥ą╝ą░ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░, čüąŠčüč鹊čÅčēą░čÅ ąĖąĘ čéčĆąĄčģ ą╝ą░ą╗čŗčģ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖčģ ą╝ą░čłąĖąĮ ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą┐ą░ą╝čÅčéąĖ. ąÆ ą▓čŗčüčéčāą┐ą░čÄčēąĄą╣ čćą░čüčéąĖ ąŠčüąĮąŠą▓ą░ąĮąĖčÅ ą▒ąŠą╗čīčłąŠą╣ čüč鹊ą╣ą║ąĖ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▒ą╗ąŠą║ ą┐ąĖčéą░ąĮąĖčÅ. ąØą░ č乊č鹊ą│čĆą░čäąĖąĖ čüą┐čĆą░ą▓ą░ ą┐ąŠą║ą░ąĘą░ąĮčŗ ąĘą░ą┤ąĮąĖąĄ ą┐ą░ąĮąĄą╗ąĖ čüč鹊ąĄą║, ą│ą┤ąĄ ą▓ąĖą┤ąĮąŠ ą┐ąĄčĆąĄą┐ą╗ąĄč鹥ąĮąĖąĄ ą┐čĆąŠą▓ąŠą┤ąĮąĖą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ čüąŠąĄą┤ąĖąĮčÅčÄčé ą▒ąŠą╗ąĄąĄ 1600 čüčģąĄą╝ąĮčŗčģ ą┐ą╗ą░čé čåąĄąĮčéčĆą░ą╗čīąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ą¤čĆąŠą▓ąŠą┤ąĮąĖą║ąĖ, ąŠą▒čēąĄąĄ čćąĖčüą╗ąŠ ą║ąŠč鹊čĆčŗčģ ąŠą║ąŠą╗ąŠ 300 čéčŗčüčÅčć, ą┐ąŠą┤ąŠą▒čĆą░ąĮčŗ ą┐ąŠ ą┤ą╗ąĖąĮąĄ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ čüąĖą│ąĮą░ą╗čŗ ą┐čĆąŠčģąŠą┤ąĖą╗ąĖ ą╝ąĄąČą┤čā ą╗čÄą▒čŗą╝ąĖ ą┤ą▓čāą╝čÅ č鹊čćą║ą░ą╝ąĖ ąĘą░ čéčĆąĄą▒čāąĄą╝čŗą╣ ąĖąĮč鹥čĆą▓ą░ą╗ ą▓čĆąĄą╝ąĄąĮąĖ čü čĆą░ąĘą▒čĆąŠčüąŠą╝ ąĮąĄ ą▒ąŠą╗ąĄąĄ 1 ąĮčü. ąĀą░ą▒ąŠčćąĖą╣ čåąĖą║ą╗ ą╝ą░čłąĖąĮčŗ čĆą░ą▓ąĄąĮ 12,5 ąĮčü.
super.13.jpeg [175.96 KiB]
ąĪą║ą░čćąĖą▓ą░ąĮąĖą╣: 474
|
_________________
ą» č鹥ą▒čÅ ą┐ąŠą╗čÄą▒ąĖą╗, čÅ č鹥ą▒čÅ ąĮą░čāčćčā! ┬®ąŻčŹčä
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
DX168B
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: Re: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čé ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¤čé čÅąĮą▓ 13, 2017 18:27:08 |
|
| ąöčĆčāą│ ąÜąŠčéą░ |
|
ąÜą░čĆą╝ą░: 25
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 99
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ąÆčü čÅąĮą▓ 24, 2010 19:19:52
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 4470
ą×čéą║čāą┤ą░: ąōą╗ą░ą▓ąĮčŗą╣ ąŻą╗ąĄą╣ ąĀąŠčüčüąĖąĖ (Moscow)
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
ąÜą░ą║-č鹊 čéą░ą║:   ą£ąŠąČąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī ąĄčēąĄ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąŠčĆčŗ ąĮą░ čĆąĄą│ąĖčüčéčĆ SR, čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ ąĖ ą┐čĆąŠč湥ąĄ. ąŚą░ą╝čŗčüąĄą╗ ą▓ąŠ ą▓č鹊čĆąŠą╣ ą║ą░čĆčéąĖąĮą║ąĄ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 ąŠą┐ąĄčĆą░ąĮą┤čŗ čāąĘąĄą╗ ąĘą░ą▒ąĖčĆą░ąĄčé čüą░ą╝, ą┐ąŠą║čĆčāčéąĖą▓ čüč湥čéčćąĖą║ PC. ąóą░ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą╝ąŠąČąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą▒ąŠą╗čīčłąĖą╝ čćąĖčüą╗ąŠą╝ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓. ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐ąĄčĆą▓ąŠą│ąŠ ąŠą┐ąĄčĆą░ąĮą┤ą░ ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čĆą░ą▒ąŠčćąĖčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ čāąĘąĄą╗, ąĘą░ą│čĆčāąĘąĖą▓ ąĄą│ąŠ, ą╝ąŠą│ čüąŠčĆąĖąĄąĮčéąĖčĆąŠą▓ą░čéčīčüčÅ, čüą║ąŠą╗čīą║ąŠ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą╝ąŠąČąĮąŠ ąĘą░ą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą┤ąŠ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąÉ čéčĆą░ąĮčüą╗čÅč鹊čĆ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čéą░ą║, čćč鹊ą▒čŗ čéčĆą░ąĮčüą╗čÅč鹊čĆ čüą░ą╝ ą▓čüčéą░ą▓ą╗čÅą╗ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓.
_________________
I am DX168B and this is my favourite forum on internet!
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
Paguo-86PK
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ: ą£ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆčŗ: ą¤ąŠą┐čŗčéą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ąöąŠą▒ą░ą▓ą╗ąĄąĮąŠ: ą¤čé čÅąĮą▓ 13, 2017 19:03:47 |
|
| ą×ą┐čŗčéąĮčŗą╣ ą║ąŠčé |
|
ąÜą░čĆą╝ą░: 15
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖą╣: 16
ąŚą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ: ą¦čé ą░ą▓ą│ 19, 2010 23:49:19
ąĪąŠąŠą▒čēąĄąĮąĖą╣: 803
ą×čéą║čāą┤ą░: ąóą░čłą║ąĄąĮčé
ąĀąĄą╣čéąĖąĮą│ čüąŠąŠą▒čēąĄąĮąĖčÅ: 0
|
DX168B ą┐ąĖčüą░ą╗(ą░): ą£ąŠąČąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī ąĄčēąĄ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąŠčĆčŗ ąĮą░ čĆąĄą│ąĖčüčéčĆ SR, čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ ąĖ ą┐čĆąŠč湥ąĄ.
ąŚą░ą╝čŗčüąĄą╗ ą▓ąŠ ą▓č鹊čĆąŠą╣ ą║ą░čĆčéąĖąĮą║ąĄ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 ąŠą┐ąĄčĆą░ąĮą┤čŗ čāąĘąĄą╗ ąĘą░ą▒ąĖčĆą░ąĄčé čüą░ą╝, ą┐ąŠą║čĆčāčéąĖą▓ čüč湥čéčćąĖą║ PC.
ąóą░ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą╝ąŠąČąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą▒ąŠą╗čīčłąĖą╝ čćąĖčüą╗ąŠą╝ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓. ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐ąĄčĆą▓ąŠą│ąŠ ąŠą┐ąĄčĆą░ąĮą┤ą░ ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čĆą░ą▒ąŠčćąĖčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ čāąĘąĄą╗, ąĘą░ą│čĆčāąĘąĖą▓ ąĄą│ąŠ, ą╝ąŠą│ čüąŠčĆąĖąĄąĮčéąĖčĆąŠą▓ą░čéčīčüčÅ, čüą║ąŠą╗čīą║ąŠ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą╝ąŠąČąĮąŠ ąĘą░ą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą┤ąŠ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąÉ čéčĆą░ąĮčüą╗čÅč鹊čĆ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čéą░ą║, čćč鹊ą▒čŗ čéčĆą░ąĮčüą╗čÅč鹊čĆ čüą░ą╝ ą▓čüčéą░ą▓ą╗čÅą╗ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓. ąÆačł ą┐čĆąŠčåąĄčüčüąŠčĆ ąĮą░ą┐ąŠą╝ąĖąĮą░ąĄčé ą╝ąŠą╣, ą║ąŠč鹊čĆčŗą╣ ą╝ąĮąŠą│ąĖąĄ ą║čĆąĖčéąĖą║čāčÄčé. ąĪčāčéčī ą║ąŠč鹊čĆąŠą│ąŠ ą▓ č鹊ą╝, čćč鹊 ąÉąøąŻ ą▓ ąĮčæą╝ ąŠčéčüčāčéčüčéą▓čāąĄčé, ąĮąŠ ąŠąĮ ą┐čĆąŠčüč鹊 čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ ą╝ą░čĆčłčĆčāčéąĖąĘą░č鹊čĆ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ą▓čüąĄą╝ąĖ ą▓ąĮąĄčłąĮąĖą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ, ą║ą░ą║ čāą╝ąĮčŗą╣ ą¤ąöą¤. ą¤ąŠą┤ą║ą╗čÄčćąĖą▓ ą║ ąĮąĄą╝čā ą▓ąĮąĄčłąĮąĖąĄ FPU/ALU - ą┐ąŠą╗čāčćą░ąĄą╝ ą┐ąŠą╗ąĮąŠčåąĄąĮąĮąŠąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ. P.S.: ąÆ┬Āą░čĆčģąĖą▓ąĄ - ąĘą░ą▒čĆąŠčłąĄąĮąĮčŗą╣ ąĮą░ą▒čĆąŠčüąŠą║ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ąĖą╝ąĄąĄčé čüąĖčüč鹥ą╝čŗ ą║ąŠą╝ą░ąĮą┤. ą×ąĮ čüčĆą░ąĘčā čćąĖčéą░ąĄčé ascii-ą╗ąĖčüčéąĖąĮą│ čü čüąĖąĮčéą░ą║čüąĖčüąŠą╝, čüčģąŠą┤ąĮčŗą╝ čü ąĪąĖ. ąØąĄą║ąŠą│ą┤ą░ čÅ ąĄą│ąŠ ąŠčéą╗ą░ąČąĖą▓ą░ą╗ ąĖ ą┐čŗčéą░ą╗čüčÅ ą┤ąŠą║ą░čéąĖčéčī ąĄą│ąŠ ą┤ąŠ čĆą░ą▒ąŠč湥ą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ. ąÆ čŹč鹊ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, 2x += 3y ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĮčāąČąĮąŠ ą┐čĆąŠčćąĖčéą░čéčī 3 ą▒ą░ą╣čéą░ ą┐ąŠ ą░ą┤čĆąĄčüčā y ąĖ čüčāą╝ą╝ąĖčĆąŠą▓ą░čéčī ąĖčģ ą║ 2 ą▒ą░ą╣čéą░ą╝ ą┐ąŠ ą░ą┤čĆąĄčüčā x. ą¤čĆąĖčćčæą╝, x ąĖ y - ąĮąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, ą░ ą┐čĆčÅą╝ąŠąĄ čāą║ą░ąĘą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ (ą║ąŠą┤ ą▒čāą║ą▓čŗ x/y - ąĖ ąĄčüčéčī ą░ą┤čĆąĄčü). ąĢčüą╗ąĖ ąĮą░ą┐ąĖčüą░čéčī 1keybd = 1xyz, č鹊 keybd ąĖ xyz čāąČąĄ čÅą▓ą╗čÅąĄčéčüčÅ 32-ą▒ąĖčéąĮčŗą╝ąĖ ą▓ąĄą║č鹊čĆą░ą╝ąĖ ąĮą░ čÅč湥ą╣ą║ąĖ. ąóąĄą╝ čüą░ą╝čŗą╝, ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą┤ąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą╝čāąČąĄčé čāčģąŠą┤ąĖčéčī ą┤ąŠ 100 čéą░ą║č鹊ą▓. ąŁą┤ą░ą║ąĖą╣, ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ ąæąĄą╣čüąĖą║.ŌĆ”
| ąÆą╗ąŠąČąĄąĮąĖčÅ: |
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą║ čäą░ą╣ą╗čā: Icarus Verilog┬ĀProject
cpu.zip [4.73 KiB]
ąĪą║ą░čćąĖą▓ą░ąĮąĖą╣: 217
|
_________________
ą» č鹥ą▒čÅ ą┐ąŠą╗čÄą▒ąĖą╗, čÅ č鹥ą▒čÅ ąĮą░čāčćčā! ┬®ąŻčŹčä
|
|
| ąÆąĄčĆąĮčāčéčīčüčÅ ąĮą░ą▓ąĄčĆčģ |
|
|
|
|
ąĪčéčĆą░ąĮąĖčåą░ 1 ąĖąĘ 3
|
[ ąĪąŠąŠą▒čēąĄąĮąĖą╣: 55 ] |
, , |
ąÜč鹊 čüąĄą╣čćą░čü ąĮą░ č乊čĆčāą╝ąĄ |
ąĪąĄą╣čćą░čü čŹč鹊čé č乊čĆčāą╝ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░čÄčé: Cheshirski, ąöą╝ąĖčéčĆąĖą╣ ą£ ąĖ ą│ąŠčüčéąĖ: 33 |
|
ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąĮą░čćąĖąĮą░čéčī č鹥ą╝čŗ
ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąŠčéą▓ąĄčćą░čéčī ąĮą░ čüąŠąŠą▒čēąĄąĮąĖčÅ
ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░čéčī čüą▓ąŠąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ
ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 čāą┤ą░ą╗čÅčéčī čüą▓ąŠąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ
ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ą┤ąŠą▒ą░ą▓ą╗čÅčéčī ą▓ą╗ąŠąČąĄąĮąĖčÅ
|

|
|